Git è un software di controllo della versione distribuito che è stato sviluppato nel 2005 come strumento per semplificare lo sviluppo del kernel Linux, facilitando il coordinamento tra i programmatori. Oggi Git è diventato uno dei software di controllo delle versioni più popolari al mondo.
Git può essere utilizzato dall'interfaccia della riga di comando e consente di tenere traccia delle modifiche in qualsiasi insieme di dati. I vantaggi del software Git sono la sua alta velocità, l'integrità dei dati e il supporto del flusso di lavoro. Con Git ogni cartella di dati posizionata su qualsiasi dispositivo è un vero e proprio 'repository' completo di cronologia e possibilità di tracciare tutte le modifiche.
Questa guida spiegherà come installare e utilizzare Git sulle principali distribuzioni Linux, principalmente con riferimento a Ubuntu 18.04.
Per prima cosa, connettiti al tuo server tramite una connessione SSH. Se non l'hai ancora fatto, ti consigliamo di seguire la nostra guida per connetterti in sicurezza con il protocollo SSH. Nel caso di un server locale, vai al passaggio successivo e apri il terminale del tuo server.
Installazione di Git
Aggiorna i repository di distribuzione e avvia l'installazione di Git tramite apt-get:
$ apt-get update && apt-get install gitUna volta terminata la procedura, Git verrà installato. Per verificare la corretta installazione e la versione del software, utilizzare l'argomento "--version":
$ git –versionInfine, per iniziare a usare 'Git', configura le informazioni utente (nome e indirizzo email) che saranno associate a ogni pacchetto che crei:
$ git config --global user.name "Name Surname"$ git config --global user.email "[email protected]"D'ora in poi, questa guida si concentrerà sulla spiegazione delle varie funzionalità del software, riportando la sintassi di ogni comando. Queste diverse funzionalità sono state testate su Ubuntu, sebbene siano valide per qualsiasi altra distribuzione Linux.
Inizializzazione dell'area di lavoro
Lo scopo principale di Git è incoraggiare la collaborazione tra più flussi di lavoro su un determinato progetto. La prima cosa da fare, quindi, è inizializzare uno spazio di lavoro, creando un 'repository' locale vuoto o ottenendone uno da remoto.
Nel primo caso, per creare o reinizializzare un nuovo 'repository', utilizzare il comando "init":
$ git initQuesto comando creerà una cartella '.git' che conterrà tutti i file necessari per il 'repository'. La cartella conterrà tutti i file che compongono il progetto da tracciare. Inizialmente tutti i nuovi file non verranno tracciati, vale a dire che non verranno tracciati. Ciò significa che non verranno presi in considerazione durante il caricamento dello snapshot.
Se vuoi iniziare a tenere traccia dei file usa il comando 'add', seguito da un "commit" o una breve indicazione di cosa stai includendo :
$ git add <FilePath/FileName>$ git commit -m ‘<Description>’In Fig. 1 un esempio di inizializzazione di un nuovo 'repository' e un'inclusione del file 'FileTestA', oltre a,. vengono mostrati gli output dal terminale che riportano l'esito positivo dell'operazione.
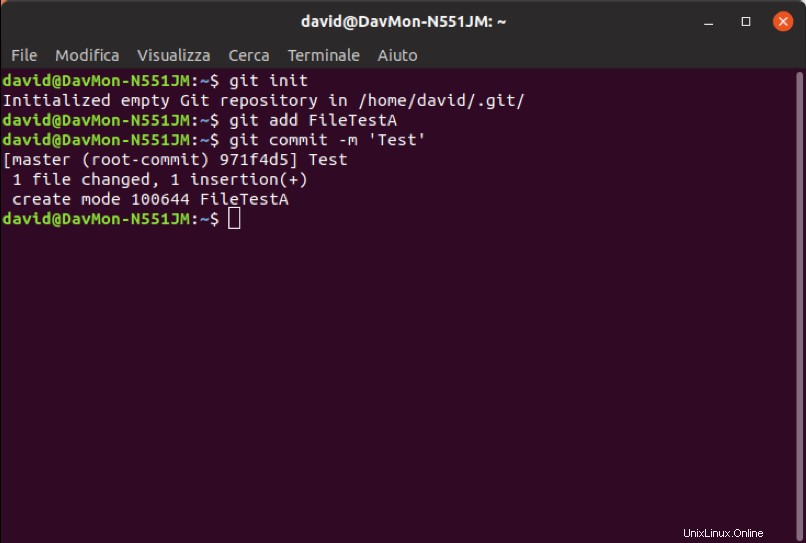
Fig. 1 - Esempio di inizializzazione e monitoraggio Git su Ubuntu Terminal 18.04
Se, invece, vuoi contribuire a un "repository" già esistente usa il comando "clone". Con questo comando Git riceve una copia di tutte le versioni dei file di progetto presenti sul server indicato:
$ git clone <URL> <Destination_Folder>Invece di
Per quanto riguarda l'URL, ci sono più protocolli di trasferimento che possono essere utilizzati da Git per scaricare i "repository":
· Protocollo Git (git://);
Protocollo HTTP (http:// o https://);
Protocollo SSH (ssh://);
Utente e server (nome utente @ server:/path.git).
Salvataggio e gestione temporanea
Ogni file nella cartella di lavoro può avere lo stato di "non tracciato", "tracciato", "non modificato" e "modificato". Come mostrato nel paragrafo precedente, i file con lo stato "non tracciato" sono tutti i file nella directory di lavoro che non sono presenti nello snapshot (quando si crea un nuovo "repository").
Quando si clona un "repository" esistente ', invece, viene "tracciato" lo stato di base di tutti i file scaricati. Questi file, quindi, possono anche essere "non modificati" se non modificati dopo il download, o "modificati" se modificati dall'ultimo commit.
Per controllare lo stato di un file, usa il comando 'status':
$ git statusL'immagine seguente mostra uno screenshot del terminale dove è stato inizializzato un nuovo progetto, è stato aggiunto un file ed è stato creato un primo commit. Utilizzando il comando "status", il terminale specifica che non vi è alcun file modificato da aggiornare. Dalla linea verde in poi, dopo aver modificato il file, viene eseguito nuovamente il comando 'stato'.
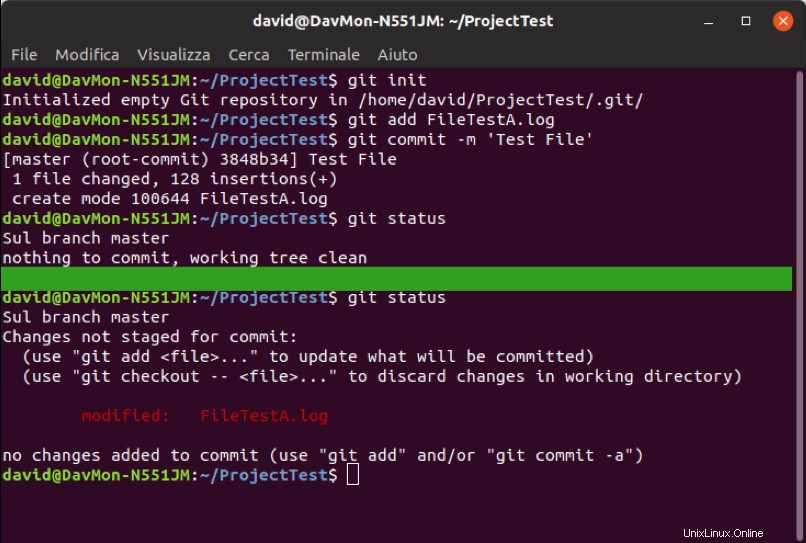
Fig. 2 - Esempio di inizializzazione, monitoraggio e modifica del file Git su Ubuntu Terminal 18.04
Il file appena modificato ora appare sotto l'intestazione "Modifiche non organizzate per il commit", il che significa che un file tracciato ha subito una modifica nella cartella di lavoro ma non è ancora sullo stage.
Sarà quindi possibile procedere in due modi diversi:
Aggiornare il file sullo stage (sarà necessario ripetere la procedura di tracking, ovvero al comando 'git add');
Annulla le modifiche (usando "git checkout
).
Supponiamo di voler mettere in scena il file appena modificato eseguendo il comando 'git add' e ripetendo 'git status' per valutarne lo stato.
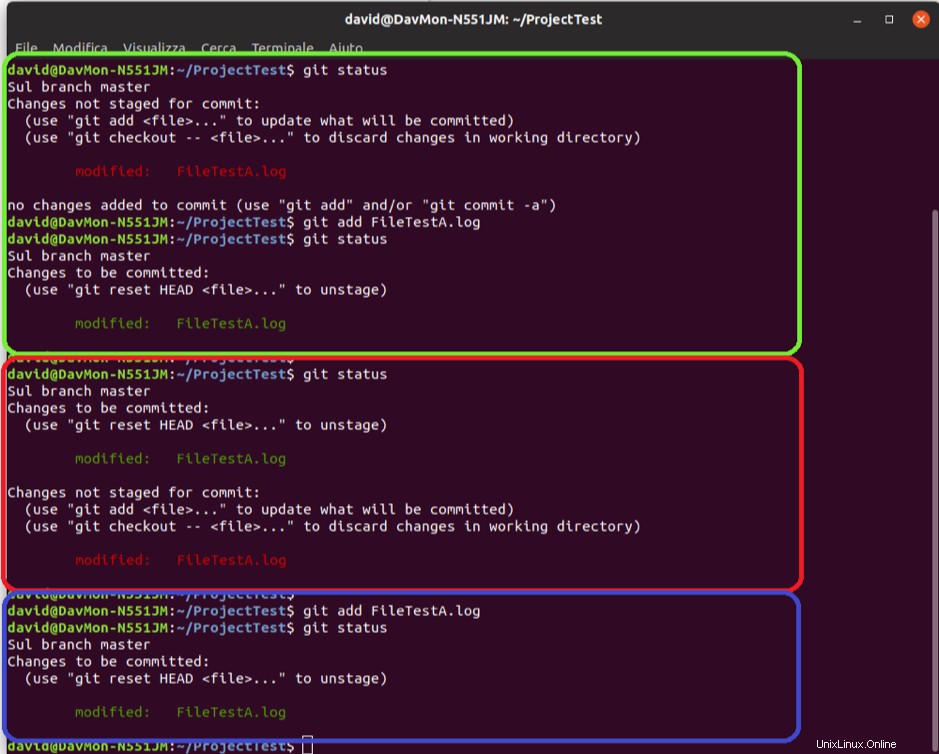
Fig. 3 - Fase dei file modificati su Ubuntu Terminal 18.04
Il file verrà quindi modificato ma pronto per il commit (rettangolo verde in figura 3). Se, prima del commit, viene apportata un'ulteriore modifica al file e ne viene verificato lo stato, entrambi verranno indicati come file 'pronto per il commit' e come file non ancora in stage (rettangolo rosso in figura 3).
Ciò accade perché il file sullo stage è quello senza modifiche (quello che verrà eseguito il commit, se ora viene eseguito il comando "commit"), mentre quello esterno è quello appena modificato. Per confermare questa ulteriore modifica, aggiungila ancora una volta (rettangolo blu in figura 3).
Ignora i file
Se non vuoi che determinati file vengano aggiunti automaticamente, ad esempio i file 'log', crea un file ".gitignore" con all'interno un elenco dei file che vuoi escludere.
Per includere automaticamente un certo tipo di pattern, non elencare tutti i singoli file da ignorare, includere tutte le cartelle e utilizzare caratteri speciali. Le regole per i modelli sono:
- Le righe vuote o le righe che iniziano con "#" vengono automaticamente ignorate;
- Le barre "/" possono essere utilizzate per indicare una sottocartella;
- Usa “!” Carattere per rifiutare uno schema;
- È possibile utilizzare pattern glob.
Un pattern glob è una sintassi usata per rappresentare un insieme di stringhe. I più comuni sono:
- l'asterisco (*) che indica qualsiasi stringa (spesso usata per contrassegnare tutti i file di una certa estensione);
- il punto interrogativo (?) che indica qualsiasi carattere e le parentesi quadre ([…]) per specificare una serie di caratteri o numeri.
Imposta modifica
Una volta che i file sono stati posizionati sullo stage (tramite il comando "git add"), esegui il commit delle modifiche. Il commit viene utilizzato per registrare l'istantanea salvata nell'area dello stage.
Tutto ciò che non è posizionato sullo stage, non sarà nel commit ma rimarrà ovviamente modificato nella cartella locale.
Il modo più semplice per eseguire il commit è utilizzare il seguente comando:
$ git commitCosì facendo si aprirà l'editor di testo che mostra l'ultimo output del comando 'git' status con la prima riga vuota:qui è possibile inserire il proprio messaggio di commit, in modo da indica in modo appropriato quali modifiche stai apportando.
Hai appena creato il tuo primo commit! Prima di concludere la guida verranno illustrate le procedure per ulteriori rimozioni o modifiche dei file.
Rimozione dei file
Per rimuovere un file Git, non solo rimuoverlo dai file tracciati, ma ripetere nuovamente il commit per salvare le modifiche. Infatti, semplicemente cancellando il file dalla cartella, il file risultante apparirà come un file non in scena.
Utilizzando il comando 'git rm' seguito dal percorso e dal nome del file, la rimozione del file verrà eseguita in modo graduale e scomparirà completamente dopo il prossimo commit:
$ git rm <File>Se hai già modificato e aggiunto il file all'indice, puoi forzarne la rimozione aggiungendo l'opzione "-f":
$ git rm -f <File>Se, invece, vuoi solo rimuovere un file inserito erroneamente sullo stage mantenendolo sul disco, puoi utilizzare l'opzione "--cached":
$ git rm --cached <File>Spostare e rinominare i file
Un'altra cosa che potresti voler fare è spostare o rinominare i file. Questa non è un'operazione automatica, in quanto Git non tiene traccia in modo esplicito dei movimenti dei file, ovvero non vengono generati metadati per tenere traccia dell'opzione "rinomina".
Questa operazione può essere eseguita con i comandi conosciuti, cambiando prima il nome e rimuovendo il file 'precedente' (git rm) da Git, quindi aggiungendo il 'nuovo' (git add).
Per evitare di eseguire questa serie di comandi per ogni rinomina/mossa, Git ha il suo comando specifico, "git mv", che fornisce lo stesso risultato dei tre sopra elencati contemporaneamente.
La sintassi completa è mostrata di seguito:
$ git mv <OldPath/OldName> <NewPath/NewName>Questo comando fornisce esattamente lo stesso risultato dei tre seguenti:
$ mv <OldPath/OldName> <NewPath/NewName>
$ git rm <OldPath/OldName>
$ git add <NewPath/NewName>Così facendo il file verrà rinominato e/o spostato e già sullo stage, pronto per il commit. Per verificare la riuscita dell'operazione eseguire il comando 'git status' che rilascerà una sezione chiamata 'rinominato' nell'elenco delle modifiche da confermare, dove verranno elencati tutti i file che hanno cambiato nome o percorso. Per ogni file, specificare sia il nome/percorso precedente che quello attuale.