Introduzione
Una delle maggiori minacce ai database moderni è la perdita di dati dovuta a guasti hardware o ransomware. I database distribuiti offrono una soluzione replicando i dati in diverse posizioni fisiche.
La replica del database consente di distribuire parti di un database su più nodi.
In questo tutorial illustreremo come funziona la replica dei dati, quando utilizzarla, diversi tipi e schemi di replica e strumenti che aiutano a replicare un database.

Che cos'è la replica del database?
Replica del database è il processo di copia dei dati e di archiviazione in posizioni diverse. L'esecuzione della replica dei dati garantisce una copia coerente del database su tutti i nodi di un sistema distribuito. Ciò serve a rendere i dati ampiamente disponibili e a proteggerli dalla perdita di dati.
I dati replicati possono essere completi o parziale snapshot e può essere archiviato in loco, fuori sede o in un ambiente cloud. In caso di downtime, le organizzazioni recuperano i dati e mantengono la continuità aziendale eseguendo il ripristino da una posizione di backup.
Nota: Il 90% delle aziende senza un piano di ripristino di emergenza chiude dopo una grave interruzione. Elimina questo rischio con le soluzioni di Disaster-Recovery-as-a-Service (DRaaS) leader del settore.
I dati vengono replicati in modo sincrono o in modo asincrono :
- Replica sincrona . I dati vengono scritti contemporaneamente nel database primario e in tutte le sue repliche.
- Replica asincrona . I dati vengono prima scritti nel database primario e poi copiati nelle repliche in un secondo momento.
Tipi di replica del database
Esistono diversi metodi per replicare un database. Le organizzazioni dovrebbero scegliere una tecnica basata sullo scopo dei dati replicati e su come intendono accedervi.
Replica snapshot
Replica istantanea copia uno "snapshot" del database, esattamente come appare nel momento in cui inizia il processo di replica. Non esegue il monitoraggio di modifiche o aggiornamenti ai dati.
La replica dello snapshot è utile quando i dati non cambiano frequentemente, ma anche se vengono apportate modifiche significative in un breve lasso di tempo. Qualsiasi modifica al database rende uno snapshot obsoleto fino a quando non ne viene replicato uno nuovo.
Replica transazionale
Replica transazionale crea una copia completa del database, con nuovi dati in arrivo man mano che il database cambia. I dati vengono copiati in tempo reale nell'ordine delle modifiche apportate, il che garantisce la coerenza.
È preferibile utilizzare la replica transazionale per garantire modifiche incrementali e in tempo reale ai dati. Ciò migliora le prestazioni e diminuisce la latenza fornendo al contempo un volume elevato di attività di lettura, scrittura ed eliminazione.
Unisci replica
Unire replica combina i dati da diverse fonti in un unico database. L'utilizzo della replica di tipo merge consente a più utenti di modificare i dati e di applicare tutte le modifiche alla nuova replica.
La replica di tipo merge consente di individuare e risolvere rapidamente le modifiche in conflitto. Consente inoltre agli utenti di apportare modifiche offline prima della sincronizzazione con il server.
Replica eterogenea
Replica eterogenea viene utilizzato per replicare i dati tra server forniti da fornitori diversi. Ad esempio, ti consente di copiare i dati da un server SQL a un server non SQL.
Replica transazionale peer-to-peer
Replica peer-to-peer si basa sulla replica transazionale. Consente a tutti gli utenti e i server partecipanti di scambiarsi dati in modo che gli aggiornamenti avvengano quasi in tempo reale.
La replica peer-to-peer è particolarmente utile per le applicazioni web. La sua flessibilità aiuta a scalare il numero di utenti senza influire sulle prestazioni. Inoltre, rende il sistema più robusto, consentendo ai server di spegnersi per la manutenzione.
Schemi di replica del database
Per la replica del database vengono utilizzati i seguenti schemi di replica:
Replica completa
Esecuzione di una replica completa significa copiare il database completo su ogni nodo del sistema distribuito. Questo approccio massimizza la ridondanza dei dati, aumenta le prestazioni globali e la disponibilità dei dati. I dati sono disponibili finché un nodo è funzionante.
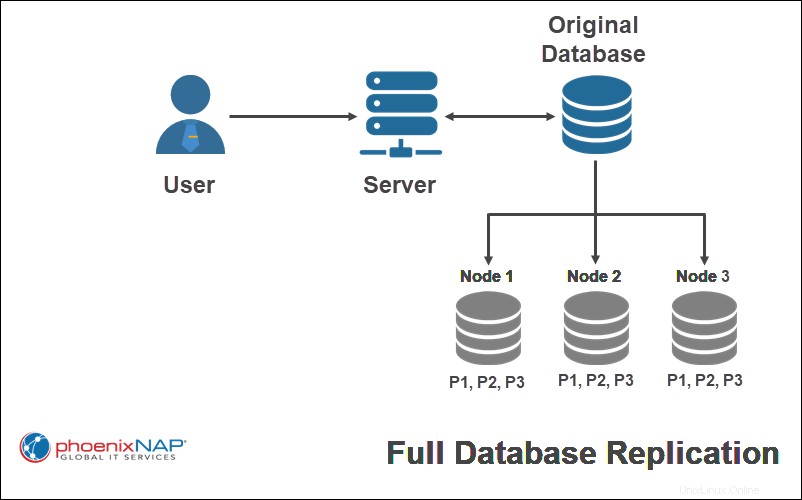
Nell'esempio precedente, tutte le parti del database originale (P1, P2, P3) vengono completamente replicate su tutti i siti.
L'esecuzione della replica completa richiede più tempo poiché l'aggiornamento deve essere replicato in tutti i siti. Inoltre, i costi per l'archiviazione di snapshot di dati completi in più posizioni possono aumentare.
Replica parziale
Copiare solo alcune parti di un database è una replica parziale . Questo di solito è deciso da quanto sia importante avere i dati disponibili in ogni posizione.
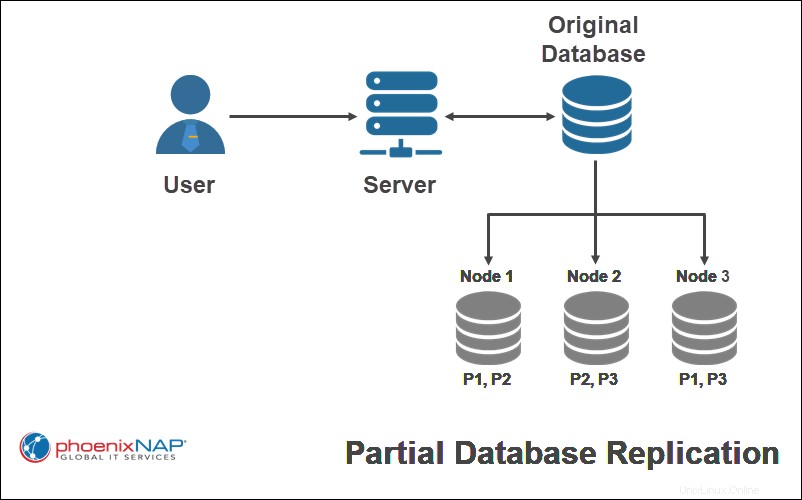
Nell'esempio sopra, solo alcune parti del database originale (P1, P2, P3) vengono replicate su un singolo nodo.
Quando si utilizza uno schema di replica parziale, il numero di copie per ciascuna parte del database può variare da uno al numero di nodi totali nel sistema distribuito.
Nessuna replica
Con nessuna replica , ogni nodo in un sistema distribuito riceve solo una copia di una parte del database. Questo schema di replica è il più veloce da eseguire, ma tende a ridurre la disponibilità dei dati e lascia il database vulnerabile alla perdita di dati. Tuttavia, la concorrenza è facile da ottenere.
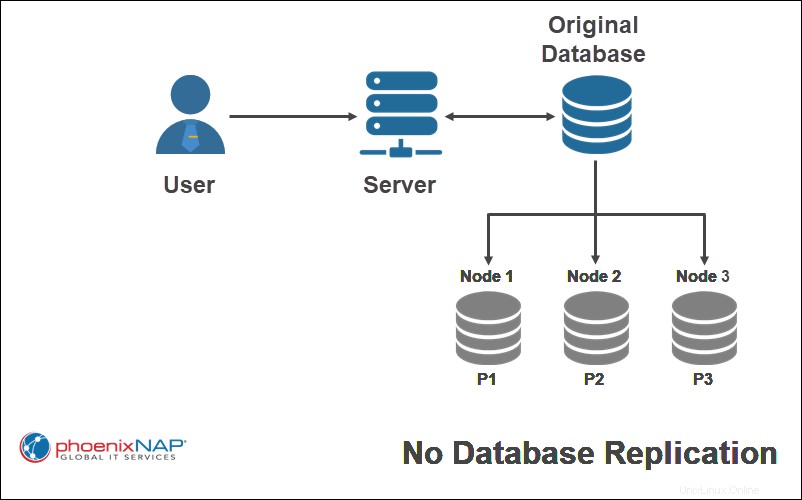
Nell'esempio sopra, solo un singolo frammento del database originale viene replicato su un nodo specifico.
Software e strumenti per la replica del database
Molti strumenti di gestione del database offrono modi per eseguire la replica del database. Esistono anche strumenti di replica di terze parti che forniscono le stesse funzionalità.
Gli strumenti di terze parti possono anche essere più flessibili poiché la maggior parte consente di replicare su più tipi di database. Ecco alcuni degli esempi più popolari:
- Backup e ripristino dei dati phoenixNAP. phoenixNAP offre molteplici opzioni e soluzioni di backup, tra cui integrazione Veeam, backup di database cloud, backup gestito per Office 365 e DRaaS (Disaster Recovery as a Service).
- Veeam Backup &Replication . Veeam funziona con diversi tipi di database, inclusi database cloud, virtuali, Kubernetes e distribuzioni fisiche. Offre protezione continua dei dati, replica avanzata e failover per il ripristino di emergenza e ripristino istantaneo per i gestori di database più diffusi, come NAS, Microsoft SQL e Oracle.
- Acronis Cyber Backup . Acronis supporta oltre 20 piattaforme di database e offre funzionalità di sicurezza avanzate, come la prevenzione del ransomware basata sull'intelligenza artificiale.
- Backup e replica NAKIVO . NAKIVO offre funzionalità come supporto per app live, ripristino a livello di file e oggetto, deduplicazione globale e report automatici. Può replicare i dati localmente, su un server remoto o nel cloud.
- Backup Carbonite Safe. Carbonite è orientato alle piccole imprese. Offre backup automatico su cloud e disco rigido, backup di immagini e ripristino bare metal e replica di database a livelli superiori.
Vantaggi della replica dei dati
L'uso della replica del database aiuta:
- Garantire la continuità aziendale con un piano di ripristino di emergenza. In caso di guasto dell'hardware o di un attacco ransomware, la replica dei dati come parte del piano di ripristino di emergenza garantisce la presenza di una copia fuori sede del sistema. Ciò consente alle organizzazioni di ripristinare i dati e mantenere la continuità aziendale.
- Migliora le prestazioni. Avere gli stessi dati in più posizioni significa che un utente può recuperare i dati dal server più vicino, riducendo la latenza di rete e aumentando le prestazioni.
- Migliora il supporto multiutente. La replica dei dati aiuta con l'esecuzione delle query, specialmente quando più utenti accedono al database.
- Migliora l'analisi. Avere una copia separata e completa di un database consente a un team di eseguire analisi senza influire sulle prestazioni.
- Migliora la disponibilità. Diversi utenti possono accedere e gestire i dati in un database distribuito senza intralciarsi a vicenda.
Svantaggi della replica dei dati
La replica dei dati pone diverse sfide:
- Può richiedere molto spazio di archiviazione, soprattutto per le repliche complete. Ciò può creare costi elevati o ridurre le prestazioni se è necessario aggiornare più repliche contemporaneamente.
- Mantenere la coerenza dei dati è difficile quando si utilizzano metodi come la fusione o la replica peer-to-peer.