Introduzione
Apache Storm e Spark sono piattaforme per l'elaborazione di big data che funzionano con flussi di dati in tempo reale. La differenza fondamentale tra le due tecnologie sta nel modo in cui gestiscono l'elaborazione dei dati. Storm parallelizza il calcolo delle attività mentre Spark parallelizza i calcoli dei dati. Tuttavia, ci sono altre differenze di base tra le API.
Questo articolo fornisce un confronto approfondito tra Apache Storm e Spark Streaming.

Tempesta vs Scintilla:Definizioni
Apache Storm è un framework di elaborazione del flusso in tempo reale. Il Tridente il livello di astrazione fornisce a Storm un'interfaccia alternativa, aggiungendo operazioni di analisi in tempo reale.
D'altra parte, Apache Spark è un framework di analisi generico per dati su larga scala. L'API Spark Streaming è disponibile per lo streaming di dati quasi in tempo reale, insieme ad altri strumenti analitici all'interno del framework.
Tempesta vs Scintilla:confronto
Sia Storm che Spark sono progetti Apache gratuiti e open source con un intento simile. La tabella seguente delinea la principale differenza tra le due tecnologie:
| Tempesta | Spark | |
|---|---|---|
| Linguaggi di programmazione | Integrazione multilingue | Supporto per Python, R, Java, Scala |
| Modello di elaborazione | Elaborazione del flusso con micro-batching disponibile tramite Trident | Elaborazione batch con micro-batching disponibile tramite Streaming |
| Primitive | Flusso tupla Lotto tupla Partizione | DStream |
| Affidabilità | Esattamente una volta (Trident) Almeno una volta Al massimo una volta | Esattamente una volta |
| Tolleranza ai guasti | Riavvio automatico da parte del processo supervisore | Il lavoro viene riavviato tramite i gestori delle risorse |
| Gestione dello Stato | Supportato tramite Trident | Supportato tramite streaming |
| Facilità d'uso | Più difficile da utilizzare e distribuire | Più facile da gestire e distribuire |
Linguaggi di programmazione
La disponibilità dell'integrazione con altri linguaggi di programmazione è uno dei fattori principali nella scelta tra Storm e Spark e una delle principali differenze tra le due tecnologie.
Tempesta
Storm ha un multilingua caratteristica, rendendolo disponibile praticamente per qualsiasi linguaggio di programmazione. L'API Trident per lo streaming e l'elaborazione è compatibile con:
- Java
- Clojure
- Scala
Scintilla
Spark fornisce API di streaming di alto livello per le seguenti lingue:
- Java
- Scala
- Pitone
Alcune funzionalità avanzate, come lo streaming da origini personalizzate, non sono disponibili per Python. Tuttavia, lo streaming da fonti esterne avanzate come Kafka o Kinesis è disponibile per tutte e tre le lingue.
Modello di elaborazione
Il modello di elaborazione definisce come viene attualizzato lo streaming dei dati. Le informazioni vengono trattate in uno dei seguenti modi:
- Un record alla volta.
- In batch discretizzati.
Tempesta
Il modello di elaborazione del core Storm opera direttamente su flussi di tuple, un record alla volta , rendendola una vera e propria tecnologia di streaming in tempo reale. L'API Trident aggiunge la possibilità di utilizzare micro-batch .
Scintilla
Il modello di elaborazione Spark divide i dati in batch , raggruppando i record prima dell'ulteriore elaborazione. L'API Spark Streaming offre la possibilità di dividere i dati in micro-batch .
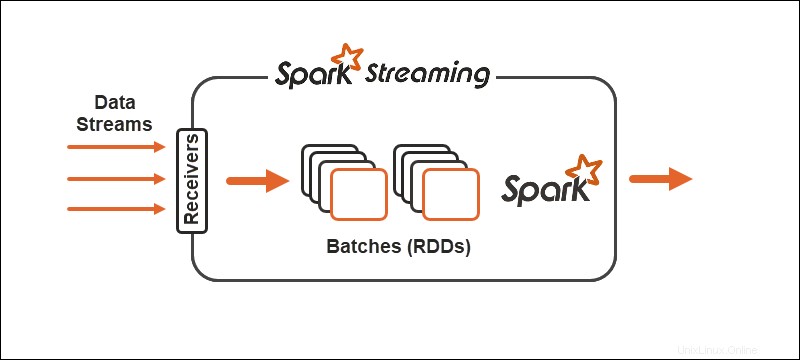
Primitive
Le primitive rappresentano gli elementi costitutivi di base di entrambe le tecnologie e il modo in cui le operazioni di trasformazione vengono eseguite sui dati.
Tempesta
Core Storm opera su stream tuple , mentre Trident opera su batch di tuple e partizioni . L'API Trident funziona sulle raccolte in modo simile, paragonabile alle astrazioni di alto livello per Hadoop. Le principali primitive di Storm sono:
- Bocconcini che generano un flusso in tempo reale da una sorgente.
- Bulloni che eseguono l'elaborazione dei dati e mantengono la persistenza.
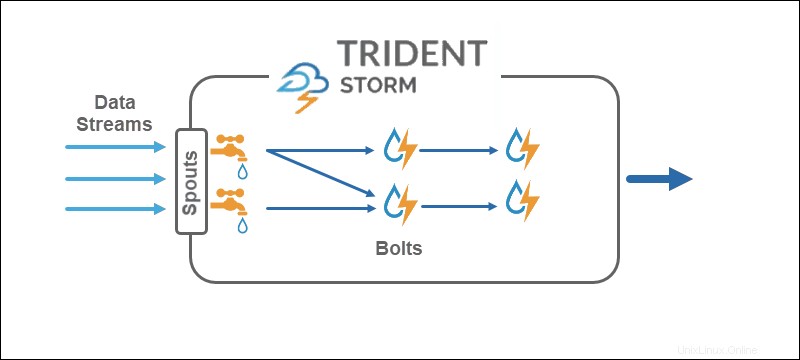
Nella topologia Trident, le operazioni si raggruppano in bulloni. Raggruppamenti, join, aggregazioni, funzioni di esecuzione e filtri sono disponibili in batch isolati e in raccolte diverse. L'aggregazione viene archiviata in modo persistente nella memoria supportata da HDFS o in qualche altro negozio come Cassandra.
Scintilla
Con Spark Streaming, il flusso continuo di dati si divide in stream discretizzati (DStreams), una sequenza di database distribuiti resilienti (RDD).
Spark consente due tipi generali di operatori sulle primitive:
1. Operatori di trasformazione del flusso dove un DStream si trasforma in un altro DStream.
2. Operatori di output aiuta a scrivere informazioni su sistemi esterni.
Affidabilità
L'affidabilità si riferisce alla garanzia della consegna dei dati. Ce ne sono tre possibili garanzie quando si ha a che fare con l'affidabilità dello streaming dei dati:
- Almeno una volta . I dati vengono consegnati una volta, con possibilità anche di consegne multiple.
- Al massimo una volta . I dati vengono consegnati solo una volta e tutti i duplicati vengono eliminati. Esiste la possibilità che i dati non arrivino.
- Esattamente una volta . I dati vengono consegnati una volta, senza perdite o duplicati. L'opzione di garanzia è ottimale per lo streaming di dati, anche se difficile da ottenere.
Tempesta
Storm è flessibile quando si tratta di affidabilità dello streaming di dati. Al suo interno, almeno una volta e al massimo una volta sono possibili opzioni. Insieme all'API Trident, sono disponibili tutte e tre le configurazioni .
Scintilla
Spark cerca di prendere la strada ottimale concentrandosi sul esattamente una volta configurazione del flusso di dati. Se un lavoratore o un autista fallisce, almeno una volta si applica la semantica.
Tolleranza ai guasti
La tolleranza ai guasti definisce il comportamento delle tecnologie di streaming in caso di guasto. Sia Spark che Storm sono tolleranti ai guasti a un livello simile.
Scintilla
In caso di errore dei lavoratori, Spark riavvia i lavoratori tramite il gestore delle risorse, come YARN. L'errore del driver utilizza un punto di controllo dei dati per il ripristino.
Tempesta
Se un processo non riesce in Storm o Trident, il processo di supervisione gestisce il riavvio automaticamente. ZooKeeper svolge un ruolo cruciale nel recupero e nella gestione dello stato.
Gestione dello Stato
Sia Spark Streaming che Storm Trident hanno tecnologie di gestione dello stato integrate. Il monitoraggio degli stati aiuta a raggiungere la tolleranza ai guasti e la garanzia di consegna esatta.
Facilità di utilizzo e sviluppo
La facilità d'uso e lo sviluppo dipendono da quanto sia ben documentata la tecnologia e da quanto sia facile gestire i flussi.
Scintilla
Spark è più facile da implementare e sviluppare con le due tecnologie. Lo streaming è ben documentato e viene distribuito su cluster Spark. I lavori in streaming sono intercambiabili con i lavori batch.
Tempesta
Storm è un po' più complicato da configurare e sviluppare in quanto contiene una dipendenza dal cluster ZooKeeper. Il vantaggio quando si utilizza Storm è dovuto alla funzione multilingua.
Tempesta vs Scintilla:come scegliere?
La scelta tra Storm e Spark dipende dal progetto e dalle tecnologie disponibili. Uno dei fattori principali è il linguaggio di programmazione e le garanzie di affidabilità nella consegna dei dati.
Sebbene ci siano differenze tra i due flussi di dati e l'elaborazione, il percorso migliore da intraprendere è testare entrambe le tecnologie per vedere cosa funziona meglio per te e il flusso di dati a portata di mano.