Introduzione
Denormalizzazione del database è una tecnica utilizzata per migliorare le prestazioni di accesso ai dati. Quando un database viene normalizzato e metodi come l'indicizzazione non sono sufficienti, la denormalizzazione rappresenta una delle opzioni finali per accelerare il recupero dei dati.
Questo articolo spiega cos'è la denormalizzazione del database e le diverse tecniche utilizzate per velocizzare un database.

Cos'è la denormalizzazione del database?
Denormalizzazione del database è il processo di combinazione sistematica dei dati per ottenere rapidamente informazioni. Il processo riduce le relazioni a forme normali inferiori, riducendo l'integrità complessiva dei dati.
D'altra parte, le prestazioni di recupero dei dati aumentano. Invece di eseguire più JOIN costosi su numerose tabelle, la normalizzazione del database aiuta a riunire informazioni comunemente o logicamente combinate.
Le anomalie del database compaiono a causa di forme normali inferiori. Il problema delle ridondanze trova una soluzione nell'aggiunta di limitazioni a livello di software durante l'immissione di dati in un database.
Normalizzazione del database e denormalizzazione
La normalizzazione e la denormalizzazione del database sono due modi diversi per modificare la struttura di un database. La tabella descrive le principali differenze tra i due metodi:
| Normalizzazione | Denormalizzazione | |
|---|---|---|
| Funzionalità | Rimuove le informazioni ridondanti e migliora la velocità di modifica dei dati. | Combina più informazioni in un'unica unità e migliora la velocità di recupero dei dati. |
| Concentrati | Pulizia del database per rimuovere le ridondanze. | Introdotte ridondanze per un'esecuzione più rapida delle query. |
| Memoria | Prestazioni generali ottimizzate e migliorate. | Inefficienza della memoria dovuta a ridondanze. |
| Integrità | La rimozione delle anomalie del database migliora l'integrità del database. | Nessuna integrità dei dati mantenuta. Sono presenti anomalie del database. |
| Caso d'uso | Database in cui inserimento, aggiornamento ed eliminazione delle modifiche avvengono spesso e i join non sono costosi. | Database spesso interrogate, come data warehouse. |
| Tipo di elaborazione | Elaborazione delle transazioni online - OLTP | Elaborazione analitica online - OLAP |
La normalizzazione del database richiede un database non normalizzato attraverso moduli normali per migliorare la struttura dei dati. D'altra parte, la denormalizzazione inizia con un database normalizzato e combina i dati per un'esecuzione più rapida delle query di uso comune.
Perché e quando dovresti denormalizzare un database?
La denormalizzazione del database è una tecnica praticabile quando la velocità di recupero dei dati è un fattore essenziale. Tuttavia, il metodo modifica la struttura generale del database. La denormalizzazione è utile nei seguenti scenari:
- Miglioramento delle prestazioni delle query. Mettere insieme le informazioni aggiunge ridondanze. Tuttavia, il numero di JOIN si riduce, il che aumenta le prestazioni delle query.
- Comodità di gestione . Un database normalizzato è difficile da gestire a causa dell'elevata granularità. Invece di calcolare i valori o collegarli secondo necessità, la denormalizzazione aiuta a fornire dati prontamente disponibili.
- Rapporti accelerati . I dati analitici richiedono molti calcoli prontamente. Un database denormalizzato per la generazione di report è una soluzione perfetta per fornire rapidamente informazioni analitiche.
Se un database ha prestazioni basse, la denormalizzazione non è sempre la strada giusta da percorrere. Poiché il processo modifica la struttura del database, le funzionalità esistenti rischiano di interrompersi.
Avere un punto di riferimento è un concetto importante quando si cambia la struttura del database. In definitiva, la normalizzazione del database funge da ultima risorsa invece di una soluzione rapida.
Tecniche di denormalizzazione
Esistono varie tecniche di denormalizzazione del database utilizzate a seconda del caso d'uso. Ogni metodo ha un luogo di utilizzo appropriato, vantaggi e svantaggi.
Pre-unirsi ai tavoli
Le tabelle preunite memorizzano le informazioni utilizzate di frequente insieme in un'unica tabella. Il processo è utile quando:
- Le query vengono spesso eseguite insieme sui tavoli.
- L'operazione di adesione è costosa.
Il metodo crea enormi ridondanze, quindi è essenziale utilizzare un numero minimo di colonne e aggiornare periodicamente le informazioni.
Esempio di tabelle pre-unite
Un negozio conserva le informazioni sugli articoli e le categorie a cui appartengono gli articoli. La chiave esterna funge da riferimento al tipo di elemento. La pre-unione delle tabelle aggiunge il nome della categoria alla tabella degli elementi.
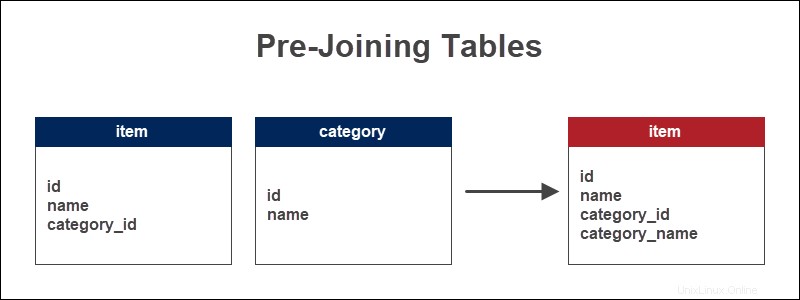
L'aggiunta del nome della categoria direttamente alla tabella degli elementi consente di visualizzare rapidamente gli elementi per categoria. Per le query più lunghe, questo metodo consente di risparmiare tempo e riduce il numero di JOIN.
Tavoli specchiati
Una tabella con mirroring è una copia di una tabella esistente. La tabella è:
- Una copia parziale.
- Una copia completa.
L'obiettivo è riprodurre i dati dall'originale in una nuova tabella. Creare duplicati è una buona tecnica per creare un backup per preservare lo stato iniziale del database.
Esempio di tabelle speculari
Le tabelle di mirroring sono un metodo spesso utilizzato per preparare i dati nei sistemi di supporto alle decisioni. Poiché le query di solito si aggregano su molti punti dati, l'attività ridurrebbe significativamente le prestazioni del sistema.
I sistemi di supporto alle decisioni traggono grande vantaggio dall'uso di tabelle speculari. L'applicazione delle transazioni sulla tabella originale non viene interrotta mentre i rapporti impegnativi vengono eseguiti sulla tabella duplicata.
Suddivisione delle tabelle
La suddivisione delle tabelle implica la divisione delle tabelle normalizzate in due o più relazioni. La divisione dei tavoli avviene in due dimensioni:
- Orizzontale . Tabelle suddivise in sottoinsiemi di righe utilizzando
UNIONoperatore. - Verticale . Tabelle suddivise in sottoinsiemi di colonne utilizzando
INNER JOINoperatore.
L'obiettivo del metodo è dividere le tabelle in unità più piccole per una gestione dei dati più rapida e conveniente. Se il database contiene anche la tabella originale, questo metodo è considerato un caso particolare di tabelle con mirroring.
Esempi di suddivisione delle tabelle
Gli esempi di utilizzo dipendono dai criteri di suddivisione delle tabelle. I motivi più comuni per dividere le tabelle sono:
- Amministrativo . Un tavolo per ogni settore invece di un tavolo per un'intera azienda.
- Spaziale . Un tavolo per ogni regione invece di un tavolo per l'intero paese.
- Basato sul tempo . Un tavolo per ogni mese invece di un tavolo per un anno intero.
- Fisico . Una tabella per ogni posizione invece di una tabella per tutti i siti.
- Procedurale . Una tabella per ogni passaggio di un'attività invece di una tabella per un intero lavoro.
Memorizzazione di valori derivati
La memorizzazione dei calcoli eseguiti di frequente è utile in situazioni in cui:
- L'uso del valore derivato è frequente.
- I valori di origine non cambiano.
L'archiviazione diretta dei dati derivabili garantisce che i calcoli siano già eseguiti durante la generazione di un report ed elimina la necessità di cercare i valori di origine per ogni query.
Esempio di memorizzazione di valori derivati
Se disponiamo di una tabella di database che tiene traccia delle informazioni sulle persone, l'età di una persona è un valore calcolato in base alla data di nascita. Deriva l'età trovando la differenza tra la data corrente usando la funzione data MySQL CURDATE() e la data di nascita.
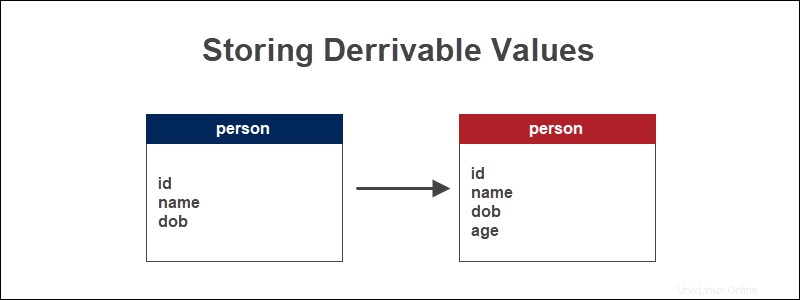
L'età è un'informazione essenziale quando si analizzano informazioni demografiche. Il valore di origine, che è la data di nascita, non cambia.
Tabelle della gerarchia
Una tabella gerarchica è una struttura ad albero con una relazione uno-a-molti. Una tabella genitore ha molti figli. Tuttavia, i figli hanno solo una tabella padre. Le tabelle gerarchiche vengono utilizzate nei casi in cui:
- La struttura dei dati è gerarchica.
- Le tabelle principali sono statiche e immutabili.
Valori hardcoded
I valori hardcoded rimuovono un riferimento a un'entità comunemente usata. Utilizzare questo metodo nelle situazioni in cui:
- I valori sono considerati statici.
- Il numero di valori è piccolo.
Invece di utilizzare una piccola tabella di ricerca, i valori vengono codificati direttamente nell'applicazione. Il processo evita anche di dover eseguire join sulla tabella di ricerca.
Esempio di valori hard-coded
Una tabella con informazioni sulle persone potrebbe utilizzare una piccola tabella di ricerca per memorizzare informazioni sul sesso degli individui. Poiché le informazioni nella tabella di ricerca hanno un numero limitato di valori, prendi in considerazione la possibilità di codificare i dati direttamente nella tabella delle persone.
I valori hardcoded eliminano la necessità di una tabella di ricerca e l'operazione JOIN con quella tabella. Eventuali modifiche apportate alla tabella di consultazione o la registrazione di nuovi valori richiedono l'aggiunta di un vincolo di verifica.
Memorizzare i dettagli con il Master
La tabella principale contiene la tabella principale delle informazioni, mentre le altre tabelle contengono dettagli specifici. Memorizza i dettagli con la tabella principale quando:
- È essenziale una panoramica dettagliata della tabella principale.
- I report analitici sulla tabella master sono frequenti.
Mantenere tutti i dettagli con la tabella principale è conveniente quando si selezionano i dati. Il metodo funziona meglio quando ci sono meno dettagli. In caso contrario, il processo di recupero dei dati rallenta notevolmente.
Esempio di memorizzazione dei dettagli con il Master
Una tabella principale con le informazioni sui clienti in genere memorizza dettagli specifici sulla persona in una tabella separata. Le informazioni sulla posizione particolare, ad esempio, di solito risiedono in una serie di tabelle più piccole.
Qualsiasi rapporto che consideri la posizione dei clienti trae vantaggio dall'aggiunta dei dettagli della posizione alla tabella principale.
Ripetizione di un singolo dettaglio con il Master
Le query spesso richiedono solo un singolo dettaglio aggiunto alla tabella principale invece di pre-unire più valori. Utilizzare questo metodo quando:
- Le JOIN sono costose per un singolo dettaglio.
- La tabella principale richiede spesso le informazioni.
L'aggiunta di un singolo dettaglio a una tabella principale è più comune quando il database contiene dati storici. L'entità ripetuta è solitamente l'informazione più recente.
Esempio di dettaglio singolo con Master
Un database di un negozio normalmente ha una tabella principale di informazioni sugli articoli che vende. Un'altra tabella con i dettagli sulle variazioni di prezzo storiche contiene anche le informazioni sul prezzo corrente.
Poiché questo singolo dettaglio aiuta ad analizzare i prezzi correnti degli articoli, le informazioni più recenti sul prezzo possono essere ripetute nella tabella principale.
Eventuali modifiche ai costi devono essere affrontate e aggiornate anche nella tabella principale per coerenza.
Tasti di cortocircuito
In un database con tre o più tabelle di informazioni correlate, il metodo delle chiavi di cortocircuito salta le tabelle intermedie e "corre in cortocircuito" le tabelle dei nonni e dei nipoti.
Utilizzare la tecnica del cortocircuito nelle situazioni in cui:
- Un database ha più di tre livelli di dettaglio principale.
- I valori dei nonni e dei nipoti sono spesso necessari e le informazioni sui genitori non sono così preziose.
Se due relazioni sono correlate attraverso una tabella centrale, ometti il JOIN sulla relazione intermedia e collega direttamente la prima e l'ultima tabella.
Esempio di tasti di scelta rapida
Un sistema informativo potrebbe conservare le informazioni sulle persone in una tabella, il loro indirizzo in un'altra posizione e l'area geografica di quell'indirizzo in una terza tabella. Per qualsiasi rapporto demografico, l'indirizzo esatto non è un'informazione fondamentale.
Tuttavia, la posizione di una persona è essenziale per l'analisi. Cortocircuitare il tavolo delle persone con l'area omette il JOIN sul tavolo centrale.
Vantaggi della denormalizzazione
I vantaggi di denormalizzazione del database sono:
- Velocità . Poiché le query JOIN sono costose su un database normalizzato, il recupero dei dati è più rapido.
- Semplicità . Il recupero dei dati è più semplice a causa del numero inferiore di tabelle.
- Meno errori . Lavorare con un numero inferiore di tabelle significa meno bug durante il recupero delle informazioni da un database.
Svantaggi della denormalizzazione
Gli svantaggi da considerare quando si denormalizza un database sono:
- Complessità . L'aggiornamento e l'inserimento in un database è più complesso e costoso.
- Incoerenza . Trovare il valore corretto per un'informazione è più difficile perché i dati sono difficili da aggiornare.
- Archiviazione . È necessario uno spazio di archiviazione più significativo a causa delle ridondanze introdotte.