Apache Spark è un framework computazionale distribuito open source creato per fornire risultati computazionali più veloci. È un motore di calcolo in memoria, il che significa che i dati verranno elaborati in memoria.
Scintilla supporta varie API per lo streaming, l'elaborazione di grafici, SQL, MLLib. Supporta anche Java, Python, Scala e R come linguaggi preferiti. Spark è installato principalmente nei cluster Hadoop, ma puoi anche installare e configurare spark in modalità standalone.
In questo articolo vedremo come installare Apache Spark in Debian e Ubuntu distribuzioni basate su.
Installa Java e Scala in Ubuntu
Per installare Apache Spark in Ubuntu, devi avere Java e Scala installato sulla tua macchina. La maggior parte delle moderne distribuzioni viene fornita con Java installato per impostazione predefinita e puoi verificarlo utilizzando il comando seguente.
$ java -version

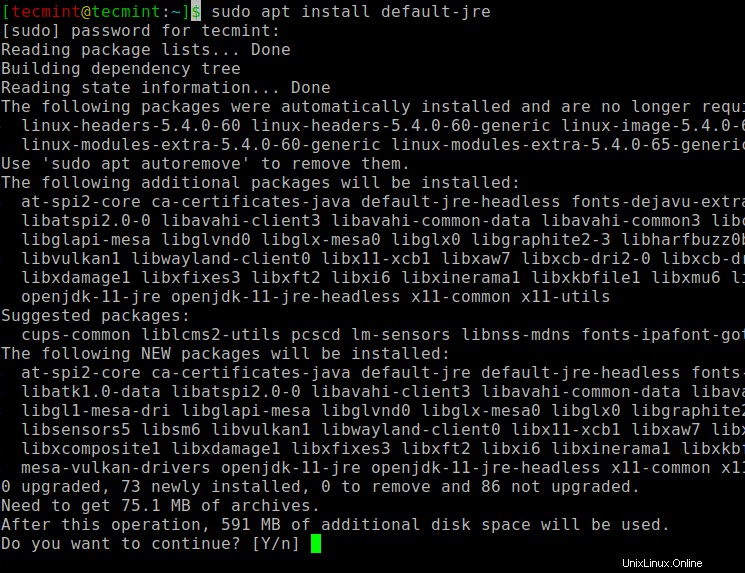
Se nessun output, puoi installare Java usando il nostro articolo su come installare Java su Ubuntu o semplicemente eseguire i seguenti comandi per installare Java su Ubuntu e distribuzioni basate su Debian.
$ sudo apt update $ sudo apt install default-jre $ java -version
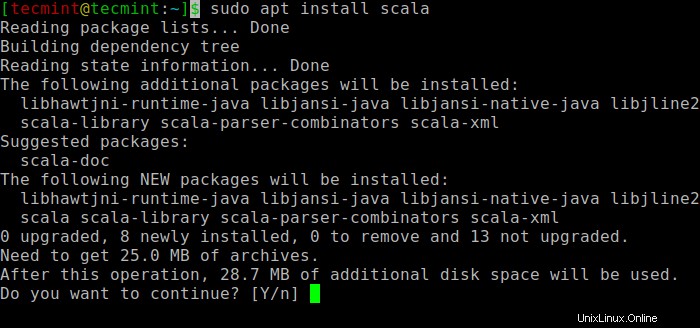
Successivamente, puoi installare Scala dal repository apt eseguendo i seguenti comandi per cercare scala e installarlo.
$ sudo apt search scala ⇒ Search for the package $ sudo apt install scala ⇒ Install the package
Per verificare l'installazione di Scala , esegui il comando seguente.
$ scala -version Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Installa Apache Spark in Ubuntu
Ora vai alla pagina di download ufficiale di Apache Spark e prendi l'ultima versione (cioè 3.1.1) al momento della stesura di questo articolo. In alternativa, puoi usare il comando wget per scaricare il file direttamente nel terminale.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
Ora apri il tuo terminale e passa alla posizione in cui si trova il tuo file scaricato ed esegui il seguente comando per estrarre il file tar di Apache Spark.
$ tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz
Infine, sposta la Spark estratta directory in /opt directory.
$ sudo mv spark-3.1.1-bin-hadoop2.7 /opt/spark
Configura variabili ambientali per Spark
Ora devi impostare alcune variabili ambientali nel tuo .profile file prima di avviare la scintilla.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile $ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile $ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
Per assicurarsi che queste nuove variabili di ambiente siano raggiungibili all'interno della shell e disponibili per Apache Spark, è anche obbligatorio eseguire il comando seguente per rendere effettive le modifiche recenti.
$ source ~/.profile
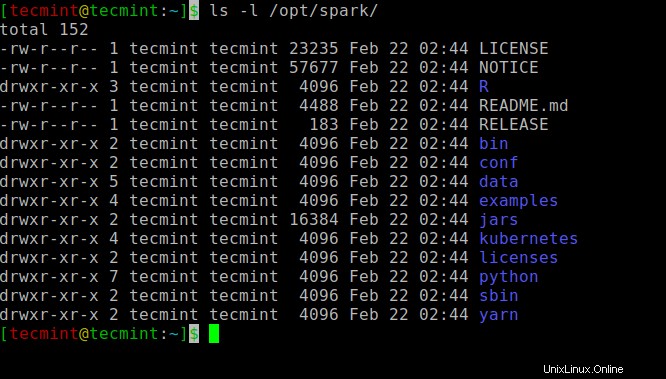
Tutti i binari relativi a spark per avviare e arrestare i servizi sono sotto sbin cartella.
$ ls -l /opt/spark
Avvia Apache Spark in Ubuntu
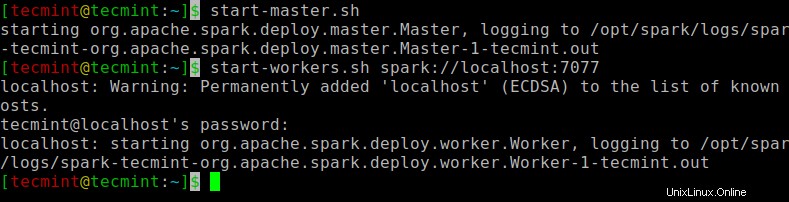
Esegui il comando seguente per avviare Spark servizio principale e servizio secondario.
$ start-master.sh $ start-workers.sh spark://localhost:7077
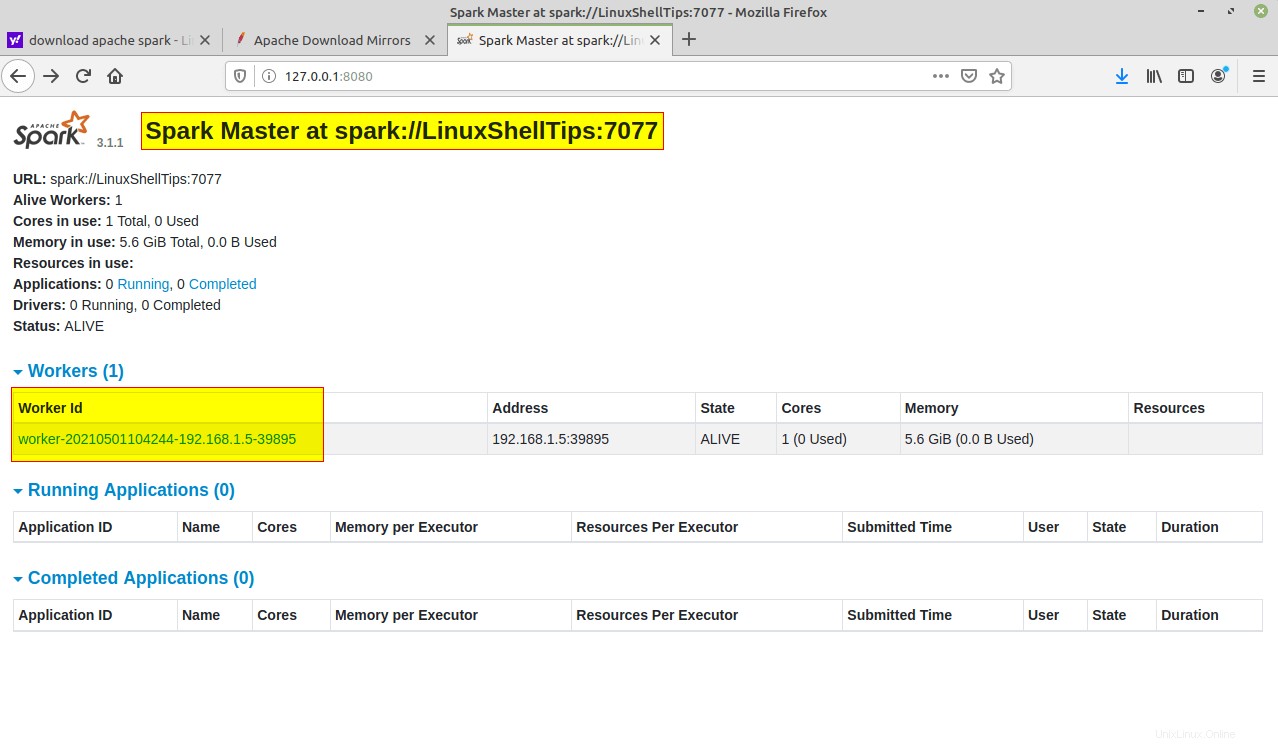
Una volta avviato il servizio, vai al browser e digita il seguente URL access spark page. Dalla pagina, puoi vedere che il mio servizio master e slave è iniziato.
http://localhost:8080/ OR http://127.0.0.1:8080
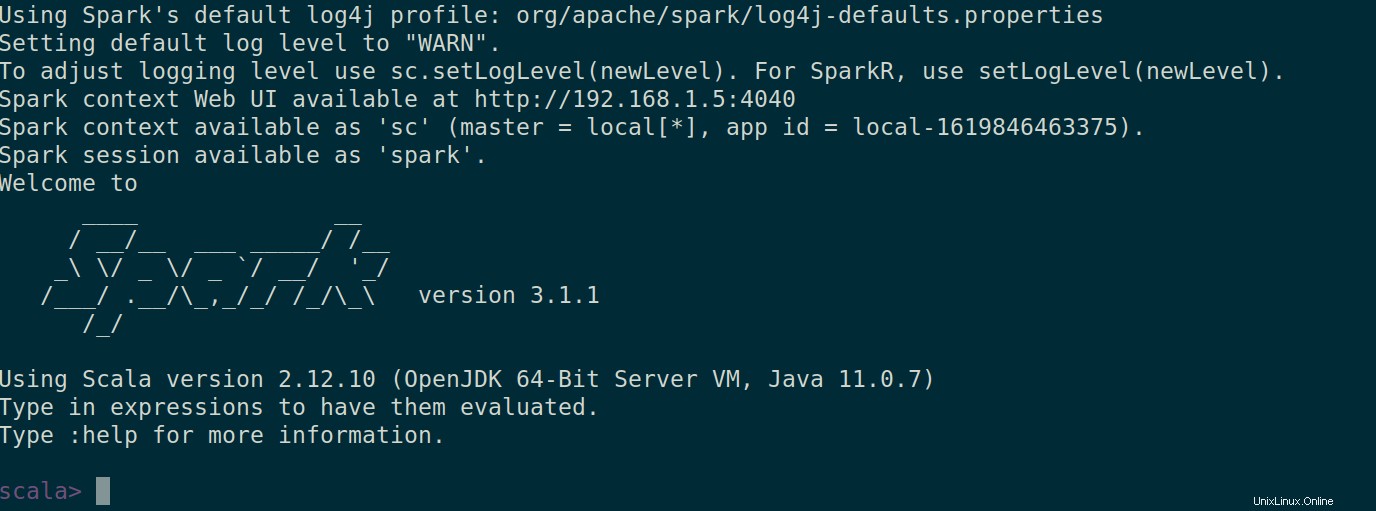
Puoi anche controllare se spark-shell funziona correttamente avviando spark-shell comando.
$ spark-shell
Questo è tutto per questo articolo. Ti sorprenderemo molto presto con un altro articolo interessante.