Introduzione
La stella e fiocco di neve schema sono progetti di archiviazione logica che si trovano comunemente nei data mart e nell'architettura del data warehouse. Mentre i tipi di database comuni utilizzano i diagrammi ER (Entity-Relationship), la struttura logica dei magazzini utilizza modelli dimensionali per concettualizzare il sistema di archiviazione.
Continua a leggere per scoprire le differenze, le caratteristiche e i difetti degli schemi a stella e fiocco di neve.

Schema a stella e schema a fiocco di neve:la differenza principale
I due elementi principali del modello dimensionale dello schema stella e fiocco di neve sono:
1. Tabella dei fatti . Una tabella con la quantità di dati più considerevole, nota anche come cubo .
2. Tabelle dimensionali . La struttura dei dati derivati fornisce risposte a query o dimensioni ad hoc, spesso denominate tabelle di ricerca .
Collegamento delle dimensioni scelte su una tabella dei fatti costituisce lo schema. Sia lo schema a stella che quello a fiocco di neve utilizzano la dimensionalità dei dati per modellare il sistema di archiviazione.
Le principali differenze tra i due schemi sono:
| Schema a stella | Schema fiocco di neve | |
|---|---|---|
| Elementi | Tabella dei fatti Tabelle dimensionali | Tabella dei fatti Tabelle dimensionali Tabelle delle sottodimensioni |
| Struttura | A forma di stella | A forma di fiocco di neve |
| Dimensioni | Una tabella per dimensione | Più tabelle per ogni dimensione |
| Direzione modello | Dall'alto in basso | Basso in alto |
| Spazio di archiviazione | Utilizza più spazio di archiviazione | Utilizza meno spazio |
| Normalizzazione | Tabelle dimensionali denormalizzate | Tabelle dimensionali normalizzate |
| Rendimento delle query | Veloce, meno JOIN necessari a causa del minor numero di chiavi esterne | Lento, più JOIN richiesti a causa di più chiavi esterne |
| Complessità delle query | Semplice e di facile comprensione | Complicato e più impegnativo da capire |
| Ridondanza dei dati | Alto | Basso |
| Caso d'uso | Tabelle delle dimensioni con più righe, tipiche dei data mart | Tabelle delle dimensioni con più righe trovate con i data warehouse |
A causa della complessità dello schema del fiocco di neve e delle prestazioni inferiori, lo schema a stella è l'opzione preferita quando possibile. Un modo tipico per aggirare i problemi nello schema del fiocco di neve è scomporre lo spazio di archiviazione dedicato in più entità più piccole con uno schema a stella.
Cos'è uno schema a stella?
Uno schema a stella è una struttura logica per lo sviluppo di data mart e data warehouse più semplici. Il modello semplice è costituito da tabelle dimensionali collegate a una tabella dei fatti al centro.
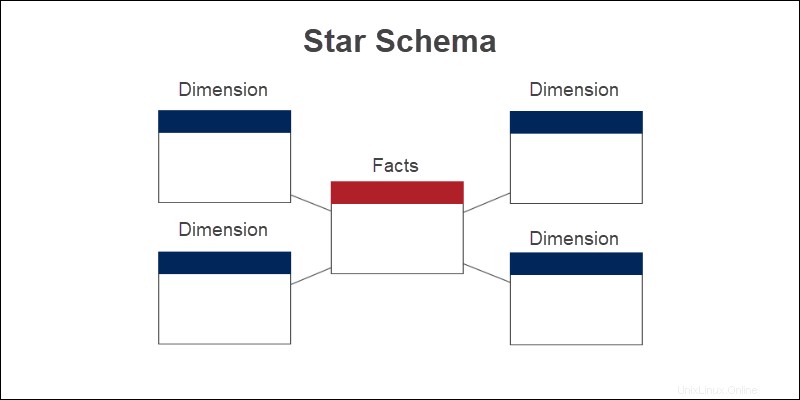
La tabella dei fatti è tipicamente composta da:
- Dati numerici quantificabili, come valori o conteggi.
- Riferimenti alle dimensioni tramite chiavi esterne.
Le tabelle di ricerca rappresentano informazioni descrittive direttamente collegate alla tabella dei fatti.
Ad esempio, per modellare le vendite di un'attività di e-commerce, la tabella dei fatti per gli acquisti potrebbe contenere il prezzo totale dell'acquisto. D'altra parte, le tabelle dimensionali contengono informazioni descrittive sugli articoli, i dati del cliente, l'ora o il luogo di acquisto.
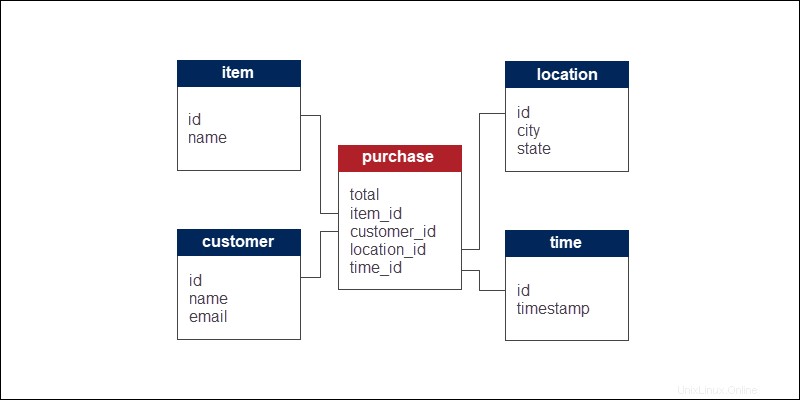
Lo schema a stella per l'analisi degli acquisti nell'esempio ha quattro dimensioni. La tabella dei fatti si collega alle tabelle dimensionali attraverso il concetto di chiavi esterne e primarie. Oltre ai dati numerici, la tabella dei fatti è quindi composta anche da chiavi esterne per definire le relazioni tra tabelle.
Caratteristiche di uno schema a stella
Le caratteristiche principali dello schema a stella sono:
- Query semplificate e veloci . Un minor numero di operazioni JOIN dovute alla denormalizzazione rende le informazioni più facilmente disponibili.
- Relazioni semplici. Lo schema funziona alla grande con relazioni uno-a-uno o uno-a-molti.
- Singolare dimensionalità . Una tabella descrive ogni dimensione.
- Compatibile con OLAP . I sistemi OLAP utilizzano ampiamente lo schema a stella per progettare cubi di dati.
Svantaggi di uno schema a stella
Gli svantaggi dell'utilizzo dello schema a stella sono:
- Ridondanza . Le tabelle dimensionali sono unidimensionali ed è presente la ridondanza dei dati.
- Integrità bassa . A causa della denormalizzazione, l'aggiornamento delle informazioni è un compito complesso.
- Query limitate . L'insieme delle domande è limitato, il che restringe anche il potere analitico.
Che cos'è uno schema di fiocchi di neve?
Lo schema del fiocco di neve ha una struttura logica ramificata utilizzata nei grandi data warehouse. Dal centro ai bordi, le informazioni sull'entità vanno da generali a più specifiche.
Oltre agli elementi comuni del modello dimensionale, lo schema del fiocco di neve scompone ulteriormente le tabelle dimensionali in sottodimensioni.
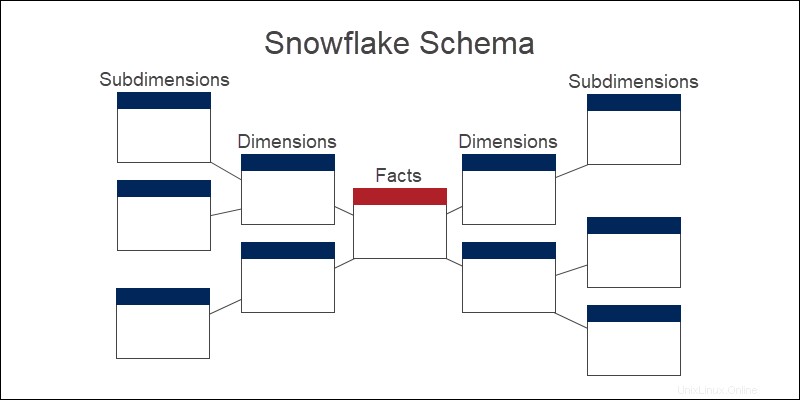
Il modello di analisi delle vendite e-commerce dell'esempio precedente si ramifica ulteriormente ("fiocchi di neve") in categorie e sottocategorie di interesse più piccole.
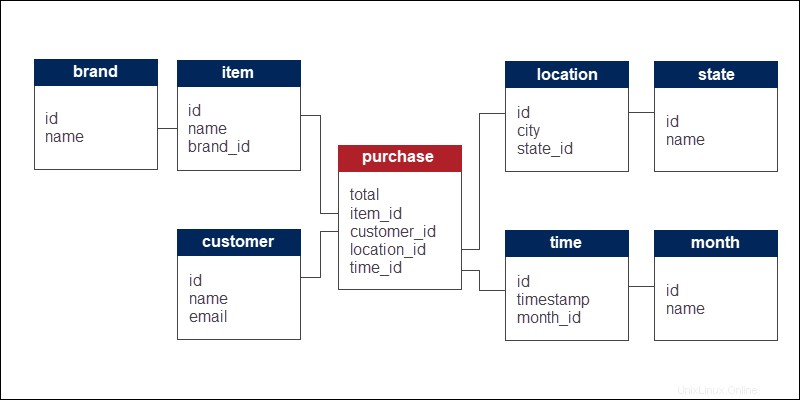
Le quattro dimensioni si scompongono in sottodimensioni. Le tabelle di ricerca si normalizzano ulteriormente attraverso una serie di oggetti connessi.
Caratteristiche di uno schema di fiocchi di neve
Le caratteristiche principali dello schema del fiocco di neve includono:
- Piccolo spazio di archiviazione . Lo schema del fiocco di neve non richiede tanto spazio di archiviazione.
- Elevata granularità . La divisione delle tabelle in sottodimensioni consente l'analisi a varie profondità di interesse. Anche l'aggiunta di nuove sottodimensioni è un processo semplice.
- Integrità . A causa della normalizzazione, lo schema ha un livello più elevato di integrità dei dati e basse ridondanza.
Svantaggi di uno schema di fiocchi di neve
I punti deboli dello schema del fiocco di neve sono:
- Complessità . Il modello del database è complesso, così come le query eseguite. Tabelle multidimensionali multiple rendono complicato lavorare con il design in generale.
- Elaborazione lenta . Molte tabelle di ricerca richiedono più operazioni JOIN, il che rallenta il recupero delle informazioni.
- Difficile da mantenere . Un elevato livello di granularità rende lo schema difficile da gestire e mantenere.