
In questo tutorial, ti mostreremo come installare Apache Hadoop su Ubuntu 14.04. Per chi non lo sapesse, Apache Hadoop è un framework software open-source scritto in Java per processi di archiviazione e distribuzione distribuiti, gestisce una dimensione molto grande di set di dati distribuendoli tra i cluster di computer Piuttosto che fare affidamento sull'hardware per fornire un'elevata disponibilità, la libreria stessa è progettata per rilevare e gestire gli errori a livello di applicazione, fornendo così un servizio ad alta disponibilità su un cluster di computer, ognuno dei quali può essere soggetto a guasti.
Questo articolo presuppone che tu abbia almeno una conoscenza di base di Linux, sappia come usare la shell e, soprattutto, che ospiti il tuo sito sul tuo VPS. L'installazione è abbastanza semplice e presuppone che tu sono in esecuzione nell'account root, in caso contrario potrebbe essere necessario aggiungere 'sudo ' ai comandi per ottenere i privilegi di root. Ti mostrerò l'installazione passo passo di Apache Hadoop su Ubuntu 14.04. Puoi seguire le stesse istruzioni per qualsiasi altra distribuzione basata su Debian come Linux Mint.
Prerequisiti
- Un server che esegue uno dei seguenti sistemi operativi:Ubuntu 14.04.
- Si consiglia di utilizzare una nuova installazione del sistema operativo per prevenire potenziali problemi.
- Accesso SSH al server (o semplicemente apri Terminal se sei su un desktop).
- Un
non-root sudo usero accedere all'root user. Ti consigliamo di agire comenon-root sudo user, tuttavia, poiché puoi danneggiare il tuo sistema se non stai attento quando agisci come root.
Installa Apache Hadoop su Ubuntu 14.04
Passaggio 1. Installa Java (OpenJDK).
Dato che Hadoop è basato su java, assicurati di avere Java JDK installato sul sistema. Se non hai Java installato sul tuo sistema, usa il seguente link per installarlo prima.
- Installa Java JDK 8 su Ubuntu 14.04
root@idroot.us ~# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
Passaggio 2. Disabilitazione di IPv6.
Al momento Hadoop non supporta IPv6 ed è testato per funzionare solo su reti IPv4. Se stai usando IPv6, devi cambiare le macchine host Hadoop per usare IPv4 :
nano /etc/sysctl.conf
Aggiungi queste 3 righe alla fine del file:
#disable ipv6; net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1
Passaggio 3. Installa Apache Hadoop.
Per evitare problemi di sicurezza, consigliamo di configurare un nuovo gruppo di utenti Hadoop e un nuovo account utente per gestire tutte le attività relative a Hadoop, seguendo il comando:
sudo addgroup hadoopgroup sudo adduser —ingroup hadoopgroup hadoopuser
Dopo aver creato un utente, è anche necessario impostare ssh basato su chiave sul proprio account. Per fare ciò, esegui i seguenti comandi:
su - hadoopuser ssh-keygen -t rsa -P "" cat /home/hadoopuser/.ssh/id_rsa.pub >> /home/hadoopuser/.ssh/authorized_keys chmod 600 authorized_keys ssh-copy-id -i ~/.ssh/id_rsa.pub slave-1 ssh slave-1
Scarica l'ultima versione stabile di Apache Hadoop, Al momento della stesura di questo articolo è la versione 2.7.0:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Passaggio 4. Configura Apache Hadoop.
Imposta le variabili di ambiente Hadoop. Modifica ~/.bashrc file e aggiungi i seguenti valori alla fine del file:
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Applica variabili ambientali alla sessione attualmente in esecuzione:
source ~/.bashrc
Ora modifica $HADOOP_HOME/etc/hadoop/hadoop-env.sh file e imposta la variabile di ambiente JAVA_HOME:
export JAVA_HOME=/usr/jdk1.8.0_45/
Hadoop ha molti file di configurazione, che devono essere configurati secondo i requisiti della tua infrastruttura Hadoop. Cominciamo con la configurazione con la configurazione base del cluster Hadoop a nodo singolo:
cd $HADOOP_HOME/etc/hadoop
Modifica core-site.xml :
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration> Modifica hdfs-site.xml :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration> Modifica mapred-site.xml :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Modifica yarn-site.xml :
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> Ora formatta namenode usando il seguente comando, non dimenticare di controllare la directory di archiviazione:
hdfs namenode -format
Avvia tutti i servizi Hadoop usa il seguente comando:
cd $HADOOP_HOME/sbin/ start-dfs.sh start-yarn.sh
Dovresti osservare l'output per accertarti che tenti di avviare il nodo dati sui nodi slave uno per uno. Per verificare se tutti i servizi sono stati avviati correttamente usa 'jps ' comando:
jps
Passaggio 5. Accesso ad Apache Hadoop.
Apache Hadoop sarà disponibile sulla porta HTTP 8088 e 50070 per impostazione predefinita. Apri il tuo browser preferito e vai a http://your-domain.com:50070 o http://server-ip:50070 . Se stai usando un firewall, apri le porte 8088 e 50070 per abilitare l'accesso al pannello di controllo.
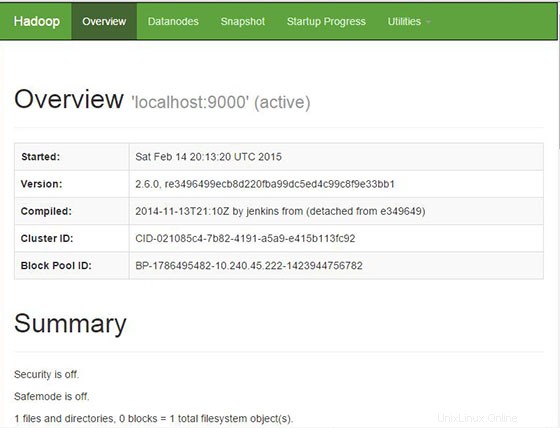
Sfoglia l'interfaccia web per ResourceManager per impostazione predefinita è disponibile su http://your-domain.com:8088 o http://server-ip:8088 :
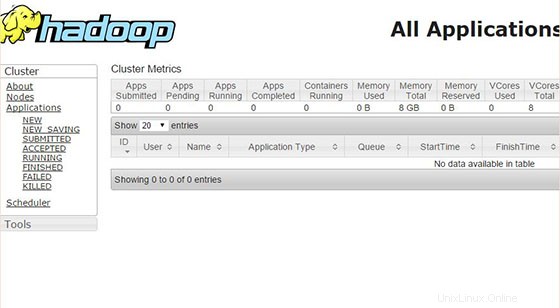
Congratulazioni! Hai installato con successo Apache Hadoop. Grazie per aver utilizzato questo tutorial per l'installazione di Apache Hadoop sul sistema Ubuntu 14.04. Per ulteriore aiuto o informazioni utili, ti consigliamo di controllare il sito Web ufficiale di Apache Hadoop.