Introduzione
Con così tante opzioni disponibili, può essere difficile scegliere una soluzione di database che si adatti perfettamente alle tue esigenze. Quando si tratta di tipi di database, un'opzione popolare è un database relazionale.
In questo articolo tratteremo la struttura dei database relazionali, il modo in cui funzionano e i vantaggi e gli svantaggi del loro utilizzo. Useremo anche esempi per illustrare come i database relazionali organizzano i dati.

Definizione database relazionale
Un database relazionale è un tipo di database che si concentra sulla relazione tra gli elementi di dati memorizzati. Consente agli utenti di stabilire collegamenti tra diversi insiemi di dati all'interno del database e di utilizzare questi collegamenti per gestire e fare riferimento ai dati correlati.
Molti database relazionali utilizzano SQL (Structured Query Language) per eseguire query e mantenere i dati.
Database relazionali e non relazionali
I database relazionali si concentrano sulle relazioni tra i dati. Pertanto, il database delle relazioni deve archiviare i dati in un modo altamente strutturato. Ciò consente tempi di indicizzazione e di risposta alle query più rapidi e rende i dati più sicuri e coerenti.
D'altra parte, i database NoSQL non devono fare molto affidamento sulla struttura, il che consente loro di archiviare grandi quantità di dati, rimanere flessibili e scalare facilmente lo storage e le prestazioni.
Come sono organizzati i dati in un sistema di database relazionale?
I sistemi di database relazionali utilizzano un modello che organizza i dati in tabelle di righe (chiamato anche record o tuple ) e colonne (chiamati anche attributi o campi ). In genere, le colonne rappresentano categorie di dati, mentre le righe rappresentano singole istanze.
Usiamo come esempio una vetrina digitale. Il nostro database potrebbe avere una tabella contenente le informazioni sui clienti, con colonne che rappresentano i nomi o gli indirizzi dei clienti, mentre ogni riga contiene i dati di un singolo cliente.

Queste tabelle possono essere collegate o correlate utilizzando chiavi . Ogni riga di una tabella viene identificata utilizzando una chiave univoca, denominata chiave primaria. Questa chiave primaria può essere aggiunta a un'altra tabella, diventando una chiave esterna. La relazione chiave primaria/chiave esterna costituisce la base del modo in cui funzionano i database relazionali.
Tornando al nostro esempio, se abbiamo una tabella che rappresenta gli ordini di prodotti, una delle colonne potrebbe contenere informazioni sui clienti. Qui possiamo importare una chiave primaria che si collega a una riga con le informazioni per un cliente specifico.
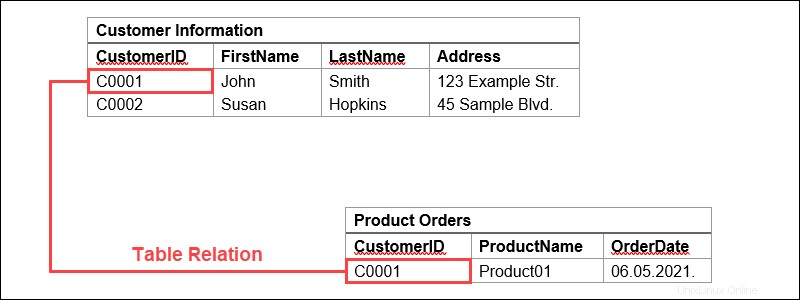
In questo modo, possiamo fare riferimento ai dati o duplicare i dati dalla tabella delle informazioni sul cliente. Significa anche che queste due tabelle sono ora correlate.
Esempi di database relazionali
Ora che abbiamo spiegato come funzionano, ecco alcuni degli esempi più popolari di database relazionali:
MySQL

MySQL è stato sviluppato come sistema di gestione open source per database relazionali fino a quando non è stato acquisito da Sun Microsystems (ora Oracle Corporation). È ancora disponibile con una licenza open source, con l'aggiunta di diverse licenze proprietarie.
MySQL offre supporto di replica integrato con conformità ACID, clustering senza condivisione e supporta più motori di archiviazione. Tuttavia, l'utilizzo di alcuni motori di archiviazione può causare il malfunzionamento di SQL.
MySQL eccelle nell'input rapido dei dati e nella scalabilità, pur mantenendo un'elevata disponibilità e prestazioni. Questo lo rende estremamente utile per lo sviluppo di applicazioni e web.
PostgreSQL

PostgreSQL è un gestore di database relazionale gratuito disponibile con una licenza open source. Condivide alcune funzionalità con MySQL, con la notevole aggiunta di MVCC (controllo della concorrenza multi-versione), che lo rende compatibile con ACID.
PostgreSQL mantiene un elevato livello di prestazioni e flessibilità, anche quando si gestiscono database di grandi dimensioni. È la scelta giusta per gli utenti che necessitano di velocità di lettura/scrittura elevate e un'analisi approfondita dei dati.
Alcuni utenti importanti di PostgreSQL includono Reddit, Skype e Instagram.
MariaDB

MariaDB ha iniziato come fork di MySQL guidato dalla comunità dopo che quest'ultimo è stato acquistato da Oracle. È ancora open-source, disponibile sotto la GNU General Public License.
MariaDB si basa sulla base MySQL aggiungendo il supporto per ancora più motori di archiviazione e risolvendo i limiti del motore di archiviazione. Ciò gli consente di funzionare ancora più velocemente di MySQL ed eseguire SQL e NoSQL in un unico database.
Gli utenti importanti di MariaDB includono Google, Mozilla e la Wikimedia Foundation.
SQLite

A differenza di altre voci in questo elenco, SQLite non è un gestore di database client-server ma piuttosto integrato nell'applicazione finale. Ciò lo rende leggero e in grado di funzionare con un'ampia gamma di sistemi e piattaforme.
Causa anche alcune limitazioni, poiché SQLite fornisce trigger solo in parte, ha un ALTER TABLE limitato funzione e non può scrivere nelle viste. Limita inoltre la dimensione massima del database a 32.000 colonne e 140 TB.
SQLite è, quindi, meglio utilizzato come componente di database per altre applicazioni. Gli usi degni di nota includono i browser più diffusi, come Google Chrome, Mozilla Firefox, Opera e Safari.
Che cos'è il sistema di gestione dei database relazionali?
Un sistema di gestione del database (DBMS) è una soluzione software che aiuta gli utenti a visualizzare, interrogare e gestire i database.
Sistemi di gestione di database relazionali (RDBMS) sono un sottoinsieme più avanzato di DBMS, che gestiscono database relazionali.
DBMS vs RDBMS
Ecco alcune delle differenze tra soluzioni DBMS più generali e RDBMS:
| DBMS | RDBMS |
| Memorizza quantità minori di dati come file, senza relazioni. | Memorizza grandi quantità di dati come tabelle correlate tra loro. |
| Può accedere a un solo elemento dati alla volta. | Può accedere a più elementi di dati contemporaneamente. |
| Lavorare con grandi quantità di dati rende il recupero più lento. | L'approccio relazionale consente al recupero dei dati di rimanere veloce anche per database di grandi dimensioni. |
| Nessuna normalizzazione del database. | Consente la normalizzazione del database. |
| Non supporta i database distribuiti. | Supporta database distribuiti. |
| Supporta un singolo utente. | Supporta più utenti. |
| Livello di sicurezza inferiore. | Più livelli di sicurezza. |
| Bassi requisiti software e hardware. | Alti requisiti software e hardware. |
Vantaggi e svantaggi del database relazionale
Come qualsiasi altro modello di database, ci sono vantaggi e svantaggi nell'utilizzo di database relazionali:
Vantaggi
Poiché i database relazionali utilizzano tabelle di righe e colonne, visualizzano i dati in modo più semplice rispetto ad altri tipi di database, rendendoli più facili da usare.
Questa struttura tabellare sposta l'attenzione sulla gestione dei dati, che consente prestazioni più rapide e l'utilizzo di query complesse e di alto livello.
Infine, i database relazionali semplificano la scalabilità dei dati semplicemente aggiungendo righe, colonne o intere tabelle senza modificare la struttura complessiva del database.
Svantaggi
Esistono limiti alla scalabilità dei database relazionali. In termini di dimensioni, alcuni database hanno limiti fissi sulla lunghezza delle colonne. Se il tuo database è basato su un unico server dedicato, il ridimensionamento richiede l'acquisto di più spazio sul server, rivelandosi costoso a lungo termine.
Inoltre, l'aggiunta costante di nuovi elementi a un database può renderlo così complesso che diventa difficile formare relazioni tra nuovi dati. Inoltre, le complicate relazioni tra i dati rallentano le query e influiscono negativamente sulle prestazioni.