Introduzione
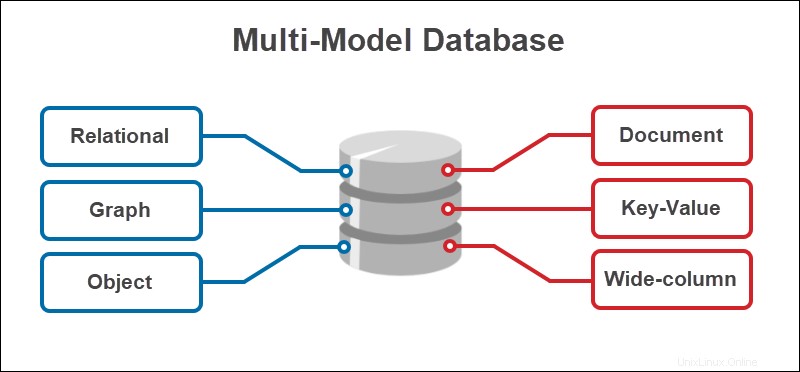
Database multimodello i sistemi di gestione uniscono più sistemi di database in uno. Invece di lavorare con numerosi modelli e trovare modi per incorporarli insieme, i database multimodello forniscono un unico motore per vari tipi di database.
Questo articolo offre una panoramica approfondita dei database multimodello.

Che cos'è un database multimodello?
Un database multimodello è un sistema di gestione che combina più tipi di database con un backend singolo. La maggior parte dei sistemi di gestione di database supporta un solo modello di database. D'altra parte, i database multimodello archiviano, interrogano e indicizzano dati da modelli diversi.
I database multimodello offrono i vantaggi di modellazione della persistenza poliglotta senza dover trovare il modo di combinare diversi modelli. L'approccio flessibile consente di archiviare i dati in diversi modi. Il risultato è:
- Programmazione agile e flessibile.
- Ridondanza dei dati ridotta.
Ad esempio, l'esplorazione delle relazioni tra punti dati o la creazione di un sistema di suggerimenti è molto più semplice con i database di grafici. D'altra parte, i database relazionali aiutano a definire le relazioni tra colonne di dati.
Una caratteristica fondamentale del database multimodello è la capacità di trasformare i dati da un formato all'altro. Ad esempio, i dati in formato JSON si trasformano rapidamente in XML. La conversione dei formati di dati offre ulteriore agilità e semplifica l'adempimento di specifici requisiti di progetto.
Esempi di casi d'uso di database multimodello
I casi d'uso aiutano a fornire un'idea di come funzionano i database multimodello. L'analisi di esempi pratici fornisce una migliore comprensione di come più modelli interagiscono in un unico sistema.
Memorizzazione e gestione di più origini dati
Un tipico sistema IT utilizza diverse origini dati. Le informazioni memorizzate non sono sempre nello stesso formato o database. Formati multipli creano un sistema complesso, rendendo difficile la manutenzione e la ricerca tra i dati.
L'archiviazione dei dati in un database multimodello semplifica l'amministrazione. Tutto è in un database, che riduce il tempo necessario per archiviare e gestire i dati da diverse origini.
Estensione delle funzionalità del modello
I database multimodello forniscono estensioni tra i modelli. Le caratteristiche di alcuni modelli aiutano a integrare le carenze di altri modelli.
Ad esempio, eseguire query sui dati in formato JSON utilizzando query SQL è semplice. Non è necessario modificare l'origine dati originale. L'estendibilità riduce i tempi di elaborazione dei dati ed elimina la necessità di sistemi di estrazione, trasformazione e caricamento (ETL).
Ambienti di dati ibridi
Un tipico ambiente dati mantiene i dati operativi separati da quelli analitici. I dati per l'analisi devono essere trasformati e archiviati in un luogo diverso dai dati operativi.
Le informazioni si duplicano, diminuendo la qualità dei dati. Allo stesso modo, lo spazio separato crea spese generali di manutenzione. Entrambi i database richiedono l'amministrazione dei criteri e la gestione del backup.
Un database multimodello fornisce un approccio ibrido all'archiviazione dei dati. È più semplice mantenere un hub dati unificato per l'archiviazione e l'estrazione di dati analitici.
Centralizzazione dei dati
I dati all'interno di un'organizzazione hanno barriere. Sebbene debbano esistere restrizioni, questo approccio impedisce l'utilizzo delle informazioni all'interno di un'azienda.
I database multimodello archiviano i dati così come sono senza la necessità di trasformazioni. La centralizzazione dei dati fornisce informazioni preziose sui dati esistenti, nonché l'opportunità di creare nuovi casi d'uso.
Ricerca nei Big Data
Hadoop è eccezionale nell'elaborazione di grandi quantità di dati diversi su modelli diversi. Il motivo principale è la velocità di ricezione, elaborazione e archiviazione di vari dati. Tuttavia, l'unica cosa che manca ad Hadoop è un meccanismo di ricerca efficiente.
Sfruttare la potenza di elaborazione di Hadoop e combinarla con la forza delle ricerche su database multimodello produce un sistema robusto. Il processo di lavoro con i dati diventa scalabile e robusto per le attività di big data.
Vantaggi e svantaggi del database multimodello
I database multimodello presentano vantaggi e svantaggi. La tabella fornisce il riepilogo:
| Pro | Contro |
|---|---|
| Dati coerenti | Complesso |
| Agile | Sviluppo |
| Conforme agli ACID | Manca di tecniche di modellazione |
| Adatto per progetti complessi | Non adatto a progetti semplici |
Il modello di database funziona principalmente in ambienti aziendali in cui sono presenti molti dati. Diversi settori utilizzano i dati per vari compiti. Tuttavia, una struttura di persistenza poliglotta già consolidata e specializzata noterà la mancanza di funzionalità nei database multimodello.
Vantaggi
I vantaggi dell'utilizzo di database multimodello sono:
- Coerenza dei dati tra i modelli grazie a un unico back-end.
- Diversi tipi di dati su un'unica piattaforma forniscono un ambiente agile.
- Tolleranza ai guasti grazie alla conformità ACID.
- Adatto per progetti complessi che richiedono più visualizzazioni di dati.
Svantaggi
Alcuni svantaggi dell'utilizzo di database multimodello sono:
- I sistemi di database multimodello sono difficili da utilizzare e complicati.
- Il modello di database è ancora in fase di sviluppo e non è maturato correttamente.
- La disponibilità di diverse tecniche di modellazione è limitata.
- Non adatto per sistemi o progetti più semplici.
Quali sono i migliori database multimodello?
Sul mercato sono disponibili diversi tipi di database multimodello. L'unica caratteristica distinguibile è il supporto per più modelli in un motore supportato.
Alcuni database sovrappongono più modelli al motore tramite i componenti. Tuttavia, questi tipi di database non sono autentici database multimodello.
Un'altra differenza fondamentale tra i database sono le tecniche di modellazione disponibili. Questo aspetto è essenziale per massimizzare l'utilità dei dati disponibili.
Server MarkLogic
Server MarkLogic è un database NoSQL multimodello che è iniziato come storage XLM e si è sviluppato ulteriormente per archiviare più formati di dati, come:
- Documento
- Grafico
- Testo
- Spaziale
- Valore-chiave
- Relazionale
Il database è versatile, efficiente e sicuro. Le caratteristiche di Mark Logic Server sono:
- Sicurezza e governance . Governance integrata sulla sicurezza dei dati e degli utenti.
- Conforme agli ACID . Forte coerenza dei dati grazie alla conformità ACID.
- Ricerca avanzata . Un motore di ricerca integrato con ricerca semantica che fornisce l'accesso ai dati.
- BI e analisi . Sono prontamente disponibili strumenti di analisi e business intelligence personalizzabili.
- Apprendimento automatico integrato . Gestione dei dati automatizzata in modo intelligente tramite algoritmi di apprendimento automatico incorporati, che forniscono un accesso più rapido ai dati.
- Tollerante ai guasti e resiliente . Mark Logic Server dispone di sistemi ad alta disponibilità e di ripristino di emergenza per evitare interruzioni.
- Supporto per il cloud ibrido . Il database consente la distribuzione autogestita tramite soluzioni cloud ibride.
ArangoDB
ArangoDB è un sistema di database nativo multimodello. I formati di dati supportati sono:
- Documento
- Grafico
- Valore-chiave
Il database recupera e modifica i dati attraverso un linguaggio di query unificato, AQL. Alcune delle altre caratteristiche degne di nota sono:
- Partecipazioni avanzate . Consente di unire i dati con query flessibili, riducendo la ridondanza dei dati.
- Transazioni . Esecuzione di query su più documenti con isolamento disponibile e coerenza transazionale.
- Sharding . La replica sincrona tramite sharding aiuta a ridurre la comunicazione interna del cluster, migliorando le prestazioni e la velocità di join.
- Replica. La replica fornisce un database distribuito all'interno di un data center.
- Multi-thread. Il database sfrutta più core tramite il multithreading.
OrientDB
OrientDB è un database NoSQL multimodello open source scritto in Java. Il database supporta i seguenti modelli:
- Documento
- Grafico
- Valore-chiave
- Oggetto
- Spaziale
OrientDB è stato il primo a presentare più modelli a livello di base. Il database include molte caratteristiche uniche, alcune delle quali sono:
- Supporto SQL . Le query in SQL sono supportate, rendendo più facile per i programmatori il passaggio dai modelli relazionali.
- Conforme agli ACID . Il database è completamente transazionale, fornendo affidabilità.
- Distribuito . Supporto completo per la replica multi-master su diversi server dedicati.
- Teleportabile . Consente l'importazione rapida di database relazionali.