Introduzione
Apache Hadoop è un framework di eccezionale successo che riesce a risolvere le numerose sfide poste dai big data. Questa soluzione efficiente distribuisce storage e potenza di elaborazione su migliaia di nodi all'interno di un cluster. Una piattaforma Hadoop completamente sviluppata include una raccolta di strumenti che migliorano il framework Hadoop di base e gli consentono di superare qualsiasi ostacolo.
L'architettura sottostante e il ruolo dei numerosi strumenti disponibili in un ecosistema Hadoop possono rivelarsi complicati per i nuovi arrivati.
Questo articolo utilizza numerosi diagrammi e descrizioni semplici per aiutarti a esplorare l'entusiasmante ecosistema di Apache Hadoop.

Panoramica dell'architettura Hadoop
I big data, con il loro volume immenso e le strutture dati variabili, hanno sopraffatto i framework e gli strumenti di rete tradizionali. L'uso di hardware ad alte prestazioni e server specializzati può aiutare, ma sono poco flessibili e hanno un prezzo considerevole.
Hadoop riesce a elaborare e archiviare grandi quantità di dati utilizzando hardware economico interconnesso a prezzi accessibili. Centinaia o addirittura migliaia di server dedicati a basso costo che lavorano insieme per archiviare ed elaborare i dati all'interno di un unico ecosistema.
Il file system distribuito Hadoop (HDFS), YARN e MapReduce sono al centro di quell'ecosistema. HDFS è un insieme di protocolli utilizzati per archiviare set di dati di grandi dimensioni, mentre MapReduce elabora in modo efficiente i dati in entrata.
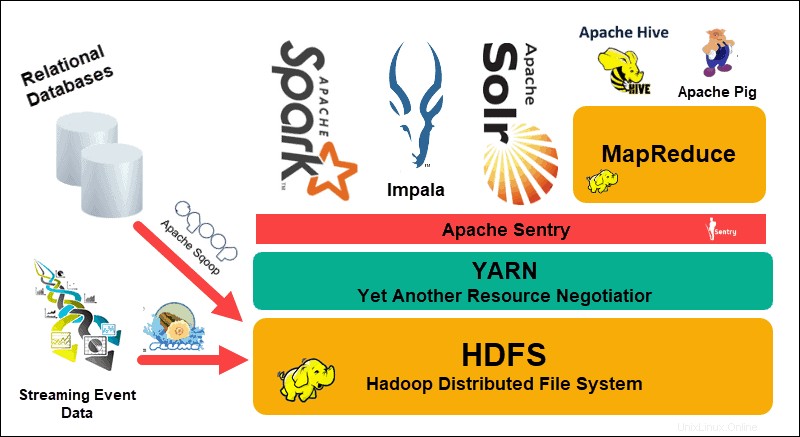
Un cluster Hadoop è costituito da uno o più nodi master e molti altri cosiddetti nodi slave. HDFS e MapReduce costituiscono una base flessibile che può essere scalata linearmente aggiungendo nodi aggiuntivi. Tuttavia, la complessità dei big data significa che c'è sempre spazio per miglioramenti.
Ancora un altro negoziatore di risorse (YARN) è stato creato per migliorare la gestione delle risorse e i processi di pianificazione in un cluster Hadoop. L'introduzione di YARN, con la sua interfaccia generica, ha aperto le porte ad altri strumenti di elaborazione dati da incorporare nell'ecosistema Hadoop.
Da allora una vivace comunità di sviluppatori ha creato numerosi progetti Apache open source per completare Hadoop. Molte di queste soluzioni hanno nomi accattivanti e creativi come Apache Hive, Impala, Pig, Sqoop, Spark e Flume. Questi strumenti compilano ed elaborano vari tipi di dati. Forniscono inoltre interfacce intuitive, servizi di messaggistica e migliorano le velocità di elaborazione dei cluster.
Uno stack software ampliato, con HDFS, YARN e MapReduce al centro, rende Hadoop la soluzione ideale per l'elaborazione di big data.
Capire i livelli dell'architettura Hadoop
La separazione degli elementi dei sistemi distribuiti in livelli funzionali aiuta a semplificare la gestione e lo sviluppo dei dati. Gli sviluppatori possono lavorare su framework senza avere un impatto negativo su altri processi sull'ecosistema più ampio.
Hadoop può essere suddiviso in quattro (4) livelli distintivi.
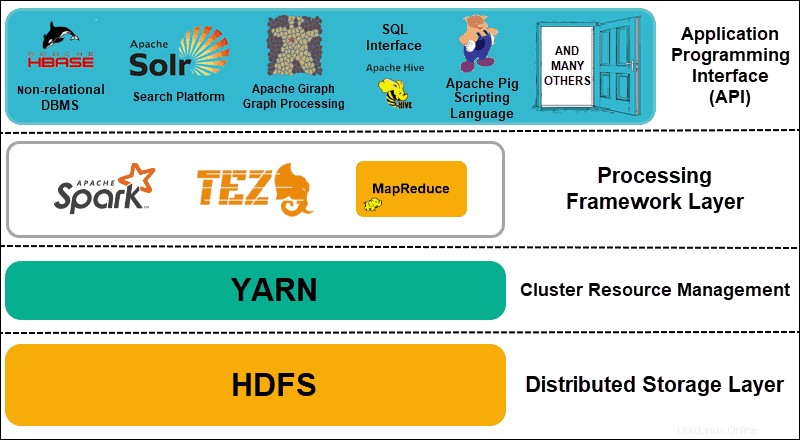
1. Livello di archiviazione distribuito
Ogni nodo in un cluster Hadoop dispone di spazio su disco, memoria, larghezza di banda ed elaborazione propri. I dati in entrata vengono suddivisi in singoli blocchi di dati, che vengono quindi archiviati all'interno del livello di archiviazione distribuito HDFS. HDFS presuppone che ogni unità disco e nodo slave all'interno del cluster sia inaffidabile. Per precauzione, HDFS memorizza tre copie di ciascun set di dati nel cluster. Il nodo master HDFS (NomeNode ) conserva i metadati per il singolo blocco di dati e tutte le relative repliche.
2. Gestione delle risorse del cluster
Hadoop ha bisogno di coordinare perfettamente i nodi in modo che innumerevoli applicazioni e utenti condividano efficacemente le proprie risorse. Inizialmente, MapReduce gestiva sia la gestione delle risorse che l'elaborazione dei dati. YARN separa queste due funzioni. In quanto strumento di gestione delle risorse di fatto per Hadoop, YARN è ora in grado di allocare risorse a diversi framework scritti per Hadoop. Questi includono progetti come Apache Pig, Hive, Giraph, Zookeeper e lo stesso MapReduce.
3. Strato quadro di elaborazione
Il livello di elaborazione è costituito da framework che analizzano ed elaborano i set di dati che entrano nel cluster. I set di dati strutturati e non strutturati vengono mappati, mischiati, ordinati, uniti e ridotti in blocchi di dati più piccoli e gestibili. Queste operazioni sono distribuite su più nodi il più vicino possibile ai server in cui si trovano i dati. Framework di calcolo come Spark, Storm, Tez ora consentono l'elaborazione in tempo reale, l'elaborazione interattiva delle query e altre opzioni di programmazione che aiutano il motore MapReduce e utilizzano HDFS in modo molto più efficiente.
4. Interfaccia di programmazione dell'applicazione
L'introduzione di YARN in Hadoop 2 ha portato alla creazione di nuovi framework di elaborazione e API. I big data continuano ad espandersi e la varietà di strumenti necessari per seguire tale crescita. I progetti incentrati su piattaforme di ricerca, streaming di dati, interfacce intuitive, linguaggi di programmazione, messaggistica, failover e sicurezza sono tutti una parte complessa di un ecosistema Hadoop completo.
Spiegazione dell'HDFS
Il file system distribuito Hadoop (HDFS) è a tolleranza di errore in base alla progettazione. I dati vengono archiviati in singoli blocchi di dati in tre copie separate su più nodi e rack di server. Se un nodo o anche un intero rack si guasta, l'impatto sul sistema più ampio è trascurabile.
DataNode elaborare e archiviare blocchi di dati, mentre NameNodes gestire i numerosi DataNode, mantenere i metadati dei blocchi di dati e controllare l'accesso dei client.
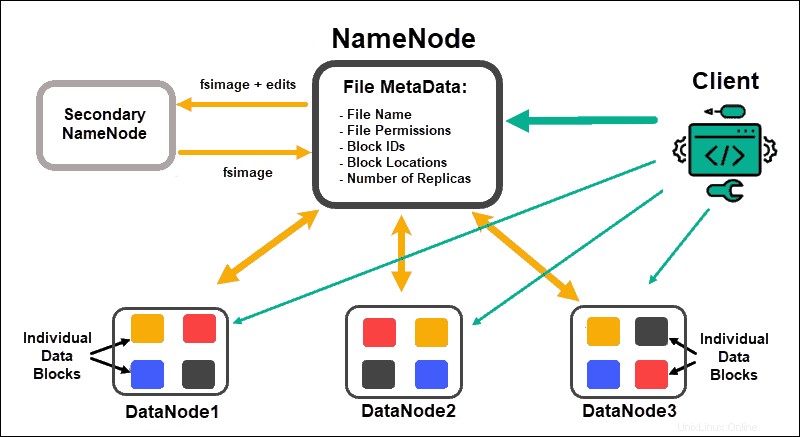
NomeNodo
Inizialmente, i dati sono suddivisi in blocchi di dati astratti. I metadati del file per questi blocchi, che includono il nome del file, i permessi del file, gli ID, le posizioni e il numero di repliche, sono archiviati in una fsimage, nella memoria locale di NameNode.
In caso di errore di un NameNode, HDFS non sarebbe in grado di individuare nessuno dei set di dati distribuiti nei DataNode. Ciò rende NameNode l'unico punto di errore per l'intero cluster. Questa vulnerabilità viene risolta implementando un NameNode secondario o uno Standby NameNode.
Nome secondario
Il NameNode secondario fungeva da soluzione di backup principale nelle prime versioni di Hadoop. Il NameNode secondario, ogni tanto, scarica l'istanza fsimage corrente e modifica i log dal NameNode e li unisce. L'immagine fs modificata può quindi essere recuperata e ripristinata nel NameNode primario.
Il failover non è un processo automatizzato poiché un amministratore dovrebbe recuperare i dati dal NameNode secondario manualmente.
Nome di attesa
L'alta disponibilità la funzionalità è stata introdotta in Hadoop 2.0 e versioni successive per evitare tempi di inattività in caso di errore NameNode. Questa funzione consente di mantenere due NameNode in esecuzione su nodi master dedicati separati.
Lo Standby NameNode è un failover automatico nel caso in cui un Active NameNode non sia disponibile. Lo Standby NameNode esegue inoltre il processo di check-point. A causa di questa proprietà, il NameNode secondario e Standby non sono compatibili. Un cluster Hadoop può mantenere l'uno o l'altro.
Custode dello zoo
Zookeeper è uno strumento leggero che supporta alta disponibilità e ridondanza. Uno Standby NameNode mantiene una sessione attiva con il demone Zookeeper.
Se un NameNode attivo vacilla, il demone Zookeeper rileva l'errore ed esegue il processo di failover su un nuovo NameNode. Usa Zookeeper per automatizzare i failover e ridurre al minimo l'impatto che un errore di NameNode può avere sul cluster.
DataNode
Ciascun DataNode in un cluster utilizza un processo in background per archiviare i singoli blocchi di dati su server slave.
Per impostazione predefinita, HDFS memorizza tre copie di ogni blocco di dati su DataNode separati. Il NameNode utilizza una politica di posizionamento compatibile con il rack. Ciò significa che i DataNode che contengono le repliche dei blocchi di dati non possono trovarsi tutti sullo stesso rack di server.
Un DataNode comunica e accetta istruzioni dal NameNode circa venti volte al minuto. Inoltre, segnala lo stato e l'integrità dei blocchi di dati situati su quel nodo una volta all'ora. Sulla base delle informazioni fornite, il NameNode può richiedere al DataNode di creare repliche aggiuntive, rimuoverle o ridurre il numero di blocchi di dati presenti sul nodo.
Norme sul posizionamento in base al rack
Uno degli obiettivi principali di un sistema di storage distribuito come HDFS è mantenere alta disponibilità e replica. Pertanto, i blocchi di dati devono essere distribuiti non solo su DataNode diversi, ma su nodi situati su rack di server diversi.
Ciò garantisce che il guasto di un intero rack non termini tutte le repliche dei dati. Il NameNode HDFS mantiene un criterio di posizionamento delle repliche predefinito compatibile con il rack:
- La prima replica del blocco di dati viene posizionata sullo stesso nodo del client.
- La seconda replica viene posizionata automaticamente su un DataNode casuale su un rack diverso.
- La terza replica viene collocata in un DataNode separato sullo stesso rack della seconda replica.
- Eventuali repliche aggiuntive vengono archiviate su DataNode casuali in tutto il cluster.
Questa politica di posizionamento del rack mantiene solo una replica per nodo e imposta un limite di due repliche per rack del server.
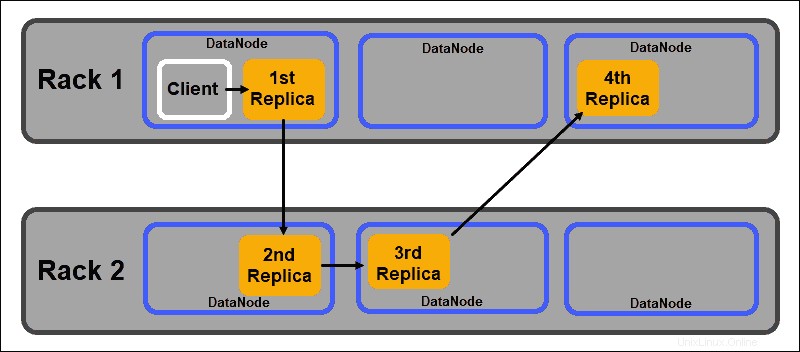
I guasti del rack sono molto meno frequenti dei guasti dei nodi. HDFS garantisce un'elevata affidabilità memorizzando sempre almeno una replica di blocchi di dati in un DataNode su un rack diverso.
Spiegazione del FILATO
YARN (Yet Another Resource Negotiator) è la risorsa di gestione del cluster predefinita per Hadoop 2 e Hadoop 3. Nelle versioni precedenti di Hadoop, MapReduce utilizzava sia l'elaborazione dei dati che l'allocazione delle risorse. Nel tempo, la necessità di dividere l'elaborazione e la gestione delle risorse ha portato allo sviluppo di YARN.
Il ruolo di allocazione delle risorse di YARN lo colloca tra il livello di archiviazione, rappresentato da HDFS, e il motore di elaborazione MapReduce. YARN fornisce anche un'interfaccia generica che consente di implementare nuovi motori di elaborazione per vari tipi di dati.
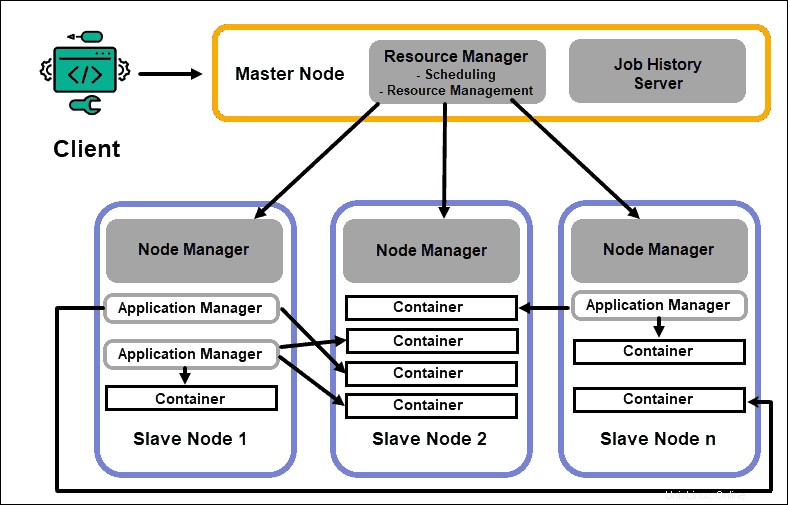
Gestione risorse
Il daemon ResourceManager (RM) controlla tutte le risorse di elaborazione in un cluster Hadoop. Il suo scopo principale è quello di designare le risorse per le singole applicazioni che si trovano sui nodi slave. Mantiene una panoramica globale dei processi in corso e pianificati, gestisce le richieste di risorse e pianifica e assegna le risorse di conseguenza. Il ResourceManager è vitale per il framework Hadoop e dovrebbe essere eseguito su un nodo master dedicato.
L'unico obiettivo di RM è la pianificazione dei carichi di lavoro. A differenza di MapReduce, non ha alcun interesse per i failover o le singole attività di elaborazione. Questa separazione delle attività in YARN è ciò che rende Hadoop intrinsecamente scalabile e lo trasforma in una piattaforma informatica completamente sviluppata.
Node Manager
Ogni nodo slave dispone di un servizio di elaborazione NodeManager e di un servizio di archiviazione DataNode. Insieme formano la spina dorsale di un sistema distribuito Hadoop.
Il DataNode, come accennato in precedenza, è un elemento di HDFS ed è controllato dal NameNode. Il NodeManager, in modo simile, funge da schiavo del ResourceManager. La funzione principale del demone NodeManager è tracciare i dati delle risorse di elaborazione sul suo nodo slave e inviare rapporti regolari al ResourceManager.
Contenitori
Le risorse di elaborazione in un cluster Hadoop vengono sempre distribuite in contenitori. Un contenitore ha memoria, file di sistema e spazio di elaborazione.
Una distribuzione del contenitore è generica e può eseguire qualsiasi risorsa personalizzata richiesta su qualsiasi sistema. Se una quantità richiesta di risorse del cluster rientra nei limiti di ciò che è accettabile, l'RM approva e pianifica la distribuzione del container.
I processi del contenitore su un nodo slave vengono inizialmente forniti, monitorati e tracciati da NodeManager su quel nodo slave specifico.
Applicazione Master
Ogni container su un nodo slave ha il suo Application Master dedicato. Anche gli Application Master vengono distribuiti in un container. Anche MapReduce ha un Application Master che esegue la mappa e riduce le attività.
Finché è attivo, un Application Master invia messaggi al Resource Manager sul suo stato attuale e sullo stato dell'applicazione che monitora. Sulla base delle informazioni fornite, il Resource Manager pianifica risorse aggiuntive o le assegna altrove nel cluster se non sono più necessarie.
L'Application Master supervisiona l'intero ciclo di vita di un'applicazione, dalla richiesta dei container necessari da RM all'invio delle richieste di locazione dei container al NodeManager.
Server Cronologia lavori
Il JobHistory Server consente agli utenti di recuperare informazioni sulle applicazioni che hanno completato la loro attività. L'API REST fornisce interoperabilità e può informare dinamicamente gli utenti sui lavori correnti e completati serviti dal server in questione.
Come funziona YARN?
Un flusso di lavoro di base per la distribuzione in YARN inizia quando un'applicazione client invia una richiesta a ResourceManager.
- Il Gestore delle risorse indica un NodeManager per avviare un Application Master per questa richiesta, che viene poi avviata in un container.
- Il nuovo Application Master si registra con il RM . L'Application Master procede a contattare il NomeNode HDFS e determina la posizione dei blocchi di dati necessari e calcola la quantità di mappa e riduce le attività necessarie per elaborare i dati.
- Il Application Master quindi richiede le risorse necessarie al RM e continua a comunicare i requisiti in termini di risorse durante tutto il ciclo di vita del contenitore.
- Il RM pianifica le risorse insieme alle richieste di tutti gli altri Application Master e mette in coda le loro richieste. Quando le risorse diventano disponibili, RM le rende disponibili all'Application Master su uno specifico nodo slave.
- Il Gestione applicazioni contatta il NodeManager per quel nodo slave e gli chiede di creare un contenitore fornendo variabili, token di autenticazione e la stringa di comando per il processo. Sulla base di tale richiesta, il NodeManager crea e avvia il contenitore .
- Il Gestione applicazioni quindi monitora il processo e reagisce in caso di errore riavviando il processo sul successivo slot disponibile. Se non riesce dopo quattro diversi tentativi, l'intero processo non riesce. Durante questo processo, l'Application Manager risponde alle richieste di stato del client.
Una volta completate tutte le attività, l'Application Master invia il risultato all'applicazione client, informa l'RM che l'applicazione ha completato la sua attività, si cancella dal Resource Manager e si spegne.
L'RM può anche indicare al NameNode di terminare un container specifico durante il processo in caso di modifica della priorità di elaborazione.
Spiegazione di MapReduce
MapReduce è un algoritmo di programmazione che elabora i dati dispersi nel cluster Hadoop. Come con qualsiasi processo in Hadoop, una volta avviato un lavoro MapReduce, il ResourceManager richiede un'applicazione master per gestire e monitorare il ciclo di vita del lavoro MapReduce.
L'Application Master individua i blocchi di dati richiesti in base alle informazioni memorizzate sul NameNode. L'AM informa inoltre ResourceManager di avviare un lavoro MapReduce sullo stesso nodo su cui si trovano i blocchi di dati. Quando possibile, i dati vengono elaborati localmente sui nodi slave per ridurre l'utilizzo della larghezza di banda e migliorare l'efficienza del cluster.
I dati di input vengono mappati, mescolati e quindi ridotti a un risultato aggregato. L'output del lavoro MapReduce viene archiviato e replicato in HDFS.
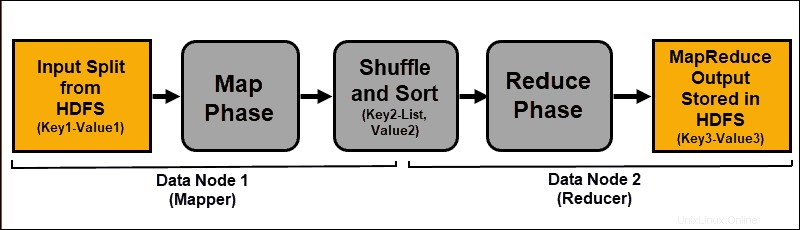
I server Hadoop che eseguono le attività di mappatura e riduzione sono spesso indicati come Mapper e Riduttori .
Il ResourceManager decide quanti mappatori utilizzare. Questa decisione dipende dalla dimensione dei dati elaborati e dal blocco di memoria disponibile su ciascun server di mappatura.
Fase Mappa
Il processo di mappatura acquisisce singole espressioni logiche dei dati archiviati nei blocchi di dati HDFS. Queste espressioni possono estendersi su più blocchi di dati e sono denominate divisioni di input . Le suddivisioni di input vengono introdotte nel processo di mappatura come coppie chiave-valore .
Un'attività di mappatura passa attraverso ogni coppia chiave-valore e crea un nuovo set di coppie chiave-valore, distinto dai dati di input originali. L'assortimento completo di tutte le coppie chiave-valore rappresenta l'output dell'attività di mappatura.
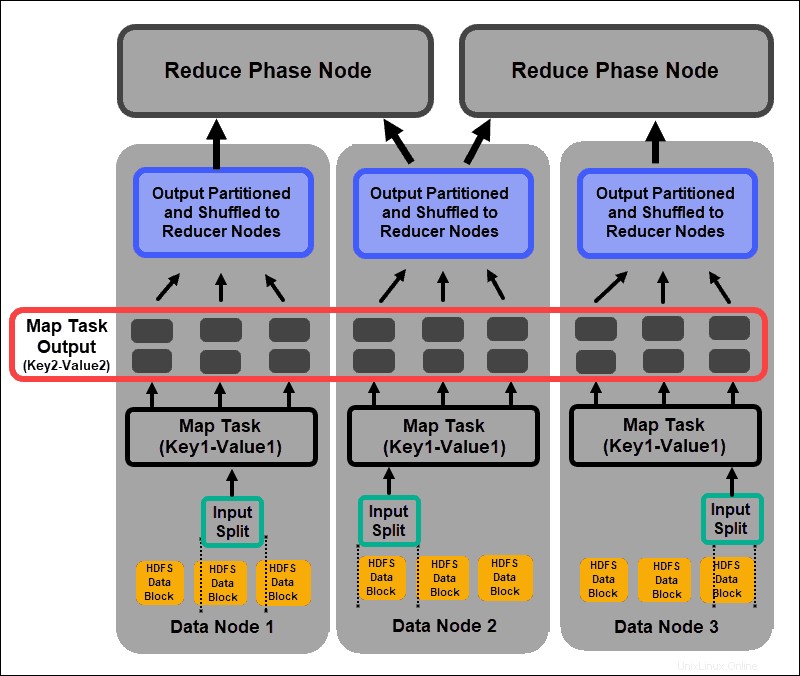
In base alla chiave di ciascuna coppia, i dati vengono raggruppati, partizionati e mischiati ai nodi riduttori.
Fase di mescolamento e smistamento
Rimescola è un processo in cui i risultati di tutte le attività della mappa vengono copiati nei nodi riduttore. La copia dell'output dell'attività di mappatura è l'unico scambio di dati tra i nodi durante l'intero processo di MapReduce.
L'output di un'attività di mappatura deve essere organizzato per migliorare l'efficienza della fase di riduzione. Le coppie chiave-valore mappate, mescolate dai nodi mapper, sono disposte in base alla chiave con i valori corrispondenti. Una fase di riduzione inizia dopo che l'input è stato ordinato per chiave in un unico file di input.
Le fasi di mescolamento e ordinamento si svolgono in parallelo. Anche se gli output della mappa vengono recuperati dai nodi del mappatore, vengono raggruppati e ordinati sui nodi del riduttore.
Fase di riduzione
Gli output della mappa vengono mescolati e ordinati in un unico file di input di riduzione situato sul nodo del riduttore. Una funzione di riduzione utilizza il file di input per aggregare i valori in base alle chiavi mappate corrispondenti. L'output del processo di riduzione è una nuova coppia chiave-valore. Questo risultato rappresenta l'output dell'intero processo MapReduce e, per impostazione predefinita, viene archiviato in HDFS.
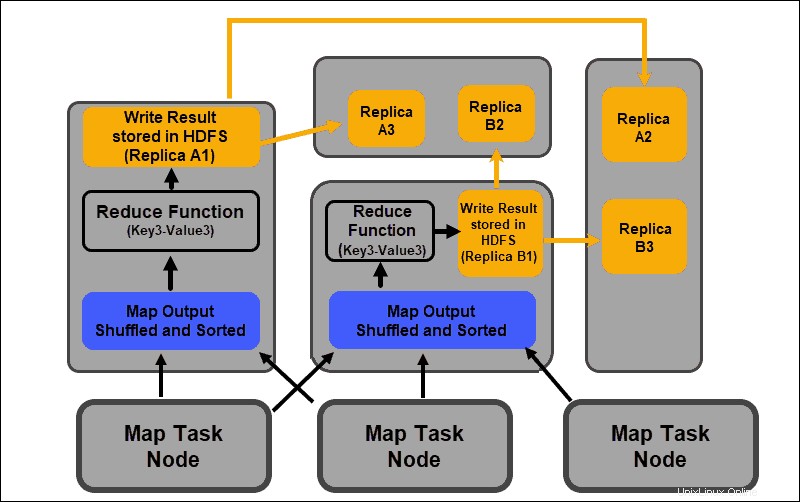
Tutte le attività di riduzione si svolgono simultaneamente e lavorano indipendentemente l'una dall'altra. Anche un'attività di riduzione è facoltativa.
Possono verificarsi casi in cui il risultato di un'attività sulla mappa è il risultato desiderato e non è necessario produrre un singolo valore di output.
Best practice per la distribuzione di Hadoop
La sezione seguente spiega in che modo l'hardware sottostante, le autorizzazioni utente e il mantenimento di un cluster bilanciato e affidabile possono aiutarti a ottenere di più dal tuo ecosistema Hadoop.
Regola le autorizzazioni utente Hadoop
Il protocollo di rete Kerberos è il principale sistema di autorizzazione in Hadoop. Assicura che solo i nodi e gli utenti verificati abbiano accesso e operino all'interno del cluster.
Dopo aver installato e configurato un centro di distribuzione chiavi Kerberos, è necessario apportare diverse modifiche ai file di configurazione di Hadoop. Hadoop core-site.xml file definisce i parametri per l'intero cluster Hadoop. Imposta il hadoop.security.authentication parametro all'interno di core-site.xml a kerberos . La stessa proprietà deve essere impostata su true per abilitare l'autorizzazione al servizio.
Elenchi di controllo degli accessi in hadoop-policy-xml il file può anche essere modificato per garantire diversi livelli di accesso a utenti specifici. Trovare un equilibrio tra i privilegi utente necessari e concedere troppi privilegi può essere difficile con gli strumenti di base della riga di comando.
È una buona idea utilizzare framework di sicurezza aggiuntivi come Apache Guardia ranger o Apache Sentinella . Questi strumenti consentono di gestire tutte le attività relative alla sicurezza da un ambiente centrale e intuitivo. Usali per fornire un'autorizzazione specifica per attività e utenti mantenendo il controllo completo sul processo.
Ammasso Hadoop bilanciato
Un sistema distribuito come Hadoop è un ambiente dinamico. L'aggiunta di nuovi nodi o la rimozione di quelli vecchi può creare uno squilibrio temporaneo all'interno di un cluster. I blocchi di dati possono diventare sottoreplicati.
Il tuo obiettivo è diffondere i dati nel modo più coerente possibile tra i nodi slave in un cluster. Utilizzare l'utilità di bilanciamento del cluster Hadoop per modificare le impostazioni predefinite. Definisci la tua politica di bilanciamento con il hdfs balancer comando. Questo comando e le sue opzioni consentono di modificare le soglie di capacità del disco del nodo.
La dimensione del blocco predefinita a partire da Hadoop 2.x è 128 MB. Hadoop consente a un utente di modificare questa impostazione. Prendere in considerazione la modifica della dimensione predefinita del blocco dati se si elaborano quantità considerevoli di dati; in caso contrario, il numero di lavori avviati potrebbe sovraccaricare il tuo cluster.
Se si aumenta la dimensione del blocco dati, l'input per l'attività della mappa sarà maggiore e verranno avviate meno attività della mappa. Questo, a sua volta, significa che la fase di shuffle ha un throughput molto migliore durante il trasferimento dei dati al nodo riduttore. Questa semplice regolazione può ridurre il tempo necessario per il completamento di un processo MapReduce.
Ridimensionamento di Hadoop (hardware)
Il NameNode è un elemento vitale del tuo cluster Hadoop. Coinvolgi il maggior numero possibile di core di elaborazione per questo nodo. La quantità di RAM definisce la quantità di dati letti dalla memoria del nodo. Se sovraccarichi le risorse disponibili per il tuo nodo principale, limiti la capacità del tuo cluster di crescere.
Gli alimentatori ridondanti devono essere sempre riservati al Master Node. Cerca di non utilizzare alimentatori ridondanti e preziose risorse hardware per i nodi dati. Sono una parte importante di un ecosistema Hadoop, tuttavia sono sacrificabili. I server dedicati convenienti, con capacità di elaborazione intermedie, sono ideali per i nodi di dati poiché consumano meno energia e producono meno calore.
Le capacità di ridimensionamento di Hadoop sono la principale forza trainante della sua implementazione diffusa. È necessario sempre disporre di spazio sufficiente per l'espansione del cluster. L'aggiunta rapida di nuovi nodi o spazio su disco richiede alimentazione, rete e raffreddamento aggiuntivi. Tutto ciò può rivelarsi molto difficile senza una pianificazione meticolosa per una probabile crescita futura.
Ridimensionamento di Hadoop (software)
Nuovi progetti Hadoop vengono sviluppati regolarmente e quelli esistenti vengono migliorati con funzionalità più avanzate.
Anche gli strumenti legacy vengono aggiornati per consentire loro di beneficiare di un ecosistema Hadoop. Tieni sempre d'occhio i nuovi sviluppi su questo fronte. La varietà e il volume dei set di dati in entrata impongono l'introduzione di framework aggiuntivi.
L'implementazione di un nuovo strumento intuitivo può risolvere un dilemma tecnico più rapidamente rispetto al tentativo di creare una soluzione personalizzata. Non rifuggire dalle soluzioni rapide commerciali già sviluppate. Il mercato è saturo di fornitori che offrono Hadoop-as-a-service o strumenti standalone su misura.
Affidabilità dei dati e tolleranza ai guasti
Hbattito cardiaco è un segnale di handshake TCP ricorrente. I DataNode, che si trovano su ogni server slave, inviano continuamente un heartbeat al NameNode che si trova sul server master. L'intervallo di tempo predefinito per l'heartbeat è di tre secondi. Se il NameNode non riceve un segnale per più di dieci minuti, cancella il DataNode e i suoi blocchi di dati vengono programmati automaticamente su nodi diversi.
Non abbassare la frequenza del battito cardiaco per cercare di alleggerire il carico sul NameNode. Tenere i NameNode "informati" è fondamentale, anche in cluster estremamente grandi. Senza un afflusso regolare e frequente di battiti cardiaci, il NameNode è gravemente ostacolato e non può controllare il cluster in modo altrettanto efficace.
Per evitare gravi conseguenze di guasti, mantenere le impostazioni di riconoscimento del rack predefinite e archiviare le repliche dei blocchi di dati nei rack dei server. Se perdi un server rack, le altre repliche sopravvivono e l'impatto sull'elaborazione dei dati è minimo.