Introduzione
Apache Spark è un framework computazionale distribuito open source che è_creato per fornire risultati computazionali più veloci.
È un motore di calcolo in memoria, il che significa che i dati verranno elaborati in memoria.
Scintilla supporta varie API per lo streaming, l'elaborazione di grafici, SQL, MLLib. Supporta anche Java, Python, Scala e R come linguaggi preferiti. Spark è installato principalmente nei cluster Hadoop, ma puoi anche installare e configurare Spark in modalità standalone.
In questo articolo vedremo come installare Apache Spark in Debian e Ubuntu distribuzioni basate su.
Installa Java in Ubuntu
Per installare Apache Spark in Ubuntu, devi avere Java installato sulla tua macchina. La maggior parte delle moderne distribuzioni viene fornita con Java installato per impostazione predefinita e puoi verificarlo utilizzando il comando seguente.
$ java -version
Se nessun output, puoi installare Java usando il nostro articolo su come installare Java su Ubuntu o semplicemente eseguire i seguenti comandi per installare Java su Ubuntu e distribuzioni basate su Debian.
$ sudo apt update
$ sudo apt install default-jre
$ java -versionInstalla Scala in Ubuntu
Successivamente, puoi installare Scala dal repository apt eseguendo i seguenti comandi per cercare scala e installarlo.
Cerca il pacchetto
$ sudo apt search scalaInstalla il pacchetto
$ sudo apt install scala -yPer verificare l'installazione di Scala , esegui il comando seguente.
$ scala -version 
Installa Apache Spark in Ubuntu
Ora vai alla pagina di download ufficiale di Apache Spark e prendi l'ultima versione (cioè 3.1.2) al momento della stesura di questo articolo. In alternativa, puoi usare il comando wget per scaricare il file direttamente nel terminale.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Ora apri il tuo terminale e passa alla posizione in cui è posizionato il tuo file scaricato ed esegui il seguente comando per estrarre il file tar di Apache Spark.
$ tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz 
Infine, sposta la Spark estratta directory in /opt directory.
sudo mv spark-3.1.2-bin-hadoop3.2 /opt/sparkConfigura variabili per Spark
Ora devi impostare alcune variabili ambientali nel tuo .profile file prima di avviare la scintilla.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profilePer assicurarsi che queste nuove variabili di ambiente siano raggiungibili all'interno della shell e disponibili per Apache Spark, è anche obbligatorio eseguire il comando seguente per rendere effettive le modifiche recenti.
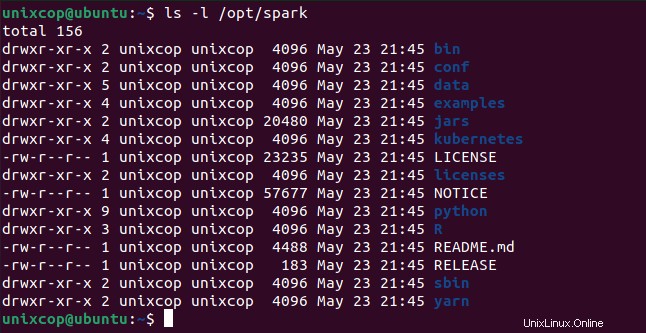
$ source ~/.profileTutti i binari relativi a spark per avviare e arrestare i servizi sono sotto sbin cartella.
$ ls -l /opt/spark
Avvia Apache Spark in Ubuntu
Esegui il comando seguente per avviare Spark servizio principale e servizio secondario.
$ start-master.sh
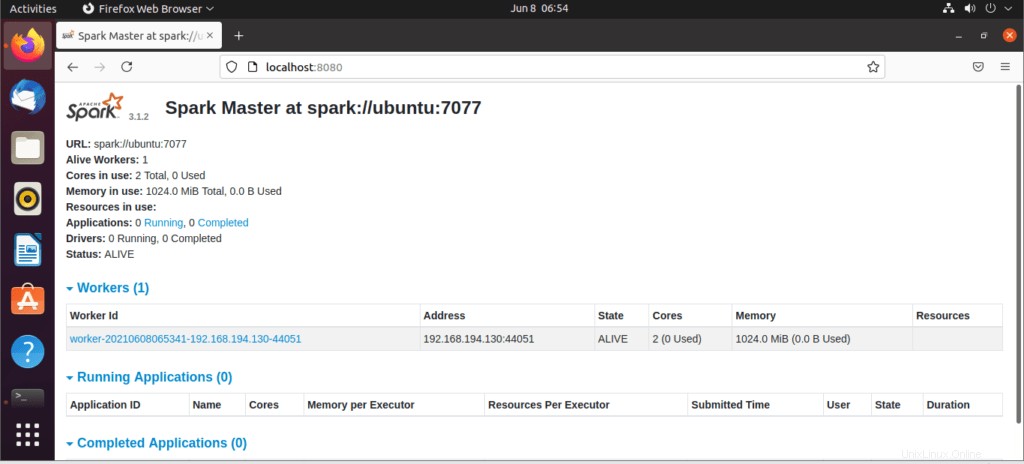
Una volta avviato il servizio, vai al browser e digita il seguente URL access page spark. Dalla pagina, puoi vedere che il mio servizio principale è avviato.
http://localhost:8080/Quindi puoi aggiungere un lavoratore con questo comando:
$ start-workers.sh spark://localhost:7077
Il lavoratore verrà aggiunto come mostrato:
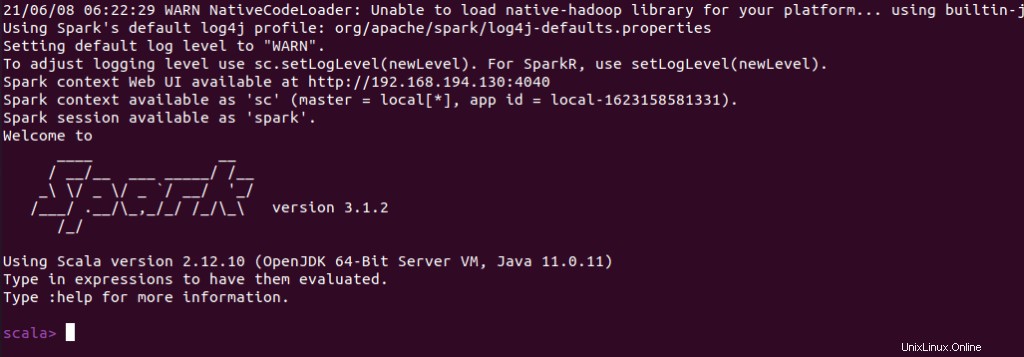
Puoi anche controllare se spark-shell funziona correttamente avviando spark-shell comando.
$ spark-shell