Introduzione
HDFS (Hadoop Distributed File System) è un componente vitale del progetto Apache Hadoop. Hadoop è un ecosistema di software che collaborano per aiutarti a gestire i big data. I due elementi principali di Hadoop sono:
- Riduci mappa – responsabile dell'esecuzione dei compiti
- HDFS – responsabile della conservazione dei dati
In questo articolo parleremo del secondo dei due moduli. imparerai che cos'è HDFS, come funziona e la terminologia di base di HDFS .

Cos'è HDFS?
Hadoop Distributed File System è un file system di archiviazione dati a tolleranza di errore che viene eseguito su hardware di base. È stato progettato per superare le sfide che i database tradizionali non potevano. Pertanto, il suo pieno potenziale viene utilizzato solo quando si gestiscono big data.
I problemi principali che il file system Hadoop ha dovuto risolvere erano la velocità , costo e affidabilità .
Quali sono i vantaggi dell'HDFS?
I vantaggi di HDFS sono, infatti, le soluzioni che il file system fornisce per le sfide menzionate in precedenza:
- È veloce. Può fornire più di 2 GB di dati al secondo grazie alla sua architettura a cluster.
- È gratuito. HDFS è un software open source che viene fornito senza costi di licenza o supporto.
- È affidabile. Il file system memorizza più copie di dati in sistemi separati per garantire che sia sempre accessibile.
Questi vantaggi sono particolarmente significativi quando si tratta di big data e sono stati resi possibili dal modo particolare in cui HDFS gestisce i dati.
In che modo HDFS archivia i dati?
HDFS divide i file in blocchi e memorizza ogni blocco su un DataNode. Più DataNode sono collegati al nodo master nel cluster, il NameNode. Il nodo master distribuisce le repliche di questi blocchi di dati nel cluster. Indica inoltre all'utente dove trovare le informazioni desiderate.
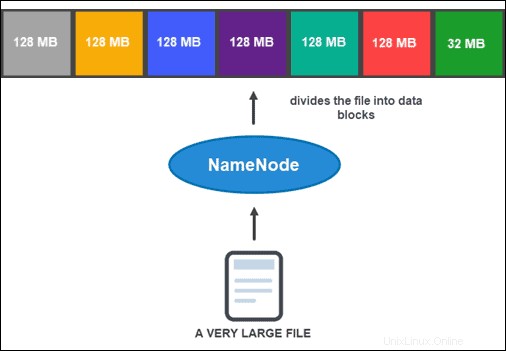
Tuttavia, prima che NameNode possa aiutarti a memorizzare e gestire i dati, deve prima partizionare il file in blocchi di dati più piccoli e gestibili. Questo processo è chiamato divisione dei blocchi di dati .
Divisione blocco dati
Per impostazione predefinita, un blocco non può avere dimensioni superiori a 128 MB. Il numero di blocchi dipende dalla dimensione iniziale del file. Tutti tranne l'ultimo blocco hanno le stesse dimensioni (128 MB), mentre l'ultimo è ciò che resta del file.
Ad esempio, un file da 800 MB viene suddiviso in sette blocchi di dati. Sei dei sette blocchi sono 128 MB, mentre il settimo blocco dati sono i restanti 32 MB.
Quindi, ogni blocco viene replicato in più copie.
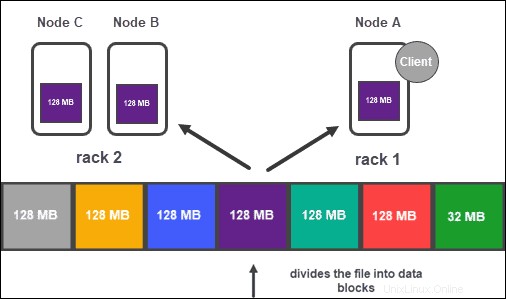
Replica dei dati
In base alla configurazione del cluster, il NameNode crea un numero di copie di ciascun blocco di dati utilizzando il metodo di replica .
Si consiglia di avere almeno tre repliche, che è anche l'impostazione predefinita. Il nodo master li archivia in DataNode separati del cluster. Lo stato dei nodi è attentamente monitorato per garantire che i dati siano sempre disponibili.
Per garantire un'elevata accessibilità, affidabilità e tolleranza agli errori, gli sviluppatori consigliano di configurare le tre repliche utilizzando la seguente topologia:
- Conserva la prima replica sul nodo in cui si trova il client.
- Quindi, archivia la seconda replica su un rack diverso.
- Infine, archivia la terza replica sullo stesso rack della seconda replica, ma su un nodo diverso.
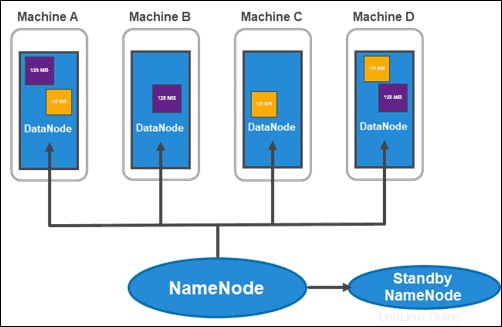
Architettura HDFS:NameNode e DataNode
HDFS ha un'architettura master-slave. Il nodo principale è il NomeNode , che gestisce più nodi slave all'interno del cluster, noti come DataNodes .
NomeNode
Hadoop 2.x ha introdotto la possibilità di avere più NameNode per rack. Questa novità è stata piuttosto significativa poiché avere un unico nodo master con tutte le informazioni all'interno del cluster rappresentava una grande vulnerabilità.
Il solito cluster è costituito da due NameNode:
- un NameNode attivo
- e un NameNode di riserva
Mentre il primo si occupa di tutte le operazioni client all'interno del cluster, il secondo mantiene sincronizzato con tutto il suo lavoro se è necessario il failover.
Il NameNode attivo tiene traccia dei metadati di ciascun blocco di dati e delle relative repliche. Ciò include il nome del file, l'autorizzazione, l'ID, la posizione e il numero di repliche. Mantiene tutte le informazioni in una fsimage , un'immagine dello spazio dei nomi archiviata nella memoria locale del file system. Inoltre, mantiene i registri delle transazioni chiamati EditLogs , che registrano tutte le modifiche apportate al sistema.
Lo scopo principale di Stanby NameNode è risolvere il problema del singolo punto di guasto. Legge tutte le modifiche apportate agli EditLogs e le applica al suo Spazio dei nomi (i file e le directory nei dati). Se il nodo master si guasta, il servizio Zookeeper esegue il failover consentendo allo standby di mantenere una sessione attiva.
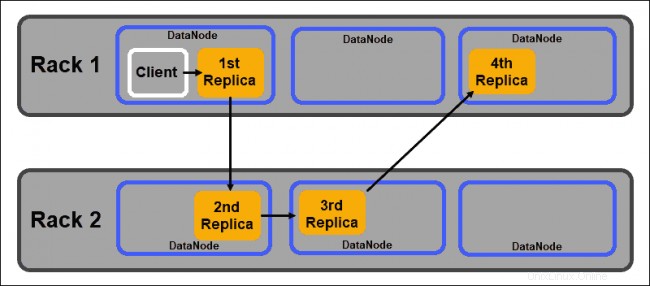
DataNode
I DataNode sono demoni slave che memorizzano i blocchi di dati assegnati dal NameNode. Come accennato in precedenza, le impostazioni predefinite assicurano che ogni blocco di dati abbia tre repliche. Puoi modificare il numero di repliche, tuttavia, non è consigliabile scendere sotto tre.
Le repliche devono essere distribuite in conformità con Rack Awareness di Hadoop politica che rileva che:
- Il numero di repliche deve essere maggiore del numero di rack.
- Un DataNode può memorizzare solo una replica di un blocco di dati.
- Un rack non può memorizzare più di due repliche di un blocco di dati.
Seguendo queste linee guida, puoi:
- Massimizza la larghezza di banda della rete.
- Proteggi dalla perdita di dati.
- Migliora prestazioni e affidabilità.
Caratteristiche principali di HDFS
Queste sono le caratteristiche principali del file system distribuito Hadoop:
Utilizzo nella vita reale di HDFS
Le aziende che si occupano di grandi volumi di dati hanno iniziato da tempo a migrare verso Hadoop, una delle soluzioni leader per l'elaborazione di big data grazie alle sue capacità di archiviazione e analisi.
Servizi finanziari. Il file system distribuito Hadoop è progettato per supportare i dati che dovrebbero crescere in modo esponenziale. Il sistema è scalabile senza il pericolo di rallentare complesse elaborazioni di dati.
Vendita al dettaglio. Poiché conoscere i propri clienti è una componente fondamentale per il successo nel settore della vendita al dettaglio, molte aziende conservano grandi quantità di dati strutturati e non strutturati sui clienti. Usano Hadoop per tracciare e analizzare i dati raccolti per aiutare a pianificare l'inventario futuro, i prezzi, le campagne di marketing e altri progetti.
Telecomunicazioni. L'industria delle telecomunicazioni gestisce enormi quantità di dati e deve elaborare su una scala di petabyte. Utilizza l'analisi Hadoop per gestire i record di dati delle chiamate, l'analisi del traffico di rete e altri processi relativi alle telecomunicazioni.
Industria energetica. L'industria energetica è sempre alla ricerca di modi per migliorare l'efficienza energetica. Si basa su sistemi come Hadoop e il suo file system per analizzare e comprendere i modelli e le pratiche di consumo.
Assicurazione. Le compagnie di assicurazione medica dipendono dall'analisi dei dati. Questi risultati servono come base per il modo in cui formulano e attuano le politiche. Per le compagnie di assicurazione, la conoscenza della storia del cliente è inestimabile. Avere la possibilità di mantenere un database facilmente accessibile mentre cresce continuamente è il motivo per cui così tanti si sono rivolti ad Apache Hadoop.