Introduzione
Oggi abbiamo molte soluzioni gratuite per l'elaborazione di big data. Molte aziende offrono anche funzionalità aziendali specializzate a complemento delle piattaforme open source.
La tendenza è iniziata nel 1999 con lo sviluppo di Apache Lucene. Il framework divenne presto open-source e portò alla creazione di Hadoop. Due dei framework di elaborazione dei big data più diffusi oggi in uso sono open source:Apache Hadoop e Apache Spark.
C'è sempre una domanda su quale framework usare, Hadoop o Spark.
In questo articolo, scopri il differenze chiave tra Hadoop e Spark e quando dovresti sceglierne uno o l'altro o usarli insieme.

Nota :prima di immergerci nel confronto diretto tra Hadoop e Spark, daremo una breve occhiata a questi due framework.
Cos'è Hadoop?
Apache Hadoop è una piattaforma che gestisce set di dati di grandi dimensioni in modo distribuito. Il framework utilizza MapReduce per dividere i dati in blocchi e assegnare i blocchi ai nodi in un cluster. MapReduce elabora quindi i dati in parallelo su ciascun nodo per produrre un output univoco.
Ogni macchina in un cluster archivia ed elabora i dati. Hadoop archivia i dati su dischi utilizzando HDFS . Il software offre opzioni di scalabilità senza interruzioni. Puoi iniziare con un minimo di una macchina e poi espanderti a migliaia, aggiungendo qualsiasi tipo di hardware aziendale o di consumo.
L'ecosistema Hadoop è altamente tollerante ai guasti. Hadoop non dipende dall'hardware per ottenere un'elevata disponibilità. Fondamentalmente, Hadoop è progettato per cercare errori a livello di applicazione. Replicando i dati su un cluster, quando un componente hardware si guasta, il framework può creare le parti mancanti da un'altra posizione.
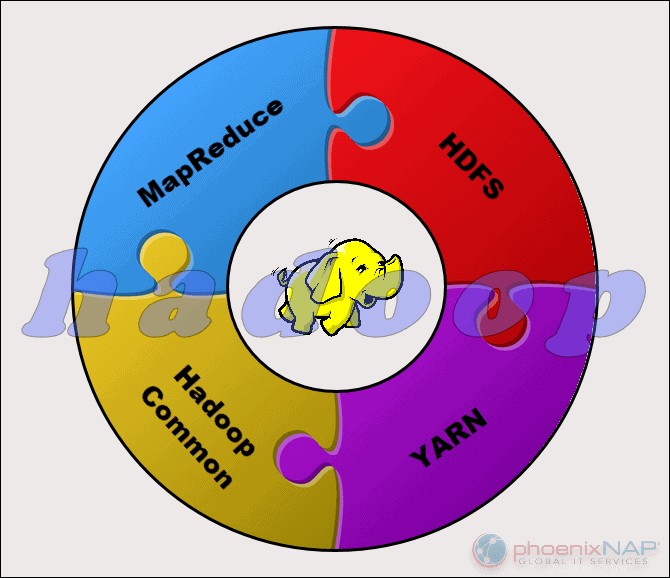
Il progetto Apache Hadoop è composto da quattro moduli principali:
- HDFS – File system distribuito Hadoop. Questo è il file system che gestisce l'archiviazione di grandi insiemi di dati in un cluster Hadoop. HDFS può gestire sia dati strutturati che non strutturati. L'hardware di archiviazione può variare da qualsiasi HDD di livello consumer a unità aziendali.
- Riduci mappa. Il componente di elaborazione dell'ecosistema Hadoop. Assegna i frammenti di dati dall'HDFS per separare le attività di mappa nel cluster. MapReduce elabora i pezzi in parallelo per combinare i pezzi nel risultato desiderato.
- FILO. Ancora un altro negoziatore di risorse. Responsabile della gestione delle risorse informatiche e della pianificazione dei lavori.
- Hadoop Comune. L'insieme di librerie e utilità comuni da cui dipendono altri moduli. Un altro nome per questo modulo è Hadoop core, poiché fornisce supporto per tutti gli altri componenti Hadoop.
La natura di Hadoop lo rende accessibile a tutti coloro che ne hanno bisogno. La comunità open source è ampia e ha aperto la strada all'elaborazione dei big data accessibile.
Cos'è Spark?
Apache Spark è uno strumento open source. Questo framework può essere eseguito in modalità standalone o su un cloud o un gestore di cluster come Apache Mesos e altre piattaforme. È progettato per prestazioni veloci e utilizza la RAM per la memorizzazione nella cache e l'elaborazione dei dati.
Spark esegue diversi tipi di carichi di lavoro di Big Data. Ciò include l'elaborazione batch simile a MapReduce, nonché l'elaborazione del flusso in tempo reale, l'apprendimento automatico, il calcolo dei grafici e le query interattive. Con API di alto livello facili da usare, Spark può integrarsi con molte librerie diverse, tra cui PyTorch e TensorFlow. Per conoscere la differenza tra queste due librerie, consulta il nostro articolo su PyTorch e TensorFlow.
Il motore Spark è stato creato per migliorare l'efficienza di MapReduce e mantenerne i vantaggi. Anche se Spark non ha il suo file system, può accedere ai dati su molte soluzioni di archiviazione diverse. La struttura di dati utilizzata da Spark è denominata Set di dati distribuito resiliente o RDD.
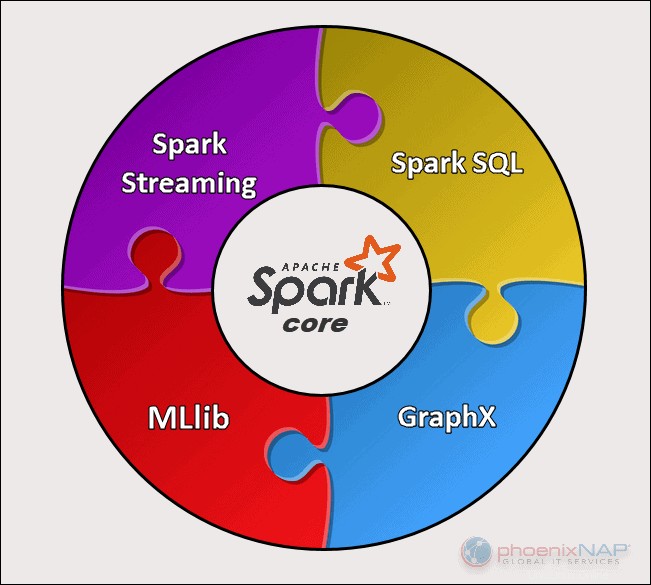
Esistono cinque componenti principali di Apache Spark:
- Apache Spark Core . La base dell'intero progetto. Spark Core è responsabile delle funzioni necessarie come la pianificazione, l'invio di attività, le operazioni di input e output, il ripristino degli errori, ecc. Altre funzionalità sono basate su di esso.
- Streaming scintillante. Questo componente consente l'elaborazione di flussi di dati in tempo reale. I dati possono provenire da molte fonti diverse, tra cui Kafka, Kinesis, Flume, ecc.
- Accendi SQL . Spark utilizza questo componente per raccogliere informazioni sui dati strutturati e su come vengono elaborati i dati.
- Libreria di apprendimento automatico (MLlib) . Questa libreria è composta da molti algoritmi di apprendimento automatico. L'obiettivo di MLlib è la scalabilità e rendere più accessibile l'apprendimento automatico.
- GraphX . Un insieme di API utilizzate per facilitare le attività di analisi dei grafici.
Differenze chiave tra Hadoop e Spark
Le sezioni seguenti delineano le principali differenze e somiglianze tra i due framework. Daremo un'occhiata a Hadoop vs. Spark da più angolazioni.
Alcuni di questi sono costo , rendimento , sicurezza e facilità d'uso .
La tabella seguente fornisce una panoramica delle conclusioni tratte nelle sezioni seguenti.
Confronto Hadoop e Spark
| Categoria per il confronto | Hadoop | Scintilla |
| Prestazioni | Prestazioni più lente, utilizza i dischi per l'archiviazione e dipende dalla velocità di lettura e scrittura del disco. | Prestazioni in memoria rapide con operazioni di lettura e scrittura su disco ridotte. |
| Costo | Una piattaforma open source, meno costosa da eseguire. Utilizza hardware di consumo a prezzi accessibili. È più facile trovare professionisti Hadoop formati. | Una piattaforma open source, ma si basa sulla memoria per il calcolo, che aumenta notevolmente i costi di gestione. |
| Trattamento dati | Ideale per l'elaborazione batch. Usa MapReduce per suddividere un set di dati di grandi dimensioni in un cluster per l'analisi parallela. | Adatto per l'analisi dei dati iterativa e live-stream. Funziona con RDD e DAG per eseguire operazioni. |
| Tolleranza ai guasti | Un sistema altamente tollerante ai guasti. Replica i dati tra i nodi e li usa in caso di problemi. | Tiene traccia del processo di creazione del blocco RDD e quindi può ricostruire un set di dati quando una partizione si guasta. Spark può anche utilizzare un DAG per ricostruire i dati tra i nodi. |
| Scalabilità | Facilmente scalabile aggiungendo nodi e dischi per l'archiviazione. Supporta decine di migliaia di nodi senza un limite noto. | Un po' più difficile da scalare perché si basa sulla RAM per i calcoli. Supporta migliaia di nodi in un cluster. |
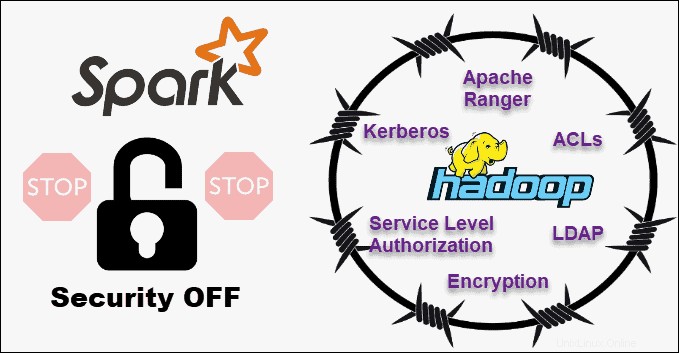
| Sicurezza | Estremamente sicuro. Supporta LDAP, ACL, Kerberos, SLA, ecc. | Non sicuro. Per impostazione predefinita, la sicurezza è disattivata. Si basa sull'integrazione con Hadoop per raggiungere il livello di sicurezza necessario. |
| Facilità d'uso e Assistenza linguistica | Più difficile da usare con lingue meno supportate. Utilizza Java o Python per le app MapReduce. | Più facile da usare. Consente la modalità shell interattiva. Le API possono essere scritte in Java, Scala, R, Python, Spark SQL. |
| Apprendimento automatico | Più lento di Spark. I frammenti di dati possono essere troppo grandi e creare colli di bottiglia. Mahout è la libreria principale. | Molto più veloce con l'elaborazione in memoria. Usa MLlib per i calcoli. |
| Pianificazione e gestione delle risorse | Utilizza soluzioni esterne. YARN è l'opzione più comune per la gestione delle risorse. Oozie è disponibile per la pianificazione del flusso di lavoro. | Ha strumenti integrati per l'allocazione, la pianificazione e il monitoraggio delle risorse. |
Prestazioni
Quando diamo un'occhiata a Hadoop vs. Spark in termini di come elaborano i dati , potrebbe non sembrare naturale confrontare le prestazioni dei due framework. Tuttavia, possiamo tracciare una linea e avere un'idea chiara di quale strumento è più veloce.
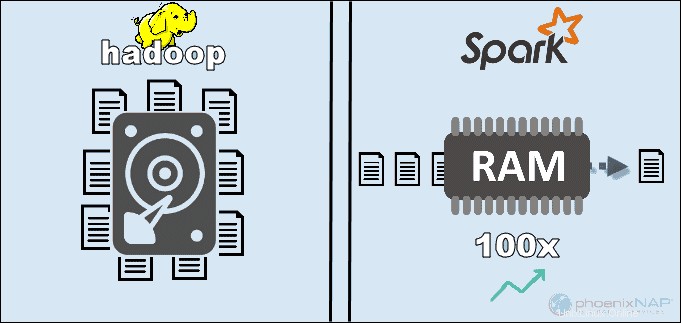
Accedendo ai dati archiviati localmente su HDFS, Hadoop migliora le prestazioni complessive. Tuttavia, non corrisponde all'elaborazione in memoria di Spark. Secondo le affermazioni di Apache, Spark sembra essere 100 volte più veloce quando si utilizza la RAM per l'elaborazione rispetto a Hadoop con MapReduce.
Il predominio è rimasto con l'ordinamento dei dati sui dischi. Spark era 3 volte più veloce e aveva bisogno di 10 volte meno nodi per elaborare 100 TB di dati su HDFS. Questo benchmark è stato sufficiente per stabilire il record mondiale nel 2014.
Il motivo principale di questa supremazia di Spark è che non legge e scrive dati intermedi sui dischi ma utilizza la RAM. Hadoop archivia i dati su molte fonti diverse e quindi elabora i dati in batch utilizzando MapReduce.
Tutto quanto sopra può posizionare Spark come vincitore assoluto. Tuttavia, se la dimensione dei dati è maggiore della RAM disponibile, Hadoop è la scelta più logica. Un altro punto da considerare è il costo di gestione di questi sistemi.
Costo
Confrontando Hadoop e Spark tenendo conto dei costi, dobbiamo scavare più a fondo del prezzo del software. Entrambe le piattaforme sono open source e completamente gratuito. Tuttavia, è necessario prendere in considerazione i costi di infrastruttura, manutenzione e sviluppo per ottenere un costo totale di proprietà (TCO) approssimativo.
Il fattore più significativo nella categoria dei costi è l'hardware sottostante necessario per eseguire questi strumenti. Poiché Hadoop si basa su qualsiasi tipo di archiviazione su disco per l'elaborazione dei dati, il costo di gestione è relativamente basso.
D'altra parte, Spark dipende dai calcoli in memoria per l'elaborazione dei dati in tempo reale. Quindi, girare nodi con molta RAM aumenta considerevolmente il costo di proprietà.
Un'altra preoccupazione è lo sviluppo dell'applicazione. Hadoop esiste da più tempo di Spark ed è meno difficile trovare sviluppatori di software.
I punti precedenti suggeriscono che l'infrastruttura Hadoop è più conveniente . Sebbene questa affermazione sia corretta, dobbiamo ricordare che Spark elabora i dati molto più velocemente. Quindi, richiede un numero minore di macchine per completare la stessa attività.
Trattamento dati
I due framework gestiscono i dati in modi abbastanza diversi . Sebbene sia Hadoop con MapReduce che Spark con RDD elabori i dati in un ambiente distribuito, Hadoop è più adatto per l'elaborazione batch. Al contrario, Spark brilla con l'elaborazione in tempo reale.
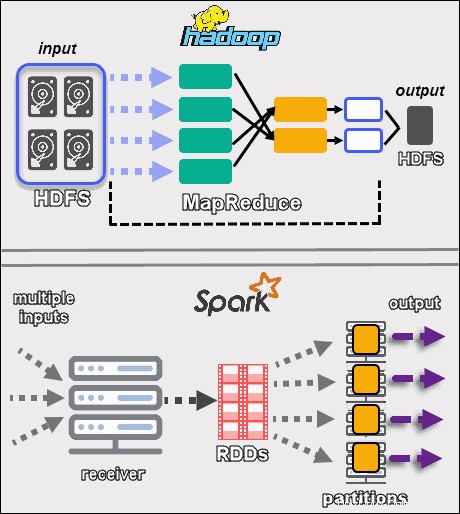
L'obiettivo di Hadoop è archiviare i dati su dischi e quindi analizzarli in parallelo in batch in un ambiente distribuito. MapReduce non richiede una grande quantità di RAM per gestire grandi volumi di dati. Hadoop si basa sull'hardware di tutti i giorni per l'archiviazione ed è più adatto per l'elaborazione lineare dei dati.
Apache Spark funziona conset di dati distribuiti resilienti (RDD ). Un RDD è un insieme distribuito di elementi archiviati in partizioni sui nodi del cluster. La dimensione di un RDD è solitamente troppo grande per essere gestita da un nodo. Pertanto, Spark partiziona gli RDD sui nodi più vicini ed esegue le operazioni in parallelo. Il sistema tiene traccia di tutte le azioni eseguite su un RDD mediante l'uso di un Grafico Aciclico Diretto (DAG ).
Con i calcoli in memoria e le API di alto livello, Spark gestisce efficacemente flussi live di dati non strutturati. Inoltre, i dati vengono archiviati in un numero predefinito di partizioni. Un nodo può avere tutte le partizioni necessarie, ma una partizione non può espandersi in un altro nodo.
Tolleranza ai guasti
Parlando di Hadoop vs. Spark nella categoria della tolleranza agli errori, possiamo dire che entrambi forniscono un livello rispettabile di gestione degli errori . Inoltre, possiamo dire che il modo in cui si avvicinano alla tolleranza agli errori è diverso.
Hadoop ha la tolleranza agli errori come base del suo funzionamento. Replica i dati molte volte tra i nodi. In caso di problemi, il sistema riprende il lavoro creando i blocchi mancanti da altre posizioni. I nodi master tengono traccia dello stato di tutti i nodi slave. Infine, se un nodo slave non risponde ai ping di un master, il master assegna i lavori in sospeso a un altro nodo slave.
Spark utilizza i blocchi RDD per ottenere la tolleranza agli errori. Il sistema tiene traccia di come viene creato il set di dati immutabile. Quindi, può riavviare il processo in caso di problemi. Spark può ricostruire i dati in un cluster utilizzando il monitoraggio DAG dei flussi di lavoro. Questa struttura di dati consente a Spark di gestire gli errori in un ecosistema di elaborazione dati distribuito.
Scalabilità
Il confine tra Hadoop e Spark diventa sfocato in questa sezione. Hadoop utilizza HDFS per gestire i big data. Quando il volume di dati cresce rapidamente, Hadoop può scalare rapidamente per soddisfare la domanda. Poiché Spark non ha il suo file system, deve fare affidamento su HDFS quando i dati sono troppo grandi per essere gestiti.
I cluster possono facilmente espandere e aumentare la potenza di calcolo aggiungendo più server alla rete. Di conseguenza, il numero di nodi in entrambi i framework può raggiungere migliaia. Non esiste un limite fisso al numero di server che puoi aggiungere a ciascun cluster e alla quantità di dati che puoi elaborare.
Alcuni dei numeri confermati includono 8000 macchine in un ambiente Spark con petabyte di dati. Quando si parla di cluster Hadoop, è noto che ospitano decine di migliaia di macchine e vicino a un exabyte di dati.
Facilità d'uso e supporto del linguaggio di programmazione
Spark potrebbe essere il framework più recente con meno esperti disponibili come Hadoop, ma è noto per essere più intuitivo. Al contrario, Spark fornisce supporto per più lingue accanto alla lingua madre (Scala):Java, Python, R e Spark SQL. Ciò consente agli sviluppatori di utilizzare il linguaggio di programmazione che preferiscono.
Il framework Hadoop è basato su Java . I due linguaggi principali per scrivere il codice MapReduce sono Java o Python. Hadoop non ha una modalità interattiva per aiutare gli utenti. Tuttavia, si integra con gli strumenti Pig e Hive per facilitare la scrittura di programmi MapReduce complessi.
Oltre al supporto per le API in più lingue, Spark vince nella sezione relativa alla facilità d'uso con la sua modalità interattiva. Puoi usare la shell Spark per analizzare i dati in modo interattivo con Scala o Python. La shell fornisce un feedback immediato alle query, il che rende Spark più facile da usare rispetto a Hadoop MapReduce.
Un'altra cosa che dà a Spark il sopravvento è che i programmatori possono riutilizzare il codice esistente ove applicabile. In questo modo, gli sviluppatori possono ridurre i tempi di sviluppo delle applicazioni. I dati storici e di streaming possono essere combinati per rendere questo processo ancora più efficace.
Sicurezza
Confrontando la sicurezza di Hadoop e Spark, faremo uscire subito il gatto dalla borsa:Hadoop è il chiaro vincitore . Soprattutto, la sicurezza di Spark è disattivata per impostazione predefinita. Ciò significa che la tua configurazione è esposta se non risolvi questo problema.
Puoi migliorare la sicurezza di Spark introducendo l'autenticazione tramite segreto condiviso o registrazione degli eventi. Tuttavia, ciò non è sufficiente per i carichi di lavoro di produzione.
Al contrario, Hadoop funziona con più metodi di autenticazione e controllo degli accessi. La più difficile da implementare è l'autenticazione Kerberos. Se Kerberos è troppo da gestire, Hadoop supporta anche Ranger , LDAP , ACL , crittografia tra nodi , autorizzazioni file standard su HDFS e Autorizzazione a livello di servizio .
Tuttavia, Spark può raggiungere un livello di sicurezza adeguato integrandosi con Hadoop . In questo modo, Spark può utilizzare tutti i metodi disponibili per Hadoop e HDFS. Inoltre, quando Spark viene eseguito su YARN, puoi adottare i vantaggi di altri metodi di autenticazione menzionati sopra.
Apprendimento automatico
L'apprendimento automatico è un processo iterativo che funziona al meglio utilizzando l'elaborazione in memoria. Per questo motivo, Spark si è rivelata una soluzione più rapida in quest'area.
Il motivo è che Hadoop MapReduce suddivide i lavori in attività parallele che potrebbero essere troppo grandi per gli algoritmi di apprendimento automatico. Questo processo crea problemi di prestazioni I/O in queste applicazioni Hadoop.
La libreria Mahout è la principale piattaforma di machine learning nei cluster Hadoop. Mahout si basa su MapReduce per eseguire il raggruppamento, la classificazione e la raccomandazione. Samsara ha iniziato a sostituire questo progetto.
Spark viene fornito con una libreria di machine learning predefinita, MLlib. Questa libreria esegue calcoli ML iterativi in memoria. Include strumenti per eseguire regressione, classificazione, persistenza, costruzione di pipeline, valutazione e molti altri.
Spark con MLlib si è rivelato nove volte più veloce di Apache Mahout in un ambiente basato su disco Hadoop. Quando hai bisogno di risultati più efficienti di quelli offerti da Hadoop, Spark è la scelta migliore per l'apprendimento automatico.
Pianificazione e gestione delle risorse
Hadoop non ha uno scheduler integrato. Utilizza soluzioni esterne per la gestione e la pianificazione delle risorse. Con ResourceManager e NodeManager , YARN è responsabile della gestione delle risorse in un cluster Hadoop. Uno degli strumenti disponibili per la pianificazione dei flussi di lavoro è Oozie.
YARN non si occupa della gestione statale delle singole applicazioni. Alloca solo la potenza di elaborazione disponibile.
Hadoop MapReduce funziona con plug-in come CapacityScheduler e FairScheduler . Questi schedulatori assicurano che le applicazioni ottengano le risorse essenziali necessarie, pur mantenendo l'efficienza di un cluster. Il FairScheduler fornisce le risorse necessarie alle applicazioni tenendo traccia del fatto che, alla fine, tutte le applicazioni ottengono la stessa allocazione di risorse.
Spark, d'altra parte, ha queste funzioni integrate. Il programma di pianificazione DAG è responsabile della suddivisione degli operatori in fasi. Ogni fase ha più attività che DAG pianifica e che Spark deve eseguire.
Spark Scheduler e Block Manager eseguono la pianificazione, il monitoraggio e la distribuzione delle risorse di lavori e attività in un cluster.
Usa casi di Hadoop contro Spark
Osservando Hadoop e Spark nelle sezioni sopra elencate, possiamo estrarre alcuni casi d'uso per ogni framework.
I casi d'uso di Hadoop includono:
- Elaborazione di set di dati di grandi dimensioni in ambienti in cui le dimensioni dei dati superano la memoria disponibile.
- Costruire un'infrastruttura di analisi dei dati con un budget limitato.
- Completare lavori in cui non sono richiesti risultati immediati e il tempo non è un fattore limitante.
- Elaborazione in batch con attività che sfruttano le operazioni di lettura e scrittura del disco.
- Analisi dei dati storici e di archivio.
Con Spark, possiamo separare i seguenti casi d'uso in cui supera Hadoop:
- L'analisi dei dati di flusso in tempo reale.
- Quando il tempo è essenziale, Spark offre risultati rapidi con calcoli in memoria.
- Gestire le catene di operazioni parallele utilizzando algoritmi iterativi.
- Elaborazione grafica parallela per modellare i dati.
- Tutte le applicazioni di apprendimento automatico.
Nota :Se hai preso la tua decisione, puoi seguire la nostra guida su come installare Hadoop su Ubuntu o come installare Spark su Ubuntu. Se stai lavorando in Windows 10, vedi Come installare Spark su Windows 10.
Hadoop o Spark?
Hadoop e Spark sono tecnologie per la gestione dei big data. A parte questo, sono strutture praticamente diverse nel modo in cui gestiscono ed elaborano i dati.
Secondo le sezioni precedenti di questo articolo, sembra che Spark sia il chiaro vincitore. Anche se questo può essere vero in una certa misura, in realtà non sono creati per competere tra loro, ma piuttosto per completarsi.
Naturalmente, come abbiamo elencato in precedenza in questo articolo, ci sono casi d'uso in cui l'uno o l'altro framework è una scelta più logica. Nella maggior parte delle altre applicazioni, Hadoop e Spark funzionano meglio insieme . Come successore, Spark non è qui per sostituire Hadoop, ma per utilizzare le sue funzionalità per creare un nuovo ecosistema migliorato.
Combinando i due, Spark può sfruttare le funzionalità che gli mancano, come un file system. Hadoop archivia un'enorme quantità di dati utilizzando hardware conveniente e successivamente esegue analisi, mentre Spark offre l'elaborazione in tempo reale per gestire i dati in entrata. Senza Hadoop, le applicazioni aziendali potrebbero perdere dati storici cruciali che Spark non gestisce.
In questo ambiente cooperativo, Spark sfrutta anche i vantaggi di sicurezza e gestione delle risorse di Hadoop. Con YARN, il clustering Spark e la gestione dei dati sono molto più semplici. Puoi eseguire automaticamente i carichi di lavoro Spark utilizzando qualsiasi risorsa disponibile.
Questa collaborazione fornisce i migliori risultati nell'analisi dei dati transazionali retroattivi, nell'analisi avanzata e nell'elaborazione dei dati IoT. Tutti questi casi d'uso sono possibili in un unico ambiente.
I creatori di Hadoop e Spark intendevano rendere le due piattaforme compatibili e produrre risultati ottimali adatto a qualsiasi esigenza aziendale.