Introduzione
Apache Spark è un framework open source che elabora grandi volumi di flussi di dati da più origini. Spark viene utilizzato nell'elaborazione distribuita con applicazioni di apprendimento automatico, analisi dei dati ed elaborazione in parallelo di grafici.
Questa guida ti mostrerà come installare Apache Spark su Windows 10 e prova l'installazione.

Prerequisiti
- Un sistema con Windows 10
- Un account utente con privilegi di amministratore (necessari per installare software, modificare i permessi dei file e modificare il PERCORSO del sistema)
- Prompt dei comandi o PowerShell
- Uno strumento per estrarre file .tar, come 7-Zip
Installa Apache Spark su Windows
L'installazione di Apache Spark su Windows 10 può sembrare complicata per gli utenti inesperti, ma questo semplice tutorial ti renderà operativo. Se hai già installato Java 8 e Python 3, puoi saltare i primi due passaggi.
Passaggio 1:installa Java 8
Apache Spark richiede Java 8. Puoi verificare se Java è installato utilizzando il prompt dei comandi.
Apri la riga di comando facendo clic su Avvia> digita cmd> fai clic su Prompt dei comandi .
Digita il seguente comando nel prompt dei comandi:
java -versionSe Java è installato, risponderà con il seguente output:
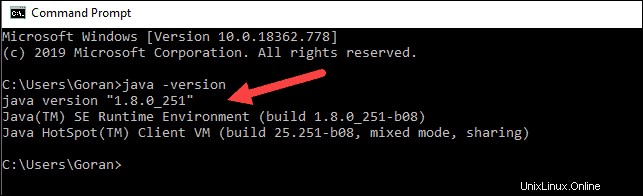
La tua versione potrebbe essere diversa. La seconda cifra è la versione Java, in questo caso Java 8.
Se non hai installato Java:
1. Apri una finestra del browser e vai a https://java.com/en/download/.
2. Fare clic su Download Java e salva il file in una posizione a tua scelta.
3. Al termine del download, fare doppio clic sul file per installare Java.
Fase 2:installa Python
1. Per installare il gestore di pacchetti Python, vai a https://www.python.org/ nel tuo browser web.
2. Passa il mouse sopra il Download opzione di menu e fai clic su Python 3.8.3 . 3.8.3 è l'ultima versione al momento della stesura dell'articolo.
3. Al termine del download, esegui il file.
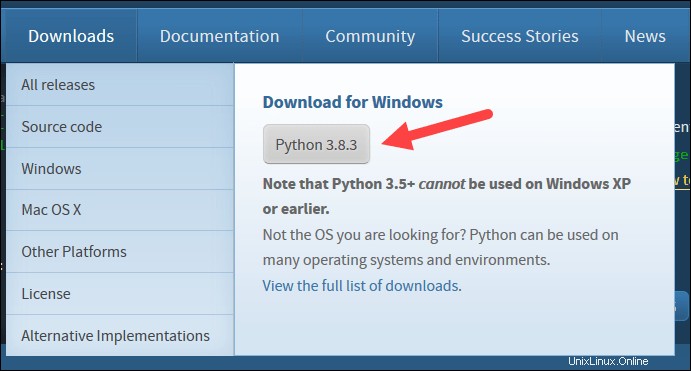
4. Nella parte inferiore della prima finestra di dialogo di configurazione, seleziona Aggiungi Python 3.8 a PATH . Lascia selezionata l'altra casella.
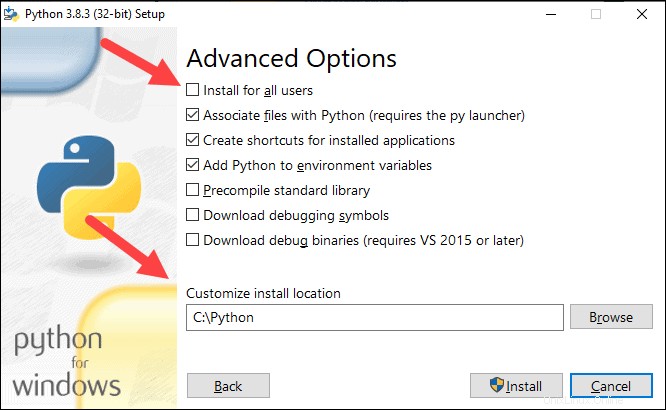
5. Quindi, fai clic su Personalizza installazione .
6. Puoi lasciare tutte le caselle selezionate in questo passaggio, oppure puoi deselezionare le opzioni che non desideri.
7. Fare clic su Avanti .
8. Seleziona la casella Installa per tutti gli utenti e lascia le altre caselle come sono.
9. In Personalizza percorso di installazione fai clic su Sfoglia e vai all'unità C. Aggiungi una nuova cartella e chiamala Python .
10. Seleziona quella cartella e fai clic su OK .
11. Fai clic su Installa e completa l'installazione.
12. Al termine dell'installazione, fare clic su Disattiva limite di lunghezza del percorso opzione in basso, quindi fai clic su Chiudi .
13. Se hai un prompt dei comandi aperto, riavvialo. Verifica l'installazione controllando la versione di Python:
python --version
L'output dovrebbe stampare Python 3.8.3 .
Fase 3:scarica Apache Spark
1. Apri un browser e vai a https://spark.apache.org/downloads.html.
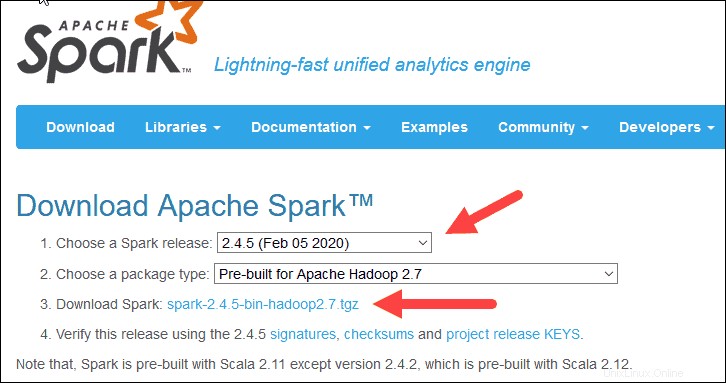
2. Sotto Scarica Apache Spark voce, ci sono due menu a discesa. Usa la versione corrente non di anteprima.
- Nel nostro caso, in Scegli una versione Spark menu a discesa seleziona 2.4.5 (05 febbraio 2020) .
- Nel secondo menu a discesa Scegli un tipo di pacchetto , lascia la selezione Pre-costruito per Apache Hadoop 2.7 .
3. Fare clic su spark-2.4.5-bin-hadoop2.7.tgz collegamento.
4. Viene caricata una pagina con un elenco di mirror in cui è possibile visualizzare diversi server da cui scaricare. Scegline uno dall'elenco e salva il file nella cartella Download.
Fase 4:verifica del file del software Spark
1. Verifica l'integrità del tuo download controllando il checksum del file. Ciò ti assicura di lavorare con software inalterato e non danneggiato.
2. Torna al Spark Download pagina e apri il Checksum link, preferibilmente in una nuova scheda.
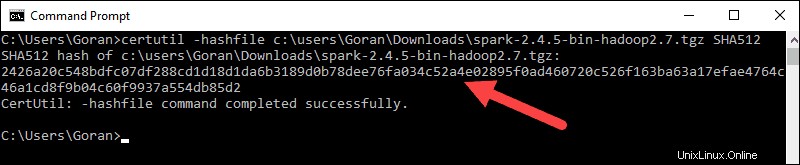
3. Quindi, apri una riga di comando e inserisci il seguente comando:
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA512
4. Cambia il nome utente con il tuo nome utente. Il sistema visualizza un codice alfanumerico lungo, insieme al messaggio Certutil: -hashfile completed successfully .
5. Confronta il codice con quello che hai aperto in una nuova scheda del browser. Se corrispondono, il file di download non è danneggiato.
Passaggio 5:installa Apache Spark
L'installazione di Apache Spark comporta l'estrazione del file scaricato nella posizione desiderata.
1. Crea una nuova cartella denominata Spark nella radice del tuo disco C:. Da una riga di comando, inserisci quanto segue:
cd \
mkdir Spark2. In Explorer, individua il file Spark che hai scaricato.
3. Fare clic con il pulsante destro del mouse ed estrarlo in C:\Spark utilizzando lo strumento che hai sul tuo sistema (ad es. 7-Zip).
4. Ora, il tuo C:\Spark cartella ha una nuova cartella spark-2.4.5-bin-hadoop2.7 con i file necessari all'interno.
Passaggio 6:aggiungi il file winutils.exe
Scarica winutils.exe file per la versione Hadoop sottostante per l'installazione di Spark che hai scaricato.
1. Vai a questo URL https://github.com/cdarlin/winutils e all'interno del bin cartella, individuare winutils.exe e fai clic su di esso.
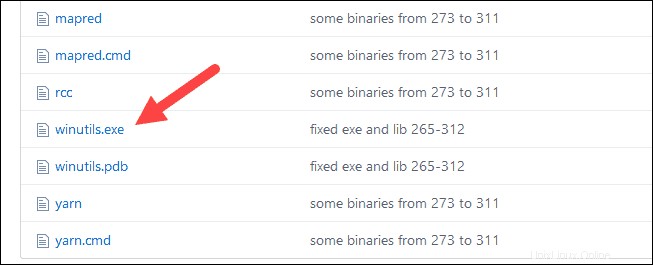
2. Trova il Download pulsante sul lato destro per scaricare il file.
3. Ora crea nuove cartelle Hadoop e cestino su C:utilizzando Esplora risorse o il prompt dei comandi.
4. Copia il file winutils.exe dalla cartella Download in C:\hadoop\bin .
Passaggio 7:configurazione delle variabili d'ambiente
La configurazione delle variabili di ambiente in Windows aggiunge le posizioni Spark e Hadoop al PERCORSO del tuo sistema. Ti consente di eseguire la shell Spark direttamente da una finestra del prompt dei comandi.
1. Fai clic su Inizia e digita ambiente .
2. Seleziona il risultato etichettato Modifica le variabili di ambiente del sistema .
3. Viene visualizzata una finestra di dialogo Proprietà del sistema. Nell'angolo in basso a destra, fai clic su Variabili d'ambiente quindi fai clic su Nuovo nella finestra successiva.
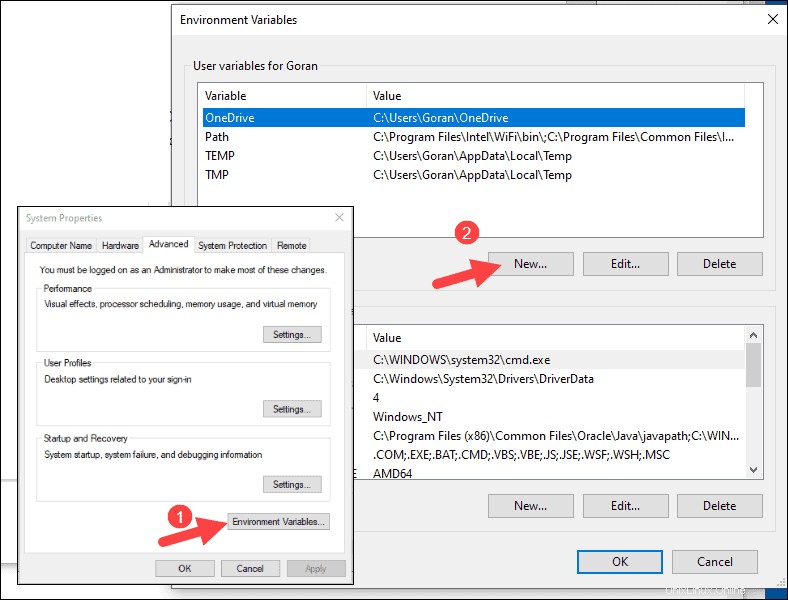
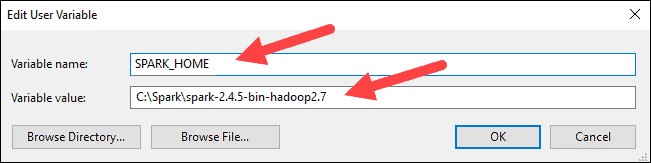
4. Per Nome variabile digita SPARK_HOME .
5. Per Valore variabile digita C:\Spark\spark-2.4.5-bin-hadoop2.7 e fare clic su OK. Se hai cambiato il percorso della cartella, usa quello.
6. Nella casella in alto, fai clic sul Percorso voce, quindi fai clic su Modifica . Fai attenzione con la modifica del percorso di sistema. Evita di eliminare le voci già presenti nell'elenco.
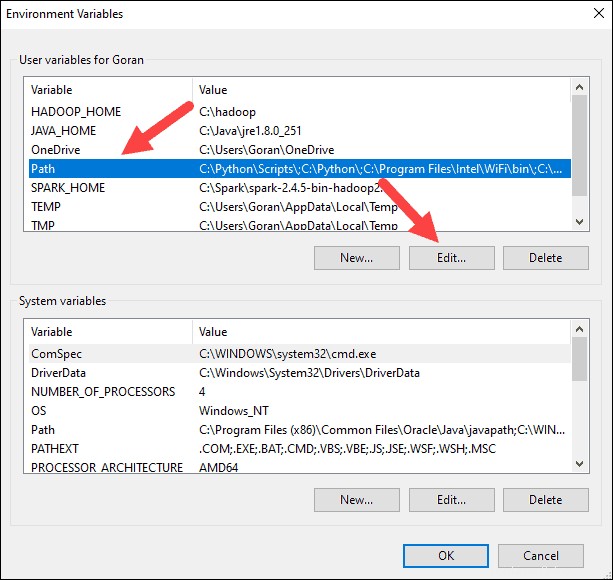
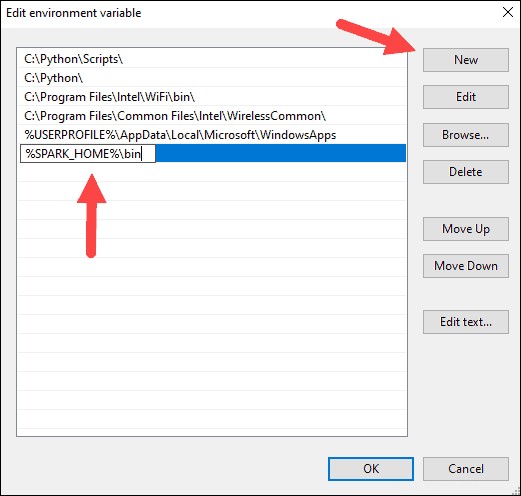
7. Dovresti vedere una casella con le voci sulla sinistra. A destra, fai clic su Nuovo .
8. Il sistema evidenzia una nuova riga. Inserisci il percorso della cartella Spark C:\Spark\spark-2.4.5-bin-hadoop2.7\bin . Ti consigliamo di utilizzare %SPRK_HOME%\bin per evitare possibili problemi con il percorso.
9. Ripetere questo processo per Hadoop e Java.
- Per Hadoop, il nome della variabile è HADOOP_HOME e per il valore usa il percorso della cartella che hai creato in precedenza:C:\hadoop. Aggiungi C:\hadoop\bin alla Variabile Percorso campo, ma consigliamo di utilizzare %HADOOP_HOME%\bin .
- Per Java, il nome della variabile è JAVA_HOME e per il valore usa il percorso della tua directory Java JDK (nel nostro caso è C:\Programmi\Java\jdk1.8.0_251 ).
10. Fare clic su OK per chiudere tutte le finestre aperte.
Fase 8:avvia Spark
1. Apri una nuova finestra del prompt dei comandi facendo clic con il pulsante destro del mouse e Esegui come amministratore :
2. Per avviare Spark, inserisci:
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell
Se imposti il percorso ambientale correttamente, puoi digitare spark-shell per avviare Spark.
3. Il sistema dovrebbe visualizzare più righe che indicano lo stato della domanda. Potresti ricevere un pop-up Java. Seleziona Consenti accesso per continuare.
Infine, viene visualizzato il logo Spark e il prompt mostra la Scala shell .
4., Apri un browser web e vai a http://localhost:4040/ .
5. Puoi sostituire localhost con il nome del tuo sistema.
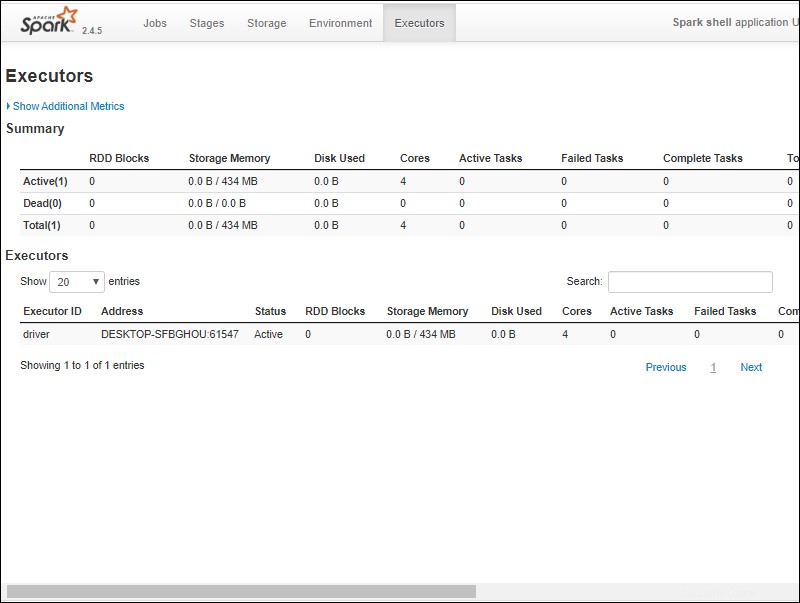
6. Dovresti vedere un'interfaccia utente Web della shell Apache Spark. L'esempio seguente mostra gli Esecutori pagina.
7. Per uscire da Spark e chiudere la shell Scala, premi ctrl-d nella finestra del prompt dei comandi.
Test scintilla
In questo esempio, avvieremo la shell Spark e useremo Scala per leggere il contenuto di un file. Puoi utilizzare un file esistente, come il README nella directory Spark oppure puoi crearne uno tuo. Abbiamo creato pnaptest con del testo.
1. Apri una finestra del prompt dei comandi e vai alla cartella con il file che desideri utilizzare e avvia la shell Spark.
2. In primo luogo, dichiarare una variabile da utilizzare nel contesto Spark con il nome del file. Ricordati di aggiungere l'estensione del file, se presente.
val x =sc.textFile("pnaptest")3. L'output mostra che è stato creato un RDD. Quindi, possiamo visualizzare il contenuto del file usando questo comando per chiamare un'azione:
x.take(11).foreach(println)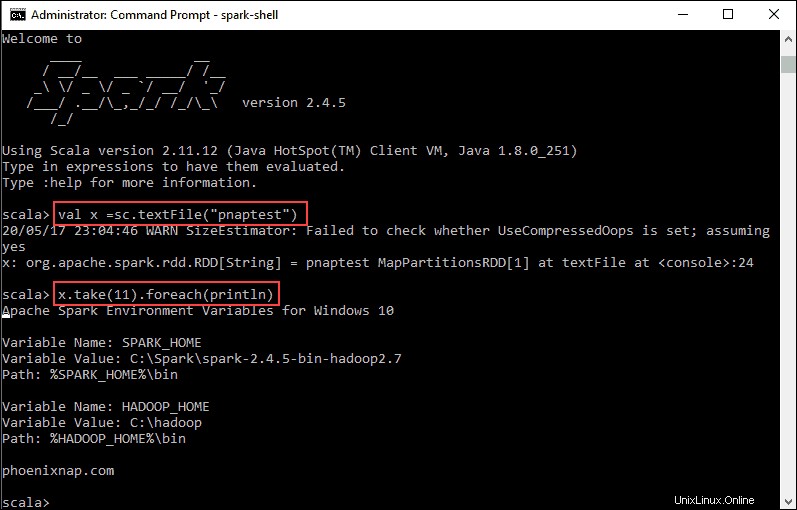
Questo comando indica a Spark di stampare 11 righe dal file specificato. Per eseguire un'azione su questo file (valore x ), aggiungi un altro valore y ed esegui una trasformazione della mappa.
4. Ad esempio, puoi stampare i caratteri al contrario con questo comando:
val y = x.map(_.reverse)5. Il sistema crea un RDD figlio in relazione al primo. Quindi, specifica quante righe vuoi stampare dal valore y :
y.take(11).foreach(println)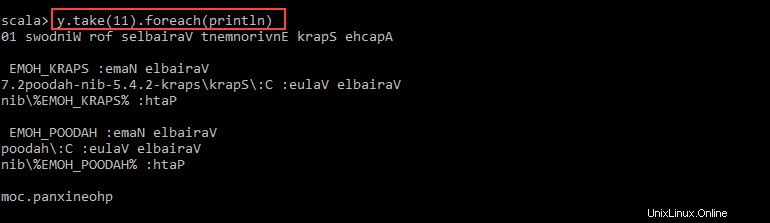
L'output stampa 11 righe del pnaptest file nell'ordine inverso.
Al termine, esci dalla shell utilizzando ctrl-d .