Introduzione
Cassandra è un software di database distribuito open source per la gestione di database NoSQL. Questo software utilizza CQL (Cassandra Query Language) come base per la comunicazione. CQL conserva i dati in tabelle disposte in un insieme di righe con colonne che contengono coppie chiave-valore.
Le tabelle CQL sono raggruppate in contenitori di dati chiamati keyspace in Cassandra. I dati archiviati in uno spazio delle chiavi non sono correlati ad altri dati nel cluster. Pertanto, puoi avere tabelle per più scopi diversi in spazi delle chiavi separati in un cluster e i dati non coincideranno.
In questa guida imparerai come creare una tabella Cassandra per diversi scopi e come modificare, eliminare o troncare le tabelle utilizzando la shell Cassandra.

Prerequisiti
- Software di database Cassandra installato sul tuo sistema
- Accesso a un terminale o a uno strumento da riga di comando per caricare cqlsh
- Un utente con le autorizzazioni necessarie per eseguire i comandi
Selezione dello spazio chiave per il tavolo Cassandra
Prima di iniziare ad aggiungere una tabella, devi determinare lo spazio delle chiavi in cui desideri creare la tabella . Ci sono due opzioni per farlo.
Opzione 1:il comando USE
Esegui USE comando per selezionare uno spazio chiave a cui verranno applicati tutti i comandi. Per farlo, nella shell cqlsh digita:
USE keyspace_name;Quindi, puoi iniziare ad aggiungere tabelle.
Opzione 2:specifica il nome dello spazio chiave nella query
La seconda opzione consiste nello specificare il nome dello spazio delle chiavi nella query per la creazione della tabella. La prima parte del comando, prima dei nomi delle colonne e delle opzioni, è simile a questa:
CREATE TABLE keyspace_name.table_nameIn questo modo crei immediatamente una tabella nello spazio delle chiavi che hai definito.
Sintassi di base per la creazione di tabelle Cassandra
La creazione di tabelle utilizzando CQL è simile alle query SQL. In questa sezione, ti mostreremo la sintassi di base per la creazione di tabelle in Cassandra.
La sintassi di base per creare una tabella è la seguente:
CREATE TABLE tableName (
columnName1 dataType,
columnName2 dataType,
columnName2 datatype
PRIMARY KEY (columnName)
);
Facoltativamente, puoi definire proprietà e valori di tabella aggiuntivi utilizzando WITH :
WITH propertyName=propertyValue;Ad esempio, utilizzalo per definire come archiviare i dati su disco o se utilizzare la compressione.
Tipi di chiavi primarie Cassandra
Ogni tabella in Cassandra deve avere una chiave primaria, che rende unica una riga. Con le chiavi primarie, determini quale nodo memorizza i dati e come li partiziona.
Esistono due tipi di chiavi primarie:
- Chiave primaria semplice . Contiene solo un nome di colonna come chiave di partizione per determinare quali nodi memorizzeranno i dati.
- Chiave primaria composta. Utilizza una chiave di partizionamento e più colonne di clustering per definire dove archiviare i dati e come ordinarli su una partizione.
- Chiave di partizione composita. In questo caso, sono presenti diverse colonne che determinano dove archiviare i dati. In questo modo, puoi suddividere i dati in parti più piccole per distribuirli su più partizioni per evitare l'hotspot.
Come creare una tabella Cassandra
Le sezioni seguenti spiegano come creare tabelle con diversi tipi di chiavi primarie. Innanzitutto, seleziona uno spazio chiave in cui desideri creare una tabella. Nel nostro caso:
USE businesinfo;Ogni tabella contiene colonne e un tipo di dati Cassandra per ogni voce.
Crea tabella con chiave primaria semplice
Il primo esempio è una tabella di base con i fornitori. L'ID è univoco per ogni fornitore e fungerà da chiave primaria.
La query CQL ha il seguente aspetto:
CREATE TABLE suppliers (
supp_id int PRIMARY KEY,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
);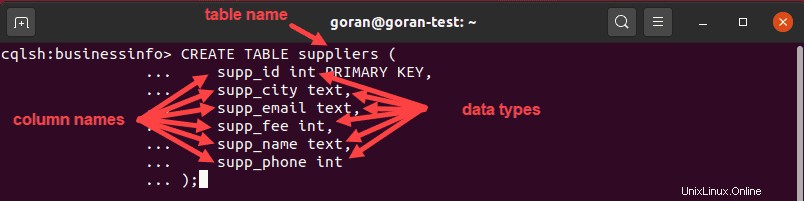
Questa query ha creato una tabella chiamata fornitore con supp_id come chiave primaria per la tabella. Quando utilizzi una semplice chiave primaria con il nome della colonna come chiave di partizione, puoi inserirla all'inizio della query (accanto alla colonna che fungerà da chiave primaria) o in fondo e quindi specificare il nome della colonna :
CREATE TABLE suppliers (
supp_id int,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
PRIMARY KEY(supp_id)
);Per vedere se la tabella è nello spazio delle chiavi, digita:
DESCRIBE TABLES;L'output elenca tutte le tabelle in quello spazio delle chiavi insieme a quella che hai creato.

Per visualizzare il contenuto delle tabelle, inserisci:
SELECT * FROM suppliers;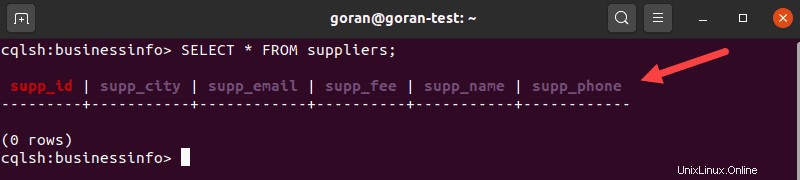
L'output mostra tutte le colonne definite durante la creazione di una tabella.
Un altro modo per vedere i dettagli di una tabella è usare DESCRIBE e specificare un nome di tabella:
DESCRIBE suppliers;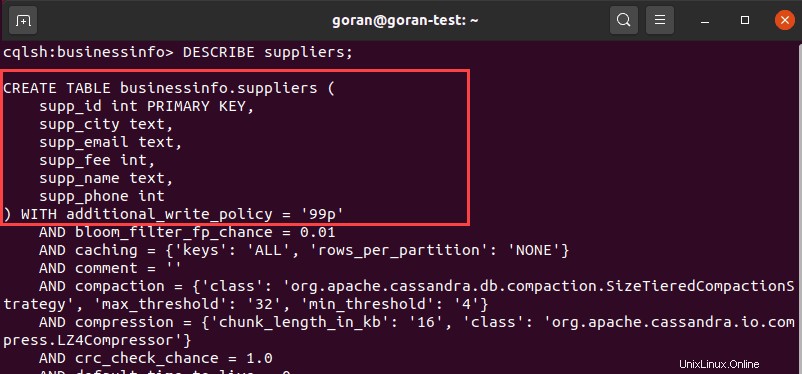
L'output mostra le colonne e le impostazioni predefinite per la tabella.
Crea tabella con chiave primaria composta
Per eseguire query e ottenere i risultati ordinati in un ordine specifico, crea una tabella con una chiave primaria composta.
Ad esempio, crea una tabella per i fornitori e tutti i prodotti che offrono. Poiché i prodotti potrebbero non essere univoci per ciascun fornitore, è necessario aggiungere una o più colonne di raggruppamento nella chiave primaria per renderla univoca.
Lo schema della tabella è simile al seguente:
CREATE TABLE suppliers_by_product (
supp_product text,
supp_id int,
supp_product_quantity text,
PRIMARY KEY(supp_product, supp_id)
);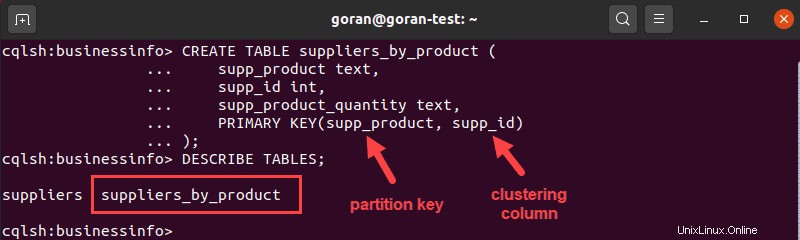
In questo caso, abbiamo utilizzato supp_product e supp_id per creare una chiave composta univoca. Qui, la prima voce nelle brackets supp_product è la chiave di partizione. Determina dove archiviare i dati, ovvero come il sistema partiziona i dati.
La voce successiva è la colonna di clustering che determina il modo in cui Cassandra ordina i dati, nel nostro caso si tratta di supp_id .
L'immagine sopra mostra che la tabella è stata creata correttamente. Per controllare i dettagli della tabella, eseguire il DESCRIBE TABLE query per la nuova tabella:
DESCRIBE TABLE suppliers_by_product;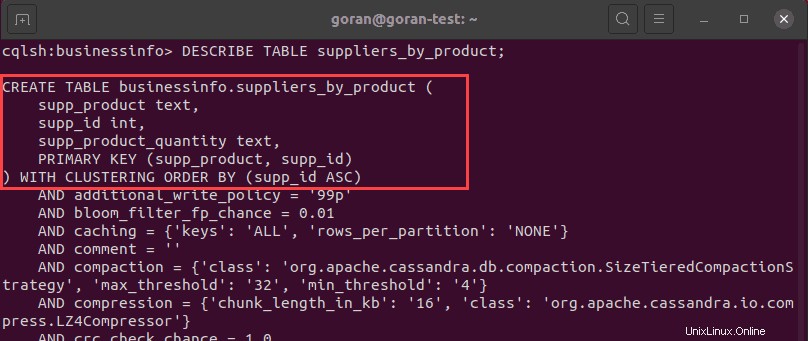
Le impostazioni predefinite per l'ordine di clustering sono ascendenti (ASC). Puoi passare a decrescente (DESC) aggiungendo la seguente istruzione dopo la chiave primaria:
WITH CLUSTERING ORDER BY (supp_id DESC);Abbiamo specificato una colonna di clustering dopo la chiave di partizione. Nel caso in cui sia necessario ordinare i dati utilizzando due colonne, aggiungere un'altra colonna all'interno delle parentesi della chiave primaria.
Crea tabelle utilizzando la chiave di partizione composita
La creazione di una tabella con una chiave di partizione composita è utile quando un nodo archivia un volume elevato di dati e si desidera suddividere il carico su più nodi.
In questo caso, definire una chiave primaria con una chiave di partizione composta da più colonne. Devi usare le doppie parentesi. Quindi, aggiungi le colonne di clustering come abbiamo fatto in precedenza per creare una chiave primaria univoca.
Ad esempio:
CREATE TABLE suppliers_by_product_type (
supp_product_consume text,
supp_product_stock text,
supp_id int,
supp_name text,
PRIMARY KEY((supp_product_consume, supp_product_stock), supp_id)
);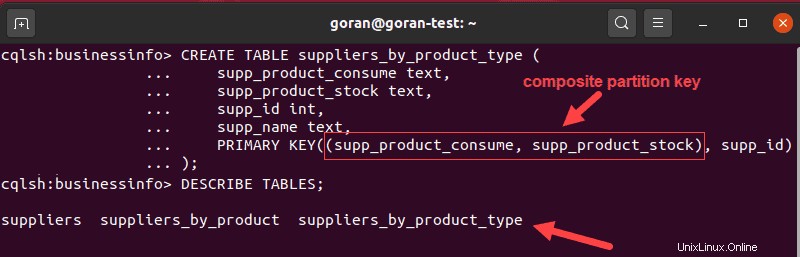
Nell'esempio sopra, abbiamo separato i dati in due categorie, prodotti di consumo del fornitore e prodotti stoccabili, e abbiamo distribuito i dati utilizzando una chiave di partizione composita.
Se invece utilizzi una chiave primaria composta con una chiave di partizione semplice e più colonne di clustering, un nodo gestirà tutti i dati ordinati in base a più colonne.
Tavolo basso Cassandra
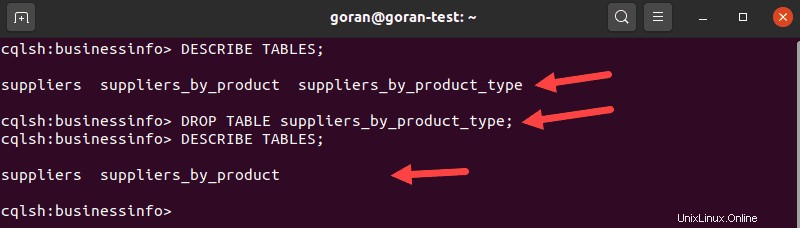
Per eliminare una tabella in Cassandra, utilizza il DROP TABLE dichiarazione. Per scegliere una tabella che desideri eliminare, inserisci:
DESCRIBE TABLES;Trova il tavolo che vuoi eliminare. Usa il nome della tabella per rimuoverla:
DROP TABLE suppliers_by_product_type;
Esegui il DESCRIBE TABLES interroga nuovamente per verificare che la tabella sia stata eliminata correttamente.
Tavolo Alter Cassandra
Cassandra CQL consente di aggiungere o rimuovere colonne da una tabella. Usa il ALTER TABLE comando per apportare modifiche a una tabella.
Aggiungi una colonna a una tabella
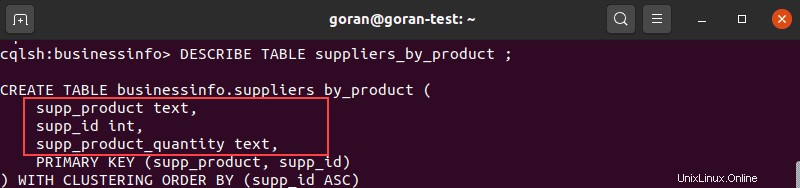
Prima di aggiungere una colonna a una tabella, ti consigliamo di visualizzare il contenuto della tabella per verificare che il nome della colonna non esista già.
Dopo aver verificato, utilizza il ALTER TABLE interrogare in questo formato per aggiungere una colonna:
ALTER TABLE suppliers_by_product
ADD supp_name text;Descrivi la tabella per confermare che la colonna appare nell'elenco.
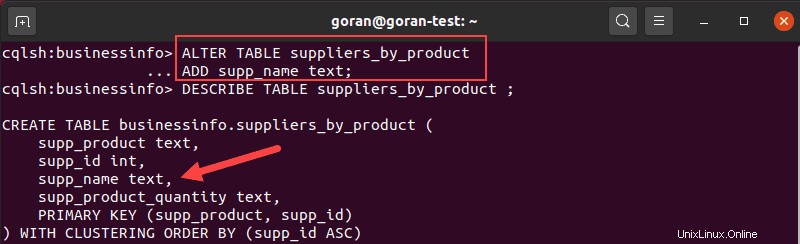
Elimina una colonna da una tabella
Simile all'aggiunta di una colonna, puoi eliminare una colonna da una tabella. Individua la colonna che desideri rimuovere utilizzando DESCRIBE TABLES interrogazione.
Quindi inserisci:
ALTER TABLE suppliers_by_product
DROP supp_product_quantity;Tavola tronca Cassandra
Se non vuoi eliminare un'intera tabella, ma devi rimuovere tutte le righe, utilizza il TRUNCATE comando.
Ad esempio, per eliminare tutte le righe dalla tabella fornitori , inserisci:
TRUNCATE suppliers;
Per verificare che non ci siano più righe nella tabella, utilizza il SELECT dichiarazione.
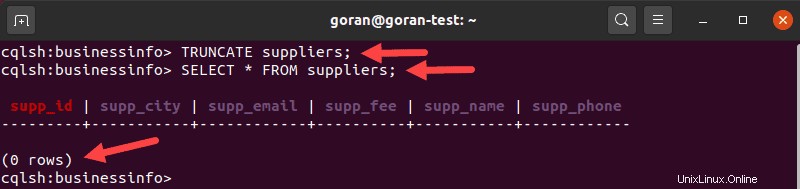
Dopo aver troncato una tabella, le modifiche sono permanenti, quindi fai attenzione quando usi questa query.