Apache Hadoop è un framework open source utilizzato per gestire, archiviare ed elaborare dati per varie applicazioni di big data in esecuzione in sistemi cluster. È scritto in Java con del codice nativo in C e script di shell. Utilizza un file system distribuito (HDFS) e scala da server singoli a migliaia di macchine.
Apache Hadoop si basa sui quattro componenti principali:
- Hadoop comune : È la raccolta di utilità e librerie necessarie ad altri moduli Hadoop.
- HDFS: Conosciuto anche come Hadoop Distributed File System distribuito su più nodi.
- Riduci mappa: È un framework utilizzato per scrivere applicazioni per elaborare enormi quantità di dati.
- FILATO Hadoop : Conosciuto anche come Yet Another Resource Negotiator è il livello di gestione delle risorse di Hadoop.
In questo tutorial spiegheremo come configurare un cluster Hadoop a nodo singolo su Ubuntu 20.04.
Prerequisiti
- Un server che esegue Ubuntu 20.04 con 4 GB di RAM.
- Sul tuo server è configurata una password di root.
Aggiorna i pacchetti di sistema
Prima di iniziare, si consiglia di aggiornare i pacchetti di sistema all'ultima versione. Puoi farlo con il seguente comando:
apt-get update -y
apt-get upgrade -y
Una volta aggiornato il sistema, riavvialo per implementare le modifiche.
Installa Java
Apache Hadoop è un'applicazione basata su Java. Quindi dovrai installare Java nel tuo sistema. Puoi installarlo con il seguente comando:
apt-get install default-jdk default-jre -y
Una volta installato, puoi verificare la versione installata di Java con il seguente comando:
java -version
Dovresti ottenere il seguente output:
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
Crea utente Hadoop e imposta SSH senza password
Innanzitutto, crea un nuovo utente chiamato hadoop con il seguente comando:
adduser hadoop
Quindi, aggiungi l'utente hadoop al gruppo sudo
usermod -aG sudo hadoop
Quindi, accedi con l'utente hadoop e genera una coppia di chiavi SSH con il seguente comando:
su - hadoop
ssh-keygen -t rsa
Dovresti ottenere il seguente output:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno [email protected] The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
Quindi, aggiungi questa chiave alle chiavi ssh autorizzate e dai il permesso appropriato:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
Successivamente, verifica l'SSH senza password con il seguente comando:
ssh localhost
Una volta effettuato l'accesso senza password, puoi procedere al passaggio successivo.
Installa Hadoop
Innanzitutto, accedi con l'utente hadoop e scarica l'ultima versione di Hadoop con il seguente comando:
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Una volta completato il download, estrai il file scaricato con il seguente comando:
tar -xvzf hadoop-3.2.1.tar.gz
Quindi, sposta la directory estratta in /usr/local/:
sudo mv hadoop-3.2.1 /usr/local/hadoop
Quindi, crea una directory in cui archiviare il registro con il seguente comando:
sudo mkdir /usr/local/hadoop/logs
Quindi, cambia la proprietà della directory hadoop in hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
Successivamente, dovrai configurare le variabili di ambiente Hadoop. Puoi farlo modificando il file ~/.bashrc:
nano ~/.bashrc
Aggiungi le seguenti righe:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Salva e chiudi il file quando hai finito. Quindi, attiva le variabili d'ambiente con il seguente comando:
source ~/.bashrc
Configura Hadoop
In questa sezione impareremo come configurare Hadoop su un singolo nodo.
Configura variabili d'ambiente Java
Successivamente, dovrai definire le variabili di ambiente Java in hadoop-env.sh per configurare le impostazioni del progetto relative a YARN, HDFS, MapReduce e Hadoop.
Innanzitutto, individua il percorso Java corretto utilizzando il seguente comando:
which javac
Dovresti vedere il seguente output:
/usr/bin/javac
Quindi, trova la directory OpenJDK con il seguente comando:
readlink -f /usr/bin/javac
Dovresti vedere il seguente output:
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
Quindi, modifica il file hadoop-env.sh e definisci il percorso Java:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Aggiungi le seguenti righe:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Successivamente, dovrai anche scaricare il file di attivazione Javax. Puoi scaricarlo con il seguente comando:
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Ora puoi verificare la versione di Hadoop usando il seguente comando:
hadoop version
Dovresti ottenere il seguente output:
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
Configura file core-site.xml
Successivamente, dovrai specificare l'URL per il tuo NameNode. Puoi farlo modificando il file core-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Aggiungi le seguenti righe:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Salva e chiudi il file quando hai finito:
Configura file hdfs-site.xml
Successivamente, sarà necessario definire la posizione in cui archiviare i metadati del nodo, il file fsimage e il file di registro di modifica. Puoi farlo modificando il file hdfs-site.xml. Innanzitutto, crea una directory per la memorizzazione dei metadati del nodo:
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs Quindi, modifica il file hdfs-site.xml e definisci la posizione della directory:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Aggiungi le seguenti righe:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Salva e chiudi il file.
Configura file mapred-site.xml
Successivamente, dovrai definire i valori di MapReduce. Puoi definirlo modificando il file mapred-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Aggiungi le seguenti righe:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Salva e chiudi il file.
Configura file yarn-site.xml
Successivamente, dovrai modificare il file yarn-site.xml e definire le impostazioni relative a YARN:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Aggiungi le seguenti righe:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Salva e chiudi il file quando hai finito.
Formatta NameNode HDFS
Successivamente, dovrai convalidare la configurazione di Hadoop e formattare il NameNode HDFS.
Innanzitutto, accedi con l'utente Hadoop e formatta il NameNode HDFS con il seguente comando:
su - hadoop
hdfs namenode -format
Dovresti ottenere il seguente output:
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
Avvia il cluster Hadoop
Innanzitutto, avvia NameNode e DataNode con il seguente comando:
start-dfs.sh
Dovresti ottenere il seguente output:
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
Quindi, avvia la risorsa YARN e i nodemanager eseguendo il comando seguente:
start-yarn.sh
Dovresti ottenere il seguente output:
Starting resourcemanager Starting nodemanagers
Ora puoi verificarli con il seguente comando:
jps
Dovresti ottenere il seguente output:
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
Accedi all'interfaccia Web Hadoop
Ora puoi accedere a Hadoop NameNode utilizzando l'URL http://your-server-ip:9870. Dovresti vedere la seguente schermata:
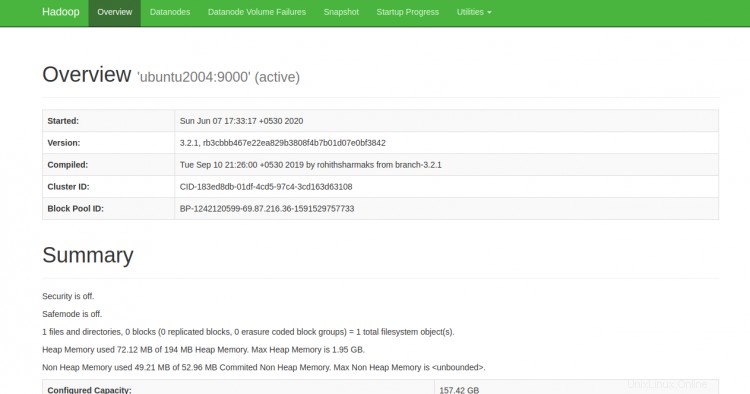
È inoltre possibile accedere ai singoli DataNode utilizzando l'URL http://your-server-ip:9864. Dovresti vedere la seguente schermata:
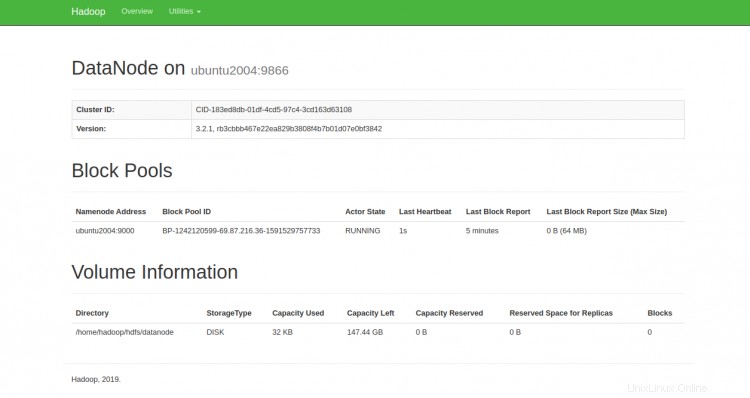
Per accedere a YARN Resource Manager, utilizzare l'URL http://your-server-ip:8088. Dovresti vedere la seguente schermata:
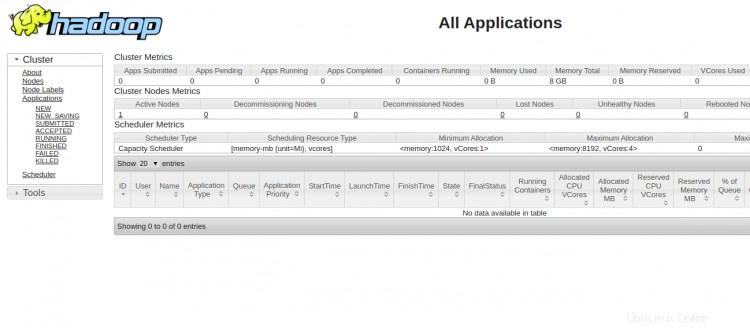
Conclusione
Congratulazioni! hai installato correttamente Hadoop su un singolo nodo. Ora puoi iniziare a esplorare i comandi HDFS di base e progettare un cluster Hadoop completamente distribuito. Sentiti libero di chiedermi se hai domande.