
In questo tutorial, ti mostreremo come installare Apache Spark su Debian 10. Per chi non lo sapesse, Apache Spark è un sistema di cluster computing veloce e generico. Fornisce API di alto livello in Java, Scala e Python e anche un motore ottimizzato che supporta i grafici di esecuzione complessivi Supporta anche un ricco set di strumenti di livello superiore tra cui Spark SQL per SQL ed elaborazione di informazioni strutturate, MLlib per l'apprendimento automatico , GraphX per l'elaborazione dei grafici e Spark Streaming.
Questo articolo presuppone che tu abbia almeno una conoscenza di base di Linux, sappia come usare la shell e, soprattutto, che ospiti il tuo sito sul tuo VPS. L'installazione è abbastanza semplice e presuppone che tu sono in esecuzione nell'account root, in caso contrario potrebbe essere necessario aggiungere 'sudo ' ai comandi per ottenere i privilegi di root. Ti mostrerò l'installazione passo passo di Apache Spark su una Debian 10 (Buster).
Prerequisiti
- Un server che esegue uno dei seguenti sistemi operativi:Debian 10 (Buster).
- Si consiglia di utilizzare una nuova installazione del sistema operativo per prevenire potenziali problemi.
- Un
non-root sudo usero accedere all'root user. Ti consigliamo di agire comenon-root sudo user, tuttavia, poiché puoi danneggiare il tuo sistema se non stai attento quando agisci come root.
Installa Apache Spark su Debian 10 Buster
Passaggio 1. Prima di eseguire il tutorial di seguito, è importante assicurarsi che il sistema sia aggiornato eseguendo il seguente apt comandi nel terminale:
sudo apt update
Passaggio 2. Installazione di Java.
Apache Spark richiede Java per funzionare, assicuriamoci di avere Java installato sul nostro sistema Debian:
sudo apt install default-jdk
Verifica la versione Java usando il comando:
java -version
Passaggio 3. Installazione di Scala.
Ora installiamo il pacchetto Scala sui sistemi Debian:
sudo apt install scala
Controlla la versione di Scala:
scala -version
Passaggio 4. Installazione di Apache Spark su Debian.
Ora possiamo scaricare il binario Apache Spark:
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
Quindi, estrai il tarball di Spark:
tar xvf spark-3.1.1-bin-hadoop2.7.tgz sudo mv spark-3.1.1-bin-hadoop2.7/ /opt/spark
Al termine, imposta l'ambiente Spark:
nano ~/.bashrc
Alla fine del file, aggiungi le seguenti righe:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Salva le modifiche e chiudi l'editor. Per applicare le modifiche esegui:
source ~/.bashrc
Ora avvia Apache Spark con questi comandi, uno dei quali è il master del cluster:
start-master.sh
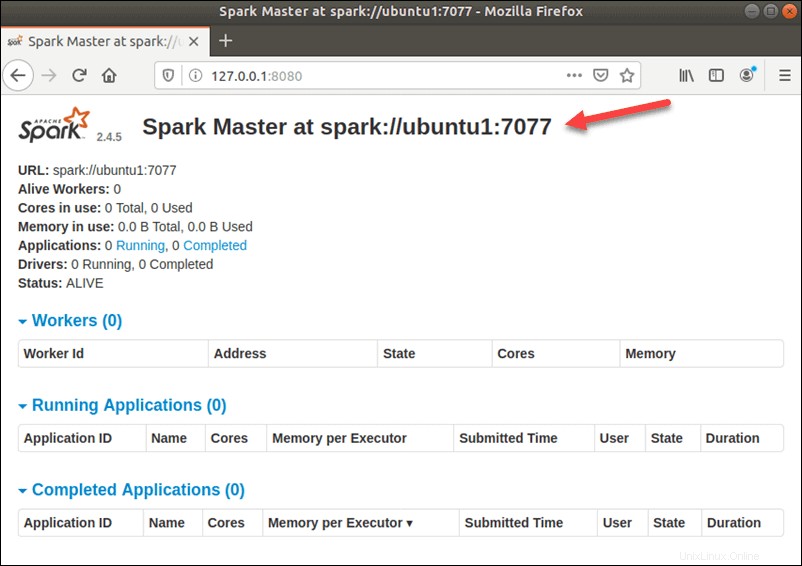
Per visualizzare l'interfaccia utente di Spark Web come di seguito, apri un browser Web e inserisci l'indirizzo IP dell'host locale sulla porta 8080:
http://127.0.0.1:8080/
In questa configurazione standalone a server singolo, avvieremo un server slave insieme al server master. Il start-slave.sh viene utilizzato un comando per avviare Spark Worker Process:
start-slave.sh spark://ubuntu1:7077
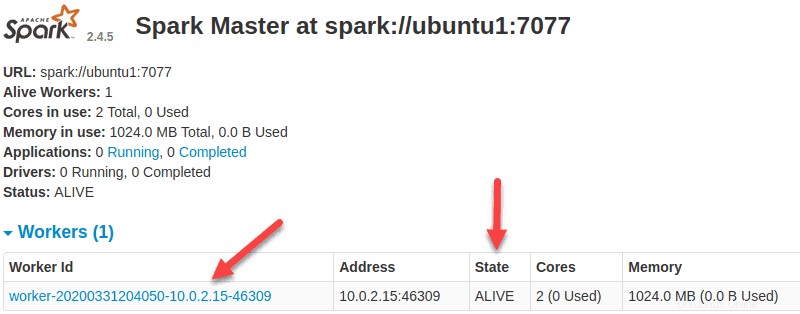
Ora che un lavoratore è attivo e funzionante, se ricarichi l'interfaccia utente Web di Spark Master, dovresti vederlo nell'elenco:
Una volta terminata la configurazione, avvia il server master e slave, verifica se la shell Spark funziona:
spark-shell
Congratulazioni! Hai installato con successo Spark. Grazie per aver utilizzato questo tutorial per installare l'ultima versione di Apache Spark sul sistema Debian. Per ulteriore aiuto o informazioni utili, ti consigliamo di controllare l'Apache ufficiale Sito Web Spark.