Introduzione
Spark DataFrame è una struttura di dati integrata con un'API di facile utilizzo per semplificare l'elaborazione di big data distribuita. DataFrame è disponibile per linguaggi di programmazione generici come Java, Python e Scala.
È un'estensione dell'API Spark RDD ottimizzata per scrivere codice in modo più efficiente pur rimanendo potente.
Questo articolo spiega cos'è Spark DataFrame, le funzionalità e come utilizzare Spark DataFrame durante la raccolta dei dati.

Prerequisiti
- Spark installato e configurato (segui la nostra guida:Come installare Spark su Ubuntu, Come installare Spark su Windows 10).
- Un ambiente configurato per l'utilizzo di Spark in Java, Python o Scala (questa guida utilizza Python).
Cos'è un DataFrame?
Un DataFrame è un'astrazione di programmazione nel modulo Spark SQL. I DataFrame assomigliano a tabelle di database relazionali o fogli di calcolo excel con intestazioni:i dati risiedono in righe e colonne di diversi tipi di dati.
L'elaborazione viene eseguita utilizzando complesse funzioni definite dall'utente e funzioni familiari di manipolazione dei dati, come ordinamento, unione, gruppo, ecc.
Le informazioni per i dati distribuiti sono strutturate in schemi . Ogni colonna in un DataFrame contiene la colonna nome , tipo di dati, e annullabile proprietà. Quando annullabile è impostato su vero , una colonna accetta null anche le proprietà.

Come funziona un DataFrame?
L'API DataFrame fa parte del modulo Spark SQL. L'API fornisce un modo semplice per lavorare con i dati all'interno del framework Spark SQL mentre si integra con linguaggi generici come Java, Python e Scala.
Sebbene ci siano somiglianze con Python Panda e frame di dati R, Spark fa qualcosa di diverso. Questa API è fatta su misura per l'integrazione con dati su larga scala per data science e machine learning e offre numerose ottimizzazioni.
Spark DataFrame sono distribuibili su più cluster e ottimizzati con Catalyst. L'ottimizzatore Catalyst accetta le query (inclusi i comandi SQL applicati a DataFrames) e crea un piano di calcolo parallelo ottimale.
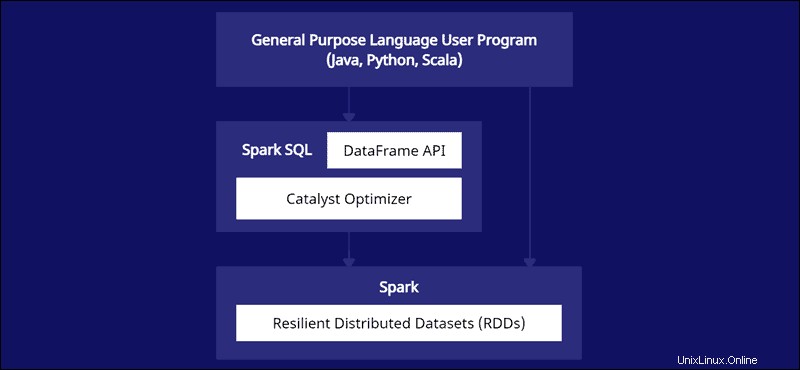
Se hai esperienza con i frame di dati Python e R, il codice Spark DataFrame sembra familiare. D'altra parte, se utilizzi Spark RDD (Resilient Distributed Dataset), avere informazioni sulla struttura dei dati offre opportunità di ottimizzazione.
I creatori di Spark hanno progettato DataFrames per affrontare le sfide dei big data nel modo più efficiente. Gli sviluppatori possono sfruttare la potenza dell'elaborazione distribuita con API familiari ma più ottimizzate.
Caratteristiche di Spark DataFrames
Spark DataFrame è dotato di molte preziose funzionalità:
- Supporto per vari formati di dati, come Hive, CSV, XML, JSON, RDD, Cassandra, Parquet, ecc.
- Supporto per l'integrazione con vari strumenti Big Data.
- La capacità di elaborare kilobyte di dati su macchine più piccole e petabyte su cluster.
- Ottimizzatore del catalizzatore per un'elaborazione efficiente dei dati in più lingue.
- Gestione dei dati strutturati attraverso una vista schematica dei dati.
- Gestione personalizzata della memoria per ridurre il sovraccarico e migliorare le prestazioni rispetto agli RDD.
- API per Java, R, Python e Spark.
Come creare un DataFrame Spark?
Esistono più metodi per creare un DataFrame Spark. Ecco un esempio di come crearne uno in Python utilizzando l'ambiente notebook Jupyter:
1. Inizializza e crea una sessione API:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. Crea dati giocattolo come un elenco di dizionari:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
3. Crea il DataFrame utilizzando createDataFrame funzione e passare i data elenco:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. Stampa lo schema e la tabella per visualizzare il DataFrame creato:
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()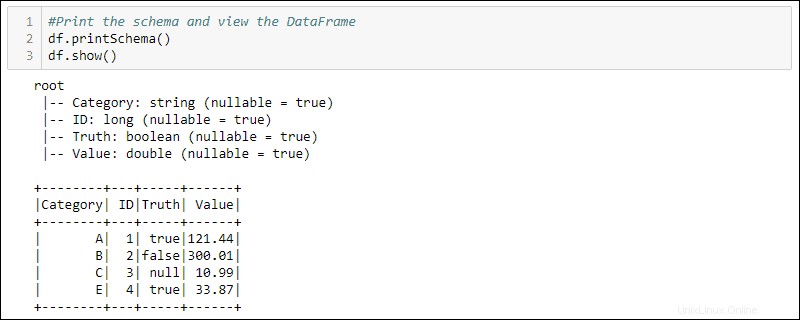
Come utilizzare i DataFrame
I dati strutturati memorizzati in un DataFrame forniscono due metodi di manipolazione
- Utilizzo di un linguaggio specifico del dominio
- Utilizzo di query SQL.
I due metodi successivi utilizzano il DataFrame dell'esempio precedente per selezionare tutte le righe in cui la colonna Truth è impostata su true e ordinare i dati in base alla colonna Value.
Metodo 1:utilizzo di query specifiche del dominio
Python fornisce metodi integrati per filtrare e ordinare i dati. Seleziona la colonna specifica utilizzando df.<column name> :
df.filter(df.Truth == True).sort(df.Value).show()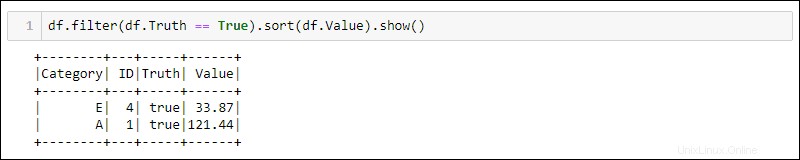
Metodo 2:utilizzo di query SQL
Per utilizzare le query SQL con DataFrame, crea una vista con createOrReplaceTempView metodo integrato ed eseguire la query SQL utilizzando spark.sql metodo:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')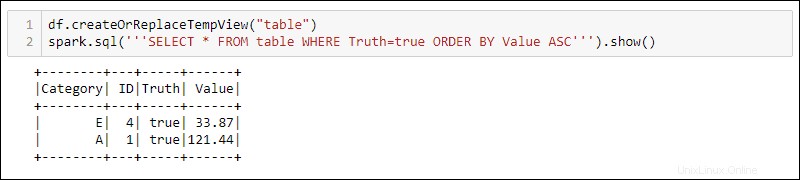
L'output mostra i risultati della query SQL applicati alla visualizzazione temporanea di DataFrame. Ciò consente di creare più visualizzazioni e query sugli stessi dati per l'elaborazione di dati complessi.