Introduzione
Tutti i principali settori industriali stanno implementando Apache Hadoop come framework standard per l'elaborazione e l'archiviazione di big data. Hadoop è progettato per essere distribuito su una rete di centinaia o addirittura migliaia di server dedicati. Tutte queste macchine lavorano insieme per gestire l'enorme volume e la varietà di set di dati in entrata.
La distribuzione dei servizi Hadoop su un singolo nodo è un ottimo modo per familiarizzare con i comandi e i concetti di base di Hadoop.
Questa guida facile da seguire ti aiuta a installare Hadoop su Ubuntu 18.04 o Ubuntu 20.04.

Prerequisiti
- Accesso a una finestra di terminale/riga di comando
- Sudo o root privilegi su macchine locali/remote
Installa OpenJDK su Ubuntu
Il framework Hadoop è scritto in Java e i suoi servizi richiedono un Java Runtime Environment (JRE) e un Java Development Kit (JDK) compatibili. Utilizzare il comando seguente per aggiornare il sistema prima di avviare una nuova installazione:
sudo apt updateAl momento, Apache Hadoop 3.x supporta completamente Java 8 . Il pacchetto OpenJDK 8 in Ubuntu contiene sia l'ambiente di runtime che il kit di sviluppo.
Digita il seguente comando nel tuo terminale per installare OpenJDK 8:
sudo apt install openjdk-8-jdk -yLa versione OpenJDK o Oracle Java può influenzare il modo in cui gli elementi di un ecosistema Hadoop interagiscono. Per installare una versione Java specifica, consulta la nostra guida dettagliata su come installare Java su Ubuntu.
Una volta completato il processo di installazione, verifica la versione Java corrente:
java -version; javac -versionL'output ti informa su quale edizione Java è in uso.

Configura un utente non root per l'ambiente Hadoop
È consigliabile creare un utente non root, specifico per l'ambiente Hadoop. Un utente distinto migliora la sicurezza e ti aiuta a gestire il tuo cluster in modo più efficiente. Per garantire il corretto funzionamento dei servizi Hadoop, l'utente dovrebbe avere la possibilità di stabilire una connessione SSH senza password con l'host locale.
Installa OpenSSH su Ubuntu
Installa il server e il client OpenSSH utilizzando il seguente comando:
sudo apt install openssh-server openssh-client -yNell'esempio seguente, l'output conferma che l'ultima versione è già installata.

Se hai installato OpenSSH per la prima volta, sfrutta questa opportunità per implementare questi consigli di sicurezza SSH vitali.
Crea utente Hadoop
Utilizza il adduser comando per creare un nuovo utente Hadoop:
sudo adduser hdoopIl nome utente, in questo esempio, è hdoop . Sei libero di utilizzare qualsiasi nome utente e password che ritieni opportuno. Passa all'utente appena creato e inserisci la password corrispondente:
su - hdoopL'utente ora deve essere in grado di inviare SSH all'host locale senza che venga richiesta una password.
Abilita SSH senza password per utenti Hadoop
Genera una coppia di chiavi SSH e definisci la posizione in cui deve essere archiviata:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsaIl sistema procede alla generazione e al salvataggio della coppia di chiavi SSH.
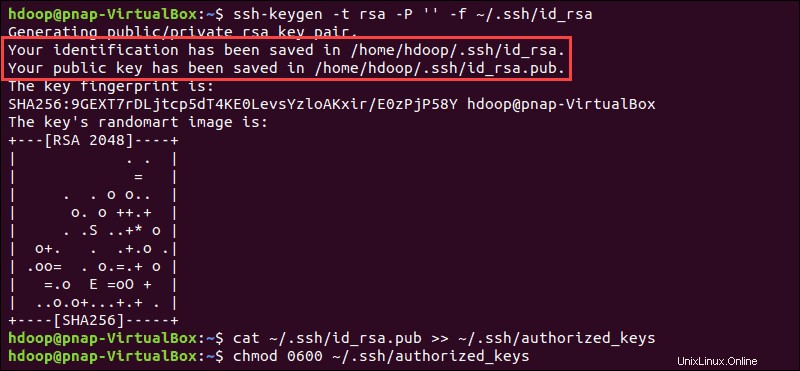
Usa il cat comando per memorizzare la chiave pubblica come chiavi_autorizzate nel ssh directory:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Imposta le autorizzazioni per il tuo utente con il chmod comando:
chmod 0600 ~/.ssh/authorized_keysIl nuovo utente è ora in grado di utilizzare SSH senza dover inserire una password ogni volta. Verifica che tutto sia impostato correttamente utilizzando hdoop utente a SSH a localhost:
ssh localhostDopo una richiesta iniziale, l'utente Hadoop è ora in grado di stabilire una connessione SSH all'host locale senza problemi.
Scarica e installa Hadoop su Ubuntu
Visita la pagina ufficiale del progetto Apache Hadoop e seleziona la versione di Hadoop che desideri implementare.
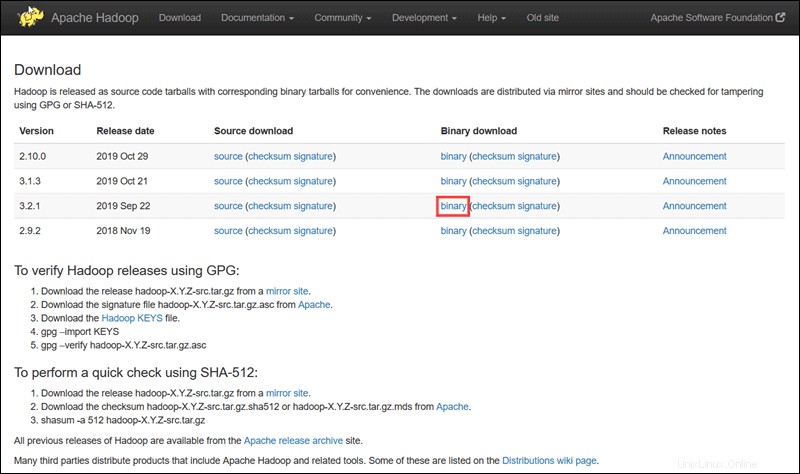
I passaggi descritti in questo tutorial utilizzano il download binario per Hadoop versione 3.2.1 .
Seleziona la tua opzione preferita e ti viene presentato un collegamento mirror che ti consente di scaricare il pacchetto Hadoop tar .
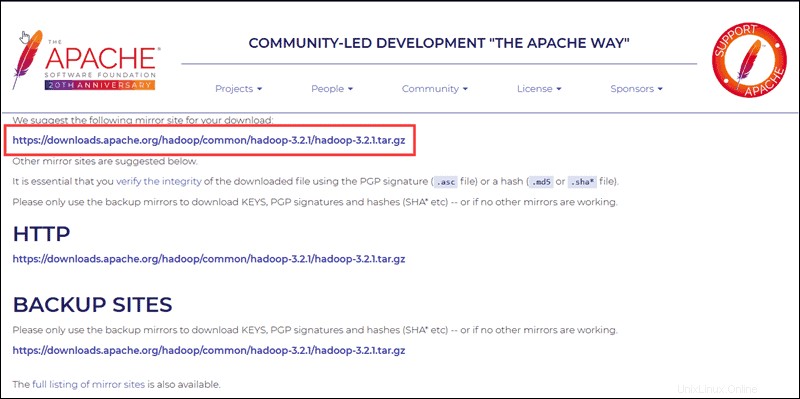
Usa il link mirror fornito e scarica il pacchetto Hadoop con il wget comando:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz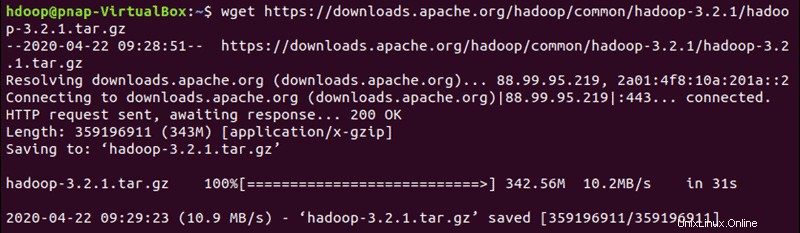
Una volta completato il download, estrai i file per avviare l'installazione di Hadoop:
tar xzf hadoop-3.2.1.tar.gzI file binari di Hadoop si trovano ora all'interno di hadoop-3.2.1 directory.
Distribuzione Hadoop a nodo singolo (modalità pseudodistribuita)
Hadoop eccelle se distribuito in una modalità completamente distribuita su un grande cluster di server in rete. Tuttavia, se non conosci Hadoop e desideri esplorare i comandi di base o testare le applicazioni, puoi configurare Hadoop su un singolo nodo.
Questa configurazione, chiamata anche modalità pseudo-distribuita , consente a ciascun demone Hadoop di essere eseguito come un singolo processo Java. Un ambiente Hadoop viene configurato modificando una serie di file di configurazione:
- bashrc
- hadoop-env.sh
- core-site.xml
- sito-hdfs.xml
- mapred-site-xml
- sito-filato.xml
Configura variabili d'ambiente Hadoop (bashrc)
Modifica il .bashrc file di configurazione della shell utilizzando un editor di testo a tua scelta (useremo nano):
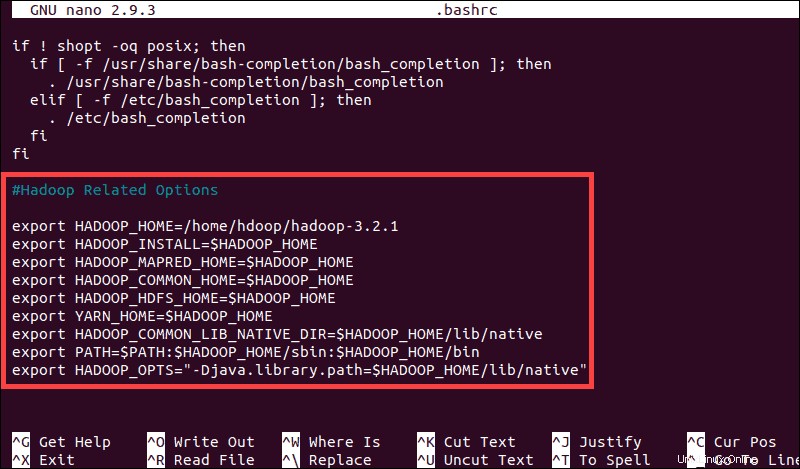
sudo nano .bashrcDefinisci le variabili di ambiente Hadoop aggiungendo il seguente contenuto alla fine del file:
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
Una volta aggiunte le variabili, salva ed esci da .bashrc file.
È fondamentale applicare le modifiche all'ambiente in esecuzione corrente utilizzando il comando seguente:
source ~/.bashrcModifica il file hadoop-env.sh
Il hadoop-env.sh funge da file master per configurare le impostazioni di progetto relative a YARN, HDFS, MapReduce e Hadoop.
Quando si configura un cluster Hadoop a nodo singolo , è necessario definire quale implementazione Java deve essere utilizzata. Usa il $HADOOP_HOME creato in precedenza variabile per accedere a hadoop-env.sh file:
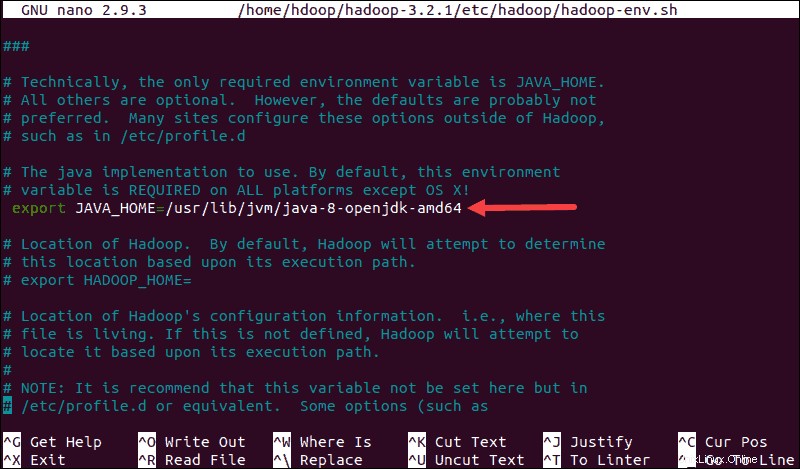
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Decommenta il $JAVA_HOME variabile (ovvero, rimuovere il # sign) e aggiungi il percorso completo all'installazione di OpenJDK sul tuo sistema. Se hai installato la stessa versione presentata nella prima parte di questo tutorial, aggiungi la seguente riga:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64Il percorso deve corrispondere alla posizione dell'installazione Java sul tuo sistema.
Se hai bisogno di aiuto per individuare il percorso Java corretto, esegui il seguente comando nella finestra del tuo terminale:
which javacL'output risultante fornisce il percorso alla directory binaria Java.

Utilizzare il percorso fornito per trovare la directory OpenJDK con il seguente comando:
readlink -f /usr/bin/javac
La sezione del percorso appena prima di /bin/javac la directory deve essere assegnata al $JAVA_HOME variabile.

Modifica file core-site.xml
Il core-site.xml definisce le proprietà principali di HDFS e Hadoop.
Per configurare Hadoop in modalità pseudo-distribuita, devi specificare l'URL per il tuo NameNode e la directory temporanea utilizzata da Hadoop per la mappa e il processo di riduzione.
Apri il core-site.xml file in un editor di testo:
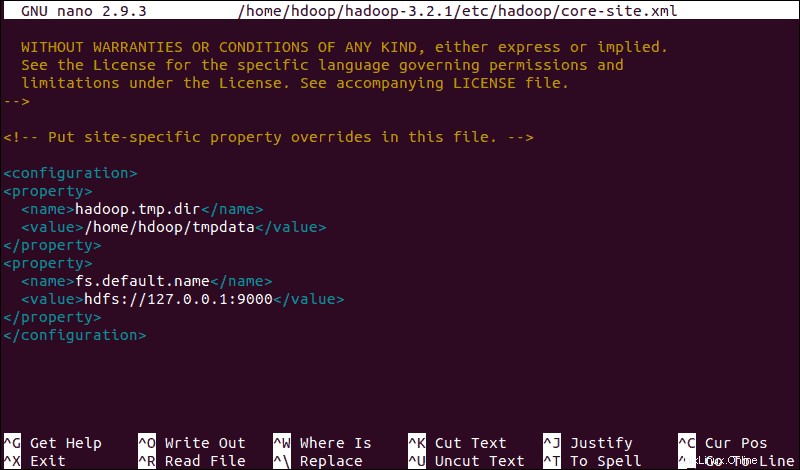
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlAggiungi la seguente configurazione per sovrascrivere i valori predefiniti per la directory temporanea e aggiungi il tuo URL HDFS per sostituire l'impostazione predefinita del file system locale:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>Questo esempio utilizza valori specifici del sistema locale. È necessario utilizzare valori che corrispondono ai requisiti di sistema. I dati devono essere coerenti durante tutto il processo di configurazione.
Non dimenticare di creare una directory Linux nella posizione specificata per i tuoi dati temporanei.
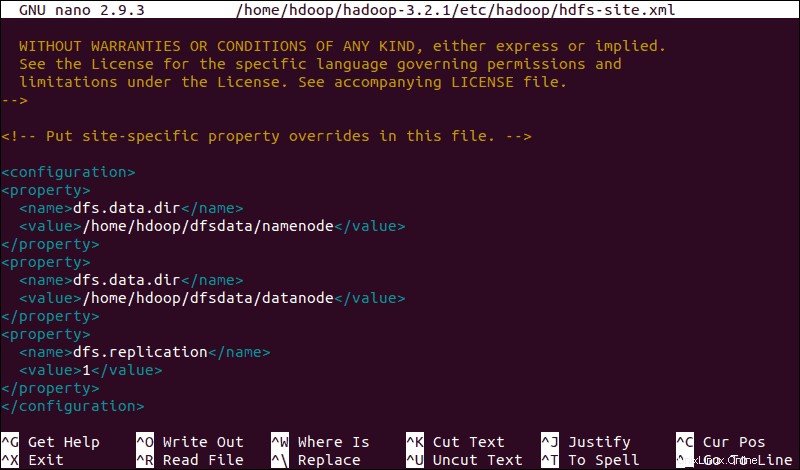
Modifica file hdfs-site.xml
Le proprietà in hdfs-site.xml file governa il percorso per la memorizzazione dei metadati del nodo, del file fsimage e del file di registro di modifica. Configura il file definendo il NomeNode e Directory di archiviazione DataNode .
Inoltre, il predefinito dfs.replication valore di 3 deve essere cambiato in 1 in modo che corrisponda alla configurazione del nodo singolo.
Utilizzare il comando seguente per aprire hdfs-site.xml file da modificare:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlAggiungi la seguente configurazione al file e, se necessario, adatta le directory NameNode e DataNode alle tue posizioni personalizzate:
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Se necessario, crea le directory specifiche che hai definito per il dfs.data.dir valore.
Modifica file mapred-site.xml
Utilizzare il comando seguente per accedere a mapred-site.xml file e definisci i valori di MapReduce :
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Aggiungi la seguente configurazione per modificare il valore predefinito del nome del framework MapReduce in yarn :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>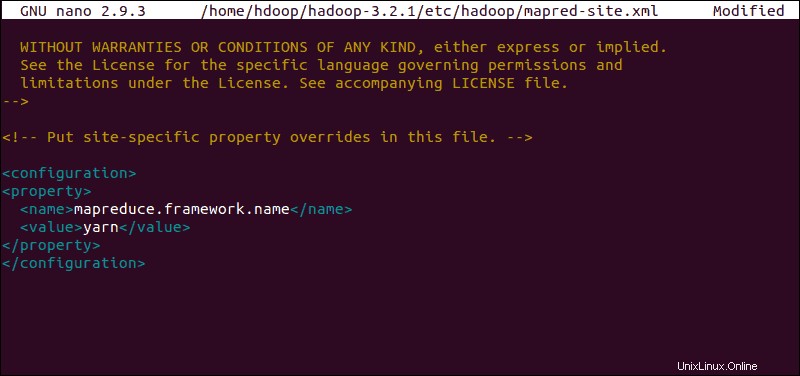
Modifica file yarn-site.xml
Il sito-filato.xml viene utilizzato per definire le impostazioni relative a YARN . Contiene le configurazioni per Node Manager, Resource Manager, Containers e Application Master .
Apri il sito-filato.xml file in un editor di testo:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlAggiungi la seguente configurazione al file:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>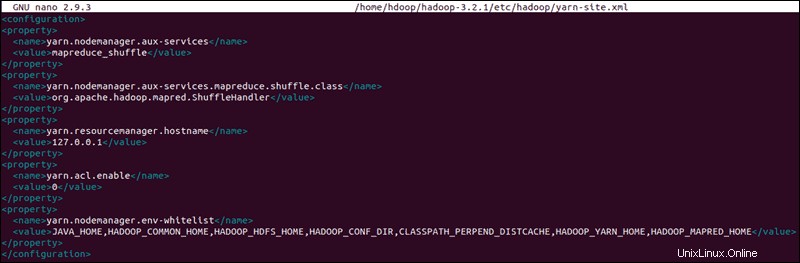
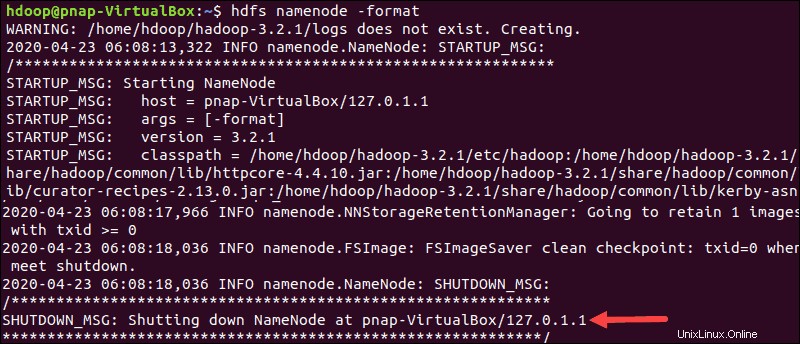
Formatta NameNode HDFS
È importante formattare il NameNode prima di avviare i servizi Hadoop per la prima volta:
hdfs namenode -formatLa notifica di arresto indica la fine del processo di formattazione NameNode.
Avvia il cluster Hadoop
Passa a hadoop-3.2.1/sbin directory ed eseguire i seguenti comandi per avviare NameNode e DataNode:
./start-dfs.shIl sistema impiega alcuni istanti per avviare i nodi necessari.

Una volta che il namenode, i datanode e il namenode secondario sono attivi e funzionanti, avvia la risorsa YARN e i gestori dei nodi digitando:
./start-yarn.shCome con il comando precedente, l'output ti informa che i processi stanno iniziando.

Digita questo semplice comando per verificare se tutti i demoni sono attivi e in esecuzione come processi Java:
jpsSe tutto funziona come previsto, l'elenco risultante dei processi Java in esecuzione contiene tutti i demoni HDFS e YARN.

Accedi all'interfaccia utente di Hadoop dal browser
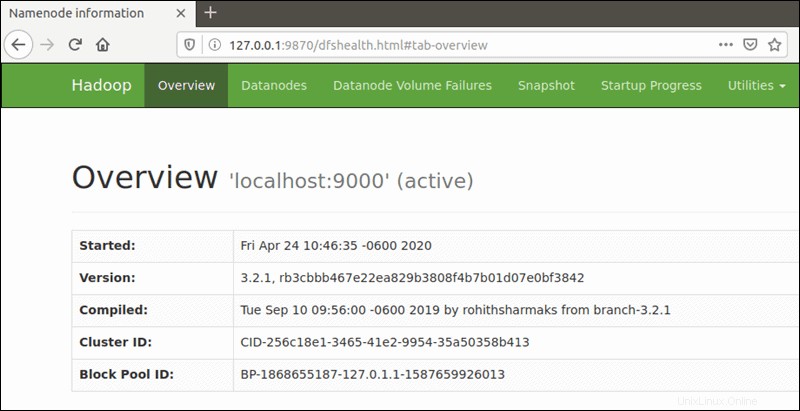
Usa il tuo browser preferito e vai al tuo URL o IP localhost. Il numero di porta predefinito 9870 ti dà accesso all'interfaccia utente di Hadoop NameNode:
http://localhost:9870L'interfaccia utente di NameNode fornisce una panoramica completa dell'intero cluster.
La porta predefinita 9864 viene utilizzato per accedere ai singoli DataNode direttamente dal tuo browser:
http://localhost:9864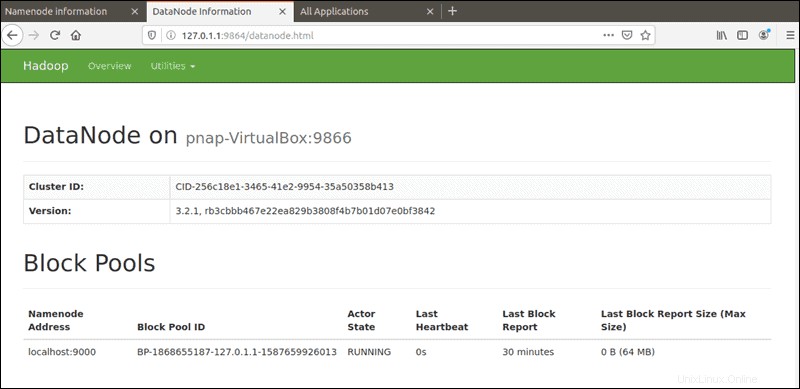
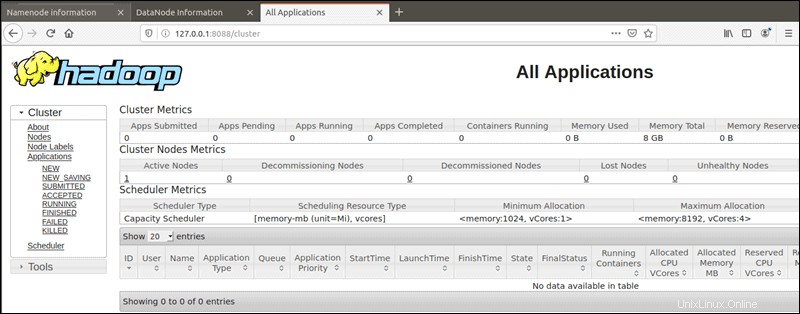
YARN Resource Manager è accessibile sulla porta 8088 :
http://localhost:8088Il Resource Manager è uno strumento prezioso che ti consente di monitorare tutti i processi in esecuzione nel tuo cluster Hadoop.