Apache Spark è un framework computazionale open source per dati analitici su larga scala e elaborazione di machine learning. Supporta vari linguaggi preferiti come scala, R, Python e Java. Fornisce strumenti di alto livello per lo spark streaming, GraphX per l'elaborazione di grafici, SQL, MLLib.
In questo articolo imparerai come installare e configurare Apache Spark su Ubuntu. Per dimostrare il flusso in questo articolo ho usato il sistema della versione LTS di Ubuntu 20.04. Prima di installare Apache Spark devi installare Scala e scala sul tuo sistema.
Installazione di Scala
Se non hai installato Java e Scala puoi seguire la seguente procedura per installarlo.
Per Java, installeremo JDK 8 aperto oppure puoi installare la tua versione preferita.
$ sudo apt update
$ sudo apt install openjdk-8-jdk
Se hai bisogno di verificare l'installazione di java puoi eseguire il seguente comando.
$ java -version

Come per Scala, scala è un linguaggio di programmazione orientato agli oggetti e funzionale che lo combina in un unico conciso. Scala è compatibile sia con il runtime javascript che con JVM e ti garantisce un facile accesso all'ecosistema di librerie di grandi dimensioni che aiuta nella creazione di sistemi ad alte prestazioni. Esegui il seguente comando apt per installare scala.
$ sudo apt update
$ sudo apt install scala
Ora controlla la versione per verificare l'installazione.
$ scala -version

Installazione di Apache Spark
Non esiste un repository apt ufficiale per installare apache-spark ma puoi precompilare il binario dal sito ufficiale. Usa il seguente comando e link wget per scaricare il file binario.
$ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Ora estrai il file binario scaricato usando il seguente comando tar.
$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
Infine, sposta i file spark estratti nella directory /opt.
$ sudo mv spark-3.1.2-bin-hadoop3.2 /opt/spark
Impostazione delle variabili d'ambiente
La tua variabile di percorso per spark nel tuo .profile nel file necessario per impostare affinché il comando funzioni senza un percorso completo, puoi farlo usando il comando echo o farlo manualmente usando un editor di testo preferibile. Per un modo più semplice, esegui il seguente comando echo.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
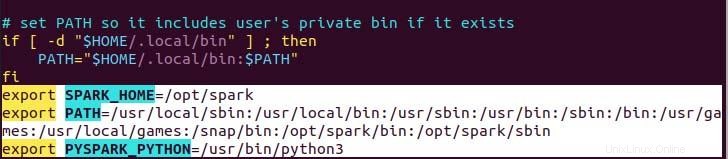
Come puoi vedere, la variabile del percorso viene aggiunta nella parte inferiore del file .profile usando echo con>> operazione.
Ora, esegui il comando seguente per applicare le nuove modifiche alle variabili di ambiente.
$ source ~/.profile
Distribuzione di Apache Spark
Ora, abbiamo impostato tutto ciò che possiamo eseguire sia il servizio principale che il servizio di lavoro utilizzando il seguente comando.
$ start-master.sh
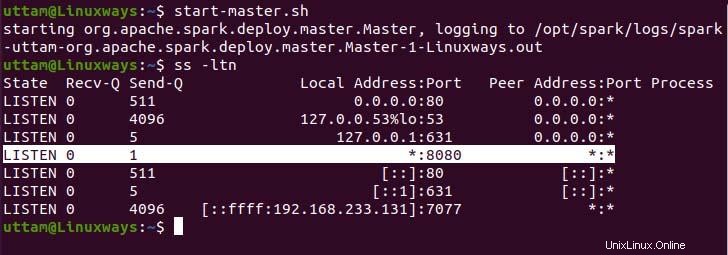
Come puoi vedere, il nostro servizio spark master è in esecuzione sulla porta 8080. Se sfogli il localhost sulla porta 8080 che è la porta predefinita di spark. È possibile che si verifichi il seguente tipo di interfaccia utente durante la navigazione nell'URL. Potresti non trovare alcun processore di lavoro in esecuzione avviando solo il servizio master. Quando avvii il servizio di lavoro troverai un nuovo nodo elencato proprio come nell'esempio seguente.
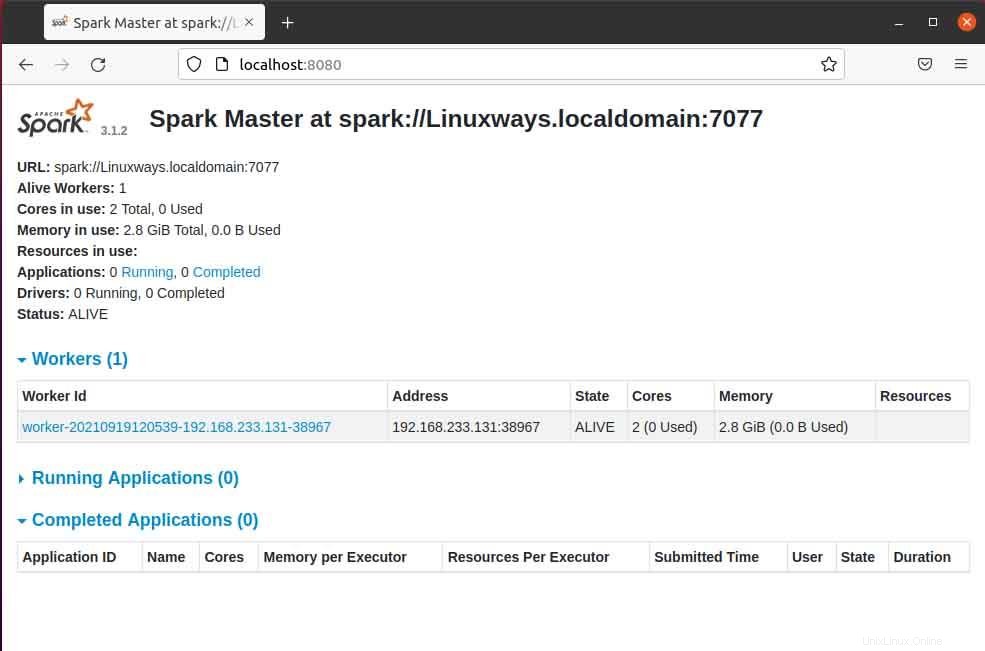
Quando apri la pagina master nel browser, puoi vedere spark master spark://HOST:URL PORTA che viene utilizzato per connettere i servizi di lavoro tramite questo host. Per il mio host attuale il mio URL spark master è spark://Linuxways.localdomain:7077 quindi è necessario eseguire il comando nel modo seguente per avviare il processo di lavoro.
$ start-workers.sh <spark-master-url>
Per eseguire il comando seguente per eseguire i servizi di lavoro.
$ start-workers.sh spark://Linuxways.localdomain:7077

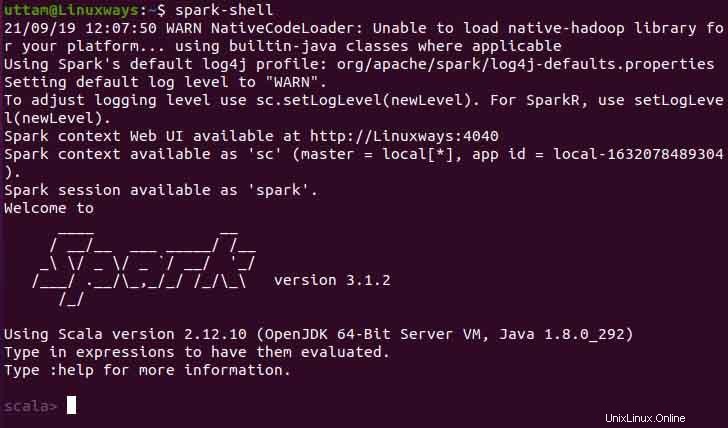
Inoltre, puoi usare spark-shell eseguendo il comando seguente.
$ spark-shell
Conclusione
Spero che da questo articolo impari come installare e configurare Apache Spark su Ubuntu. In questo articolo, ho cercato di rendere il processo il più comprensibile possibile.