Qui vedremo come installare Apache Spark su Ubuntu 20.04 o 18.04, i comandi saranno applicabili per Linux Mint, Debian e altri sistemi Linux simili.
Apache Spark è uno strumento di elaborazione dati generico chiamato motore di elaborazione dati. Utilizzato da data engineer e data scientist per eseguire query di dati estremamente veloci su grandi quantità di dati nell'intervallo di terabyte. È un framework per calcoli basati su cluster che compete con il classico Hadoop Map/Reduce utilizzando la RAM disponibile nel cluster per un'esecuzione più rapida dei lavori.
Inoltre, Spark offre anche la possibilità di controllare i dati tramite SQL, elaborarli tramite streaming (quasi) in tempo reale e fornisce il proprio database di grafici e una libreria di machine learning. Il framework offre tecnologie in-memory per questo scopo, ovvero può archiviare query e dati direttamente nella memoria principale dei nodi del cluster.
Apache Spark è l'ideale per elaborare rapidamente grandi quantità di dati. Il modello di programmazione di Spark si basa su Resilient Distributed Datasets (RDD), una classe di raccolta che opera distribuita in un cluster. Questa piattaforma open source supporta una varietà di linguaggi di programmazione come Java, Scala, Python e R.
Passaggi per l'installazione di Apache Spark su Ubuntu 20.04
I passaggi qui riportati possono essere utilizzati per altre versioni di Ubuntu come 21.04/18.04, inclusi Linux Mint, Debian e Linux simili.
1. Installa Java con altre dipendenze
Qui stiamo installando l'ultima versione disponibile di Jave che è il requisito di Apache Spark insieme ad altre cose:Git e Scala per estendere le sue capacità.
sudo apt install default-jdk scala git
2. Scarica Apache Spark su Ubuntu 20.04
Ora, visita il sito Web ufficiale di Spark e scarica l'ultima versione disponibile. Tuttavia, durante la stesura di questo tutorial l'ultima versione era la 3.1.2. Quindi, qui stiamo scaricando lo stesso, nel caso in cui sia diverso quando stai eseguendo l'installazione di Spark sul tuo sistema Ubuntu, provalo. Copia semplicemente il link per il download di questo strumento e utilizzalo con wget o scaricalo direttamente sul tuo sistema.
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3. Estrai Spark in /opt
Per assicurarci di non eliminare accidentalmente la cartella estratta, mettiamola in un posto sicuro, ad esempio /opt directory.
sudo mkdir /opt/spark
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
Inoltre, cambia i permessi della cartella, in modo che Spark possa scrivere al suo interno.
sudo chmod -R 777 /opt/spark
4. Aggiungi la cartella Spark al percorso di sistema
Ora, poiché abbiamo spostato il file in /opt directory, per eseguire il comando Spark nel terminale dobbiamo menzionare l'intero percorso ogni volta che è fastidioso. Per risolvere questo problema, configuriamo le variabili di ambiente per Spark aggiungendo i suoi percorsi home al file profilo/bashrc del sistema. Questo ci consente di eseguire i suoi comandi da qualsiasi punto del terminale indipendentemente dalla directory in cui ci troviamo.
echo "export SPARK_HOME=/opt/spark" >> ~/.bashrc echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.bashrc echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.bashrc
Ricarica shell:
source ~/.bashrc
5. Avvia il server master Apache Spark su Ubuntu
Poiché abbiamo già configurato l'ambiente variabile per Spark, ora avviamo il suo server master autonomo eseguendo il suo script:
start-master.sh
Modifica l'interfaccia utente Web Spark Master e la porta di ascolto (opzionale, da utilizzare solo se necessario)
Se desideri utilizzare una porta personalizzata, è possibile utilizzare le opzioni o gli argomenti indicati di seguito.
–porta – Porta per il servizio su cui ascoltare (predefinita:7077 per master, random per worker)
–webui-port – Porta per interfaccia utente web (predefinita:8080 per master, 8081 per lavoratore)
Esempio – Voglio eseguire l'interfaccia utente Web Spark su 8082 e farlo ascoltare alla porta 7072, quindi il comando per avviarlo sarà così:
start-master.sh --port 7072 --webui-port 8082
6. Accedi a Spark Master (spark://Ubuntu:7077) – Interfaccia Web
Ora accediamo all'interfaccia web del server master Spark che gira alla porta numero 8080 . Quindi, nel tuo browser apri http://127.0.0.1:8080 .
Il nostro master è in esecuzione su spark://Ubuntu :7077, dove Ubuntu è il nome host del sistema e potrebbe essere diverso nel tuo caso.
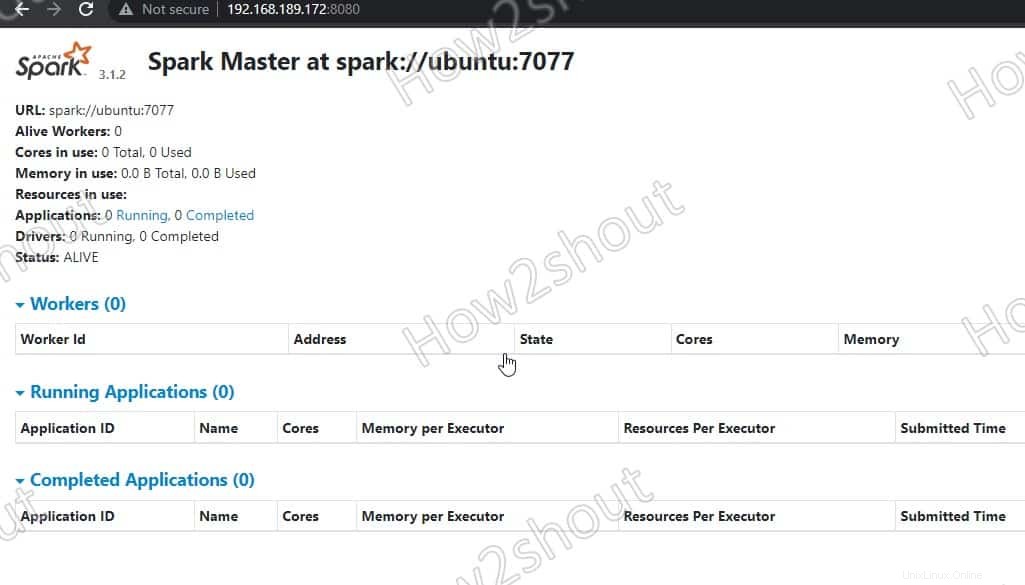
Se stai utilizzando un server CLI e desideri utilizzare il browser dell'altro sistema che può accedere all'indirizzo IP del server, per quello prima apri 8080 nel firewall. Ciò ti consentirà di accedere all'interfaccia Web di Spark da remoto all'indirizzo – http://your-server-ip-addres:8080
sudo ufw allow 8080
7. Esegui lo script Slave Worker
Per eseguire Spark slave worker, dobbiamo avviare il suo script disponibile nella directory che abbiamo copiato in /opt . La sintassi del comando sarà:
Sintassi dei comandi:
start-worker.sh spark://hostname:port
Nel comando precedente cambia il nome host e porta . Se non conosci il tuo nome host, digita semplicemente:hostname nel terminale. Dove la porta predefinita di master è in esecuzione è 7077, puoi vedere nello screenshot qui sopra .
Quindi, poiché il nostro nome host è ubuntu, il comando sarà così:
start-worker.sh spark://ubuntu:7077
Aggiorna l'interfaccia web e vedrai l'ID lavoratore e la quantità di memoria ad esso assegnato:
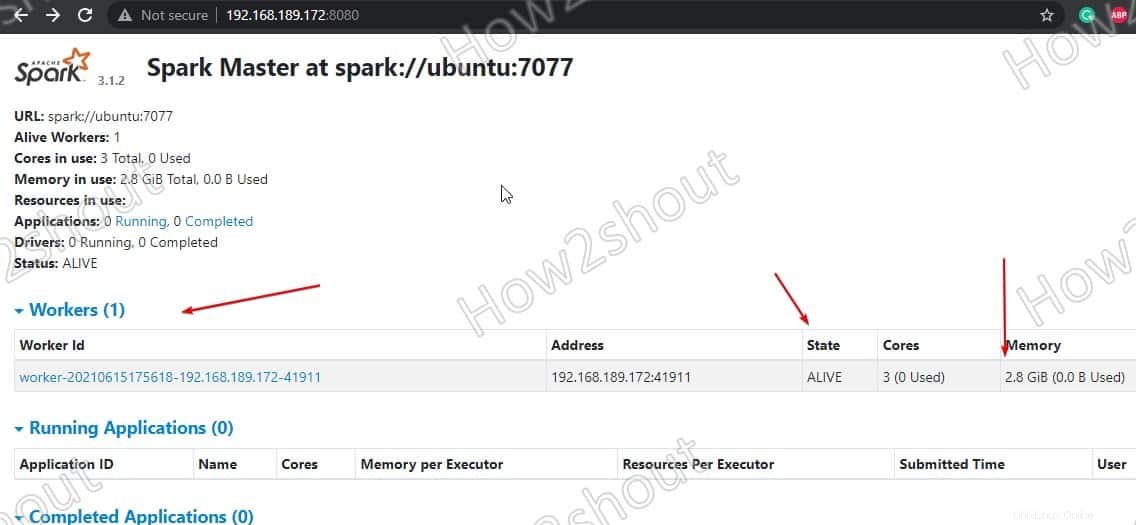
Se lo desideri, puoi modificare la memoria/ram assegnata al lavoratore. Per questo, devi riavviare il lavoratore con la quantità di RAM che desideri fornirgli.
stop-worker.sh start-worker.sh -m 212M spark://ubuntu:7077
Usa Spark Shell
Chi desidera utilizzare Spark shell per iniziare a programmare può accedervi digitando direttamente:
spark-shell
Per vedere le opzioni supportate, digita- :help e per uscire dall'uso della shell – :quite
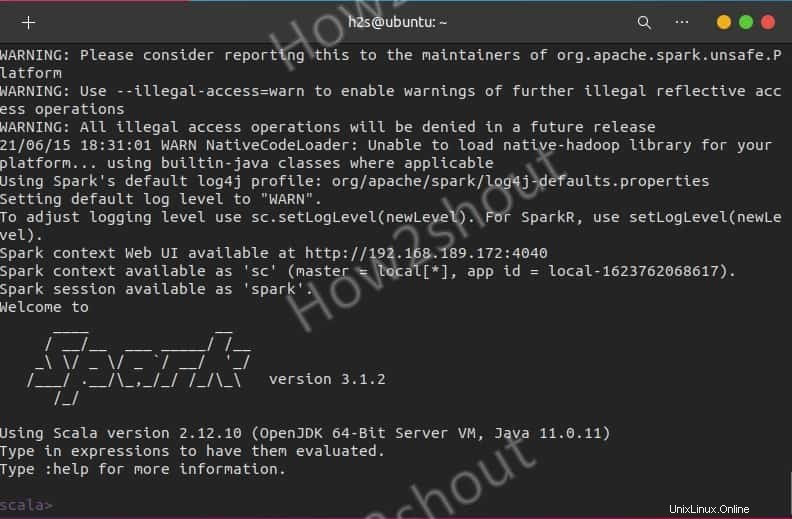
Per iniziare con la shell Python invece di Scala, usa:
pyspark
Comandi di avvio e arresto del server
Se vuoi avviare o interrompere master/lavoratori istanze, quindi utilizzare gli script corrispondenti:
stop-master.sh stop-worker.sh
Per fermare tutto in una volta
stop-all.sh
Oppure inizia tutto in una volta:
start-all.sh
Pensieri finali:
In questo modo, possiamo installare e iniziare a utilizzare Apache Spark su Ubuntu Linux. Per saperne di più puoi fare riferimento alla documentazione ufficiale . Tuttavia, rispetto ad Hadoop, Spark è ancora relativamente giovane, quindi devi fare i conti con alcuni spigoli. Tuttavia, si è già dimostrato molte volte nella pratica e consente nuovi casi d'uso nell'area dei dati grandi o veloci attraverso l'esecuzione rapida di lavori e la memorizzazione nella cache dei dati. Infine, offre un'API uniforme per strumenti che altrimenti dovrebbero essere utilizzati e gestiti separatamente nell'ambiente Hadoop.