
In questo tutorial, ti mostreremo come installare Apache Hadoop su CentOS 7. Per chi non lo sapesse, Apache Hadoop è un framework software open source scritto in Java per archiviazione distribuita e processi di distribuzione, gestisce set di dati di dimensioni molto grandi distribuendoli tra cluster di computer Piuttosto che fare affidamento sull'hardware per fornire un'elevata disponibilità, la libreria stessa è progettata per rilevare e gestire i guasti a livello di applicazione, offrendo così un'elevata -servizio disponibile su un cluster di computer, ognuno dei quali potrebbe essere soggetto a guasti.
Questo articolo presuppone che tu abbia almeno una conoscenza di base di Linux, sappia come usare la shell e, soprattutto, che ospiti il tuo sito sul tuo VPS. L'installazione è abbastanza semplice. Lo farò mostrarti l'installazione passo passo di Apache Hadoop su CentOS 7.
Prerequisiti
- Un server che esegue uno dei seguenti sistemi operativi:CentOS 7.
- Si consiglia di utilizzare una nuova installazione del sistema operativo per evitare potenziali problemi.
- Accesso SSH al server (o semplicemente apri Terminal se sei su un desktop).
- Un
non-root sudo usero accedere all'root user. Ti consigliamo di agire comenon-root sudo user, tuttavia, poiché puoi danneggiare il tuo sistema se non stai attento quando agisci come root.
Installa Apache Hadoop su CentOS 7
Passaggio 1. Installa Java.
Dato che Hadoop è basato su java, assicurati di avere Java JDK installato sul sistema. Se non hai Java installato sul tuo sistema, usa il seguente link per installarlo prima.
- Installa Java JDK 8 su CentOS 7
root@idroot.us ~# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
Passaggio 2. Installa Apache Hadoop.
Si consiglia di creare un utente normale per configurare apache Hadoop, creare un utente utilizzando il seguente comando:
useradd hadoop passwd hadoop
Dopo aver creato un utente, è anche necessario impostare ssh basato su chiave sul proprio account. Per fare ciò, esegui i seguenti comandi:
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Scarica l'ultima versione stabile di Apache Hadoop, Al momento della stesura di questo articolo è la versione 2.7.0:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Passaggio 3. Configura Apache Hadoop.
Imposta le variabili di ambiente utilizzate da Hadoop. Modifica il file ~/.bashrc e aggiungi i seguenti valori alla fine del file:
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Applica variabili ambientali alla sessione attualmente in esecuzione:
source ~/.bashrc
Ora modifica $HADOOP_HOME/etc/hadoop/hadoop-env.sh file e imposta la variabile di ambiente JAVA_HOME:
export JAVA_HOME=/usr/jdk1.8.0_45/
Hadoop ha molti file di configurazione, che devono essere configurati secondo i requisiti della tua infrastruttura Hadoop. Iniziamo con la configurazione con una configurazione base del cluster Hadoop a nodo singolo:
cd $HADOOP_HOME/etc/hadoop
Modifica core-site.xml :
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Modifica hdfs-site.xml :
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value> </property> </configuration>
Modifica mapred-site.xml :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Modifica yarn-site.xml :
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Ora formatta namenode usando il seguente comando, non dimenticare di controllare la directory di archiviazione:
hdfs namenode -format
Avvia tutti i servizi Hadoop usa il seguente comando:
cd $HADOOP_HOME/sbin/ start-dfs.sh start-yarn.sh
Per verificare se tutti i servizi sono stati avviati correttamente usa 'jps ' comando:
jps
Passaggio 4. Accesso ad Apache Hadoop.
Apache Hadoop sarà disponibile sulla porta HTTP 8088 e 50070 per impostazione predefinita. Apri il tuo browser preferito e vai a http://your-domain.com:50070 o http://server-ip:50070 . Se stai utilizzando un firewall, apri le porte 8088 e 50070 per abilitare l'accesso al pannello di controllo.
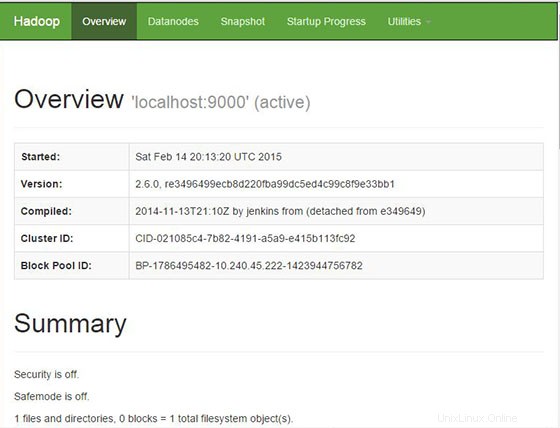
Ora accedi alla porta 8088 per ottenere le informazioni sul cluster e su tutte le applicazioni:
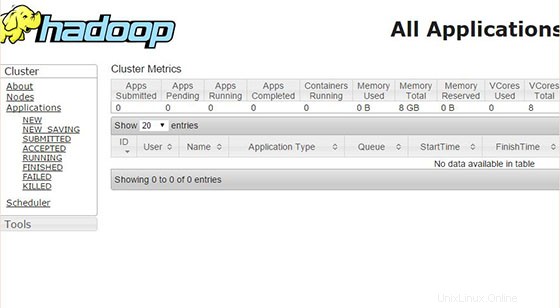
Congratulazioni! Hai installato con successo Apache Hadoop. Grazie per aver utilizzato questo tutorial per l'installazione di Apache Hadoop sul sistema CentOS 7. Per ulteriore aiuto o informazioni utili, ti consigliamo di controllare il sito Web ufficiale di Apache Hadoop.