Hadoop è un framework software gratuito, open source e basato su Java utilizzato per l'archiviazione e l'elaborazione di grandi set di dati su cluster di macchine. Utilizza HDFS per memorizzare i propri dati ed elaborare questi dati utilizzando MapReduce. È un ecosistema di strumenti per Big Data utilizzati principalmente per il data mining e l'apprendimento automatico.
Apache Hadoop 3.3 viene fornito con notevoli miglioramenti e molte correzioni di bug rispetto alle versioni precedenti. Ha quattro componenti principali come Hadoop Common, HDFS, YARN e MapReduce.
Questo tutorial ti spiegherà come installare e configurare Apache Hadoop sul sistema Linux Ubuntu 20.04 LTS.
Fase 1 – Installazione di Java
Hadoop è scritto in Java e supporta solo Java versione 8. Hadoop versione 3.3 e più recenti supportano anche Java 11 runtime e Java 8.
Puoi installare OpenJDK 11 dai repository apt predefiniti:
sudo apt updatesudo apt install openjdk-11-jdk
Una volta installato, verifica la versione installata di Java con il seguente comando:
java -version
Dovresti ottenere il seguente output:
openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
Fase 2:crea un utente Hadoop
È una buona idea creare un utente separato per eseguire Hadoop per motivi di sicurezza.
Esegui il comando seguente per creare un nuovo utente con nome hadoop:
sudo adduser hadoop
Fornire e confermare la nuova password come mostrato di seguito:
Adding user `hadoop' ...
Adding new group `hadoop' (1002) ...
Adding new user `hadoop' (1002) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
Passaggio 3:configurazione dell'autenticazione basata su chiave SSH
Successivamente, dovrai configurare l'autenticazione SSH senza password per il sistema locale.
Innanzitutto, cambia l'utente in hadoop con il seguente comando:
su - hadoop
Quindi, esegui il comando seguente per generare coppie di chiavi pubbliche e private:
ssh-keygen -t rsa
Ti verrà chiesto di inserire il nome del file. Basta premere Invio per completare il processo:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:QSa2syeISwP0hD+UXxxi0j9MSOrjKDGIbkfbM3ejyIk [email protected] The key's randomart image is: +---[RSA 3072]----+ | ..o++=.+ | |..oo++.O | |. oo. B . | |o..+ o * . | |= ++o o S | |.++o+ o | |.+.+ + . o | |o . o * o . | | E + . | +----[SHA256]-----+
Quindi, aggiungi le chiavi pubbliche generate da id_rsa.pub a authorized_keys e imposta le autorizzazioni appropriate:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 640 ~/.ssh/authorized_keys
Successivamente, verifica l'autenticazione SSH senza password con il comando seguente:
ssh localhost
Ti verrà chiesto di autenticare gli host aggiungendo chiavi RSA agli host conosciuti. Digita yes e premi Invio per autenticare l'host locale:
The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is SHA256:JFqDVbM3zTPhUPgD5oMJ4ClviH6tzIRZ2GD3BdNqGMQ. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Fase 4 – Installazione di Hadoop
Innanzitutto, cambia l'utente in hadoop con il seguente comando:
su - hadoop
Quindi, scarica l'ultima versione di Hadoop usando il comando wget:
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
Una volta scaricato, estrai il file scaricato:
tar -xvzf hadoop-3.3.0.tar.gz
Quindi, rinomina la directory estratta in hadoop:
mv hadoop-3.3.0 hadoop
Successivamente, dovrai configurare Hadoop e le variabili d'ambiente Java sul tuo sistema.
Apri ~/.bashrc file nel tuo editor di testo preferito:
nano ~/.bashrc
Aggiungi le righe seguenti al file. Puoi trovare la posizione di JAVA_HOME eseguendo dirname $(dirname $(readlink -f $(which java))) command on terminal.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Save and close the file. Then, activate the environment variables with the following command:
source ~/.bashrc
Quindi, apri il file della variabile d'ambiente Hadoop:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Imposta nuovamente JAVA_HOME nell'ambiente hadoop.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Salva e chiudi il file quando hai finito.
Fase 5:configurazione di Hadoop
Innanzitutto, dovrai creare le directory namenode e datanode all'interno della home directory di Hadoop:
Esegui il comando seguente per creare entrambe le directory:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
Quindi, modifica il core-site.xml file e aggiorna con il tuo nome host di sistema:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Modifica il seguente nome in base al nome host del tuo sistema:
XHTML
| 1234567891011121314151617 |
Salva e chiudi il file. Quindi, modifica il mapred-site.xml file:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Apporta le seguenti modifiche:
XHTML
| 123456 |
Salva e chiudi il file. Quindi, modifica il sito-filato.xml file:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Apporta le seguenti modifiche:
XHTML
| 123456 |
Salva e chiudi il file quando hai finito.
Fase 6:avvia il cluster Hadoop
Prima di avviare il cluster Hadoop. Dovrai formattare il Namenode come utente hadoop.
Esegui il comando seguente per formattare il Namenode hadoop:
hdfs namenode -format
Dovresti ottenere il seguente output:
2020-11-23 10:31:51,318 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-11-23 10:31:51,323 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-11-23 10:31:51,323 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.net/127.0.1.1 ************************************************************/
Dopo aver formattato il Namenode, esegui il comando seguente per avviare il cluster hadoop:
start-dfs.sh
Una volta avviato correttamente HDFS, dovresti ottenere il seguente output:
Starting namenodes on [hadoop.tecadmin.com] hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts. Starting datanodes Starting secondary namenodes [hadoop.tecadmin.com]
Quindi, avvia il servizio YARN come mostrato di seguito:
start-yarn.sh
Dovresti ottenere il seguente output:
Starting resourcemanager Starting nodemanagers
Ora puoi controllare lo stato di tutti i servizi Hadoop usando il comando jps:
jps
Dovresti vedere tutti i servizi in esecuzione nel seguente output:
18194 NameNode 18822 NodeManager 17911 SecondaryNameNode 17720 DataNode 18669 ResourceManager 19151 Jps
Passaggio 7:regola il firewall
Hadoop è ora avviato e in ascolto sulle porte 9870 e 8088. Successivamente, dovrai consentire a queste porte attraverso il firewall.
Esegui il comando seguente per consentire le connessioni Hadoop attraverso il firewall:
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcp
Quindi, ricarica il servizio firewalld per applicare le modifiche:
firewall-cmd --reload
Fase 8:accedi a Hadoop Namenode e Resource Manager
Per accedere al Namenode, apri il tuo browser web e visita l'URL http://your-server-ip:9870. Dovresti vedere la seguente schermata:
http://hadoop.tecadmin.net:9870
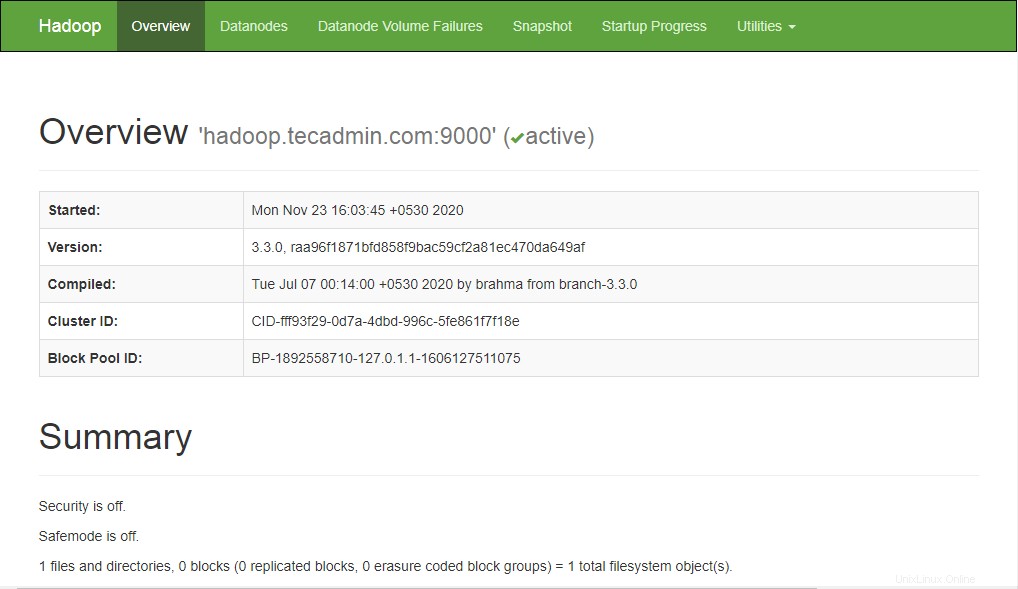
Per accedere a Gestione risorse, apri il tuo browser web e visita l'URL http://your-server-ip:8088. Dovresti vedere la seguente schermata:
http://hadoop.tecadmin.net:8088
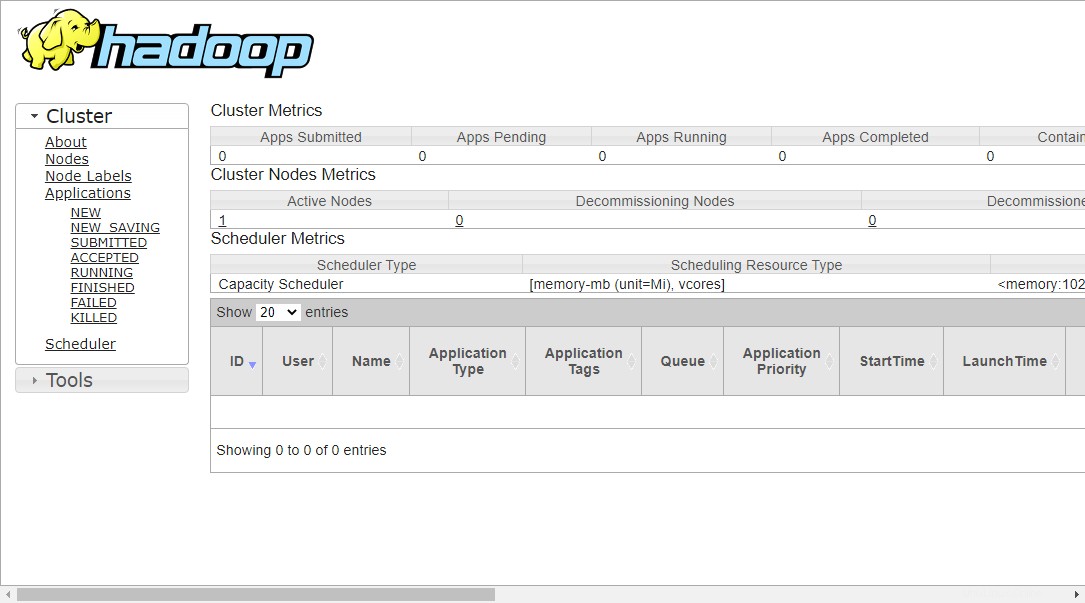
Fase 9:verifica del cluster Hadoop
A questo punto, il cluster Hadoop è installato e configurato. Successivamente, creeremo alcune directory nel filesystem HDFS per testare Hadoop.
Creiamo una directory nel filesystem HDFS usando il seguente comando:
hdfs dfs -mkdir /test1hdfs dfs -mkdir /logs
Quindi, esegui il comando seguente per elencare la directory precedente:
hdfs dfs -ls /
Dovresti ottenere il seguente output:
Found 3 items drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:56 /logs drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:51 /test1
Inoltre, inserisci alcuni file nel file system hadoop. Per l'esempio, inserire i file di registro dalla macchina host al file system hadoop.
hdfs dfs -put /var/log/* /logs/
Puoi anche verificare i file e la directory di cui sopra nell'interfaccia web Hadoop Namenode.
Vai all'interfaccia web di Namenode, fai clic su Utilità => Sfoglia il file system. Dovresti vedere le tue directory che hai creato in precedenza nella schermata seguente:
http://hadoop.tecadmin.net:9870/explorer.html
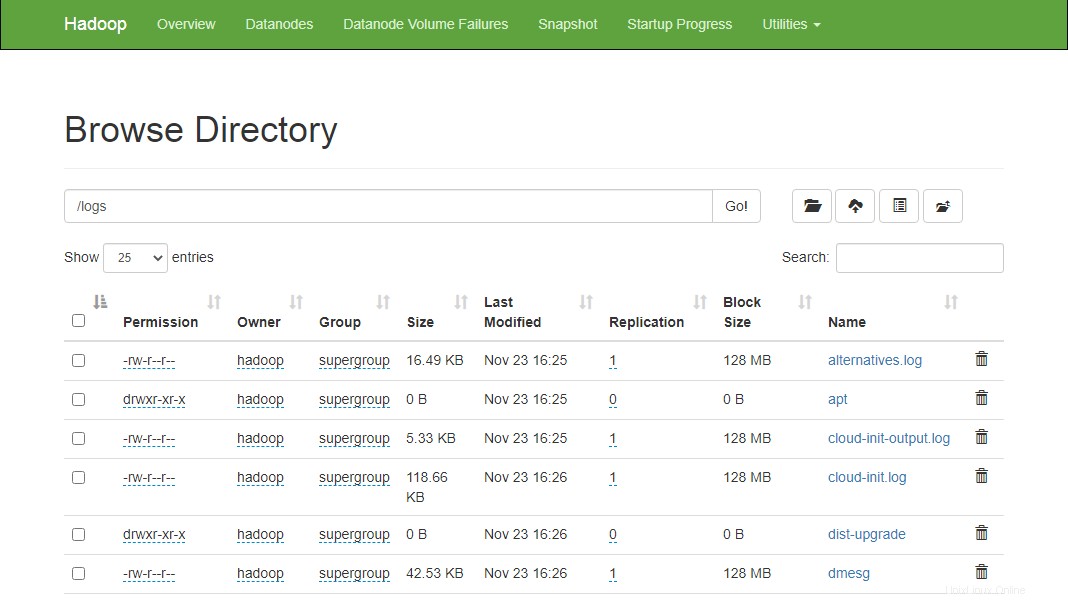
Fase 10:ferma il cluster Hadoop
Puoi anche interrompere il servizio Hadoop Namenode e Yarn in qualsiasi momento eseguendo stop-dfs.sh e stop-yarn.sh script come utente Hadoop.
Per interrompere il servizio Hadoop Namenode, esegui il seguente comando come utente hadoop:
stop-dfs.sh
Per interrompere il servizio Hadoop Resource Manager, eseguire il comando seguente:
stop-yarn.sh
Conclusione
Questo tutorial ti ha spiegato passo dopo passo il tutorial per installare e configurare Hadoop sul sistema Linux Ubuntu 20.04.