Introduzione
La normalizzazione del database è un metodo nella progettazione di database relazionali che aiuta a organizzare correttamente le tabelle di dati. Il processo mira a creare un sistema che rappresenti fedelmente informazioni e relazioni senza perdita o ridondanza dei dati.
Questo articolo spiega la normalizzazione del database e come normalizzare un database attraverso un esempio pratico.

Cos'è la normalizzazione del database?
Normalizzazione del database è una tecnica per creare tabelle di database con colonne e chiavi adatte scomponendo una tabella di grandi dimensioni in unità logiche più piccole. Il processo considera anche le esigenze dell'ambiente in cui risiede il database.
La normalizzazione è un processo iterativo. Comunemente, la normalizzazione di un database avviene attraverso una serie di test. Ogni passaggio successivo scompone le tabelle in informazioni più gestibili, rendendo il database generale logico e più facile da lavorare.
Perché la normalizzazione del database è importante?
La normalizzazione aiuta un progettista di database a distribuire in modo ottimale gli attributi nelle tabelle. La tecnica elimina quanto segue:
- Attributi con più valori.
- Doppio o ripetuto attributi.
- Non descrittivo attributi.
- Attributi con ridondante informazioni.
- Attributi creati da altre funzioni .
Sebbene la normalizzazione totale del database non sia necessaria, fornisce un ambiente informativo ben funzionante. Il metodo garantisce sistematicamente:
- Una struttura di database adatto per query generalizzate.
- Ridondanza dei dati ridotta al minimo , aumentando l'efficienza della memoria su un server di database.
- Massima integrità dei dati attraverso la riduzione delle anomalie di inserimento, aggiornamento e cancellazione.
La normalizzazione del database trasforma la coerenza complessiva del database, fornendo un ambiente efficiente.
Ridondanza e anomalie del database
Quando si altera un'entità in una tabella con ridondanze , è necessario modificare tutte le istanze ripetute di informazioni e qualsiasi altra informazione correlata ai dati modificati. In caso contrario, il database diventa incoerente e anomalie accadere quando si apportano modifiche.
Ad esempio, nella seguente tabella non normalizzata:

La tabella contiene dati ridondanza , che a sua volta causa tre anomalie quando si apportano modifiche ai dati:
1. Inserisci anomalia . Quando si tenta di inserire un nuovo dipendente nel settore finanziario, è necessario conoscere anche il nome del manager. In caso contrario, non è possibile inserire dati nella tabella.
2. Aggiorna anomalia. Se un dipendente cambia settore, il nome del manager finisce per non essere corretto. Ad esempio, se Jacob passa alla finanza, Adam rimane il suo manager.
3. Elimina l'anomalia . Se Joshua decide di lasciare l'azienda, l'eliminazione della riga rimuove anche l'informazione che esiste un settore finanziario.
La soluzione a queste anomalie è nella normalizzazione del database concetti e passaggi.
Concetti di normalizzazione del database
I concetti elementari utilizzati nella normalizzazione del database sono:
- Chiavi . Attributi di colonna che identificano un record di database in modo univoco.
- Dipendenze funzionali . Vincoli tra due attributi in una relazione.
- Moduli normali . Passaggi per ottenere una certa qualità di un database.
Forme normali del database
La normalizzazione di un database si ottiene attraverso un insieme di regole note come forme normali . Il concetto centrale è aiutare un progettista di database a raggiungere la qualità desiderata di un database relazionale.
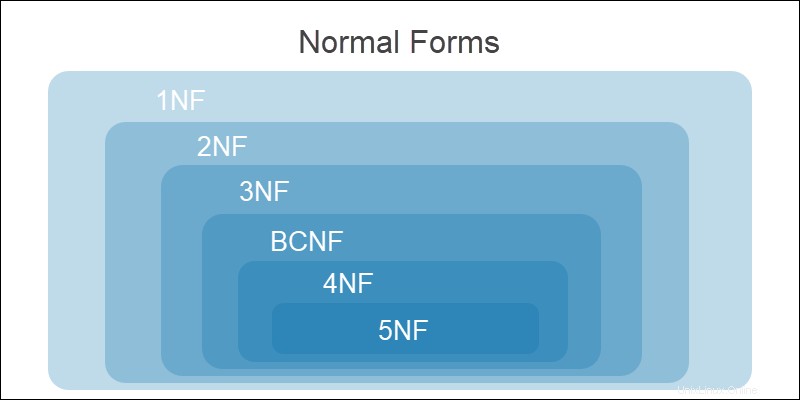
Tutti i livelli di normalizzazione sono cumulativi. requisiti della forma normale precedente devono essere soddisfatti prima di passare al modulo seguente.
Le fasi della normalizzazione sono:
| Palco | Anomalie di ridondanza risolte |
|---|---|
| Forma non normalizzata (UNF) | Lo stato prima di qualsiasi normalizzazione. Sono presenti valori ridondanti e complessi. |
| Prima forma normale (1NF) | Valori ripetuti e complessi si dividono, rendendo tutte le istanze atomiche. |
| Seconda forma normale (2NF) | Le dipendenze parziali si decompongono in nuove tabelle. Tutte le righe dipendono funzionalmente dalla chiave primaria. |
| Terza forma normale (3NF) | Le dipendenze transitive si decompongono in nuove tabelle. Gli attributi non chiave dipendono dalla chiave primaria. |
| Forma normale Boyce-Codd (BCNF) | Le dipendenze funzionali transitive e parziali per tutte le chiavi candidate vengono decomposte in nuove tabelle. |
| Quarta forma normale (4NF) | Rimozione delle dipendenze multivalore. |
| Quinta forma normale (5NF) | Rimozione delle dipendenze JOIN. |
Un database viene normalizzato quando soddisfa la terza forma normale . Ulteriori passaggi nella normalizzazione complicano la progettazione del database e potrebbero compromettere la funzionalità del sistema.
Cos'è una CHIAVE?
Una chiave di database è un attributo o un gruppo di funzionalità che descrive in modo univoco un'entità in una tabella. I tipi di chiavi utilizzati nella normalizzazione sono:
- Superchiave . Un insieme di funzionalità che definiscono in modo univoco ogni record in una tabella.
- Chiave candidato . Chiavi selezionate dal set di super chiavi in cui il numero di campi è minimo.
- Chiave primaria . La scelta più appropriata dall'insieme di chiavi candidate funge da chiave primaria della tabella.
- Chiave estera . La chiave primaria di un'altra tabella.
- Chiave composita . Due o più attributi insieme formano una chiave univoca ma non sono chiavi singolarmente.
Poiché le tabelle si decompongono in più tabelle più semplici, le chiavi definiscono un punto di riferimento per un'entità di database.
Ad esempio, nella seguente struttura di database:

Alcuni esempi di super chiavi nella tabella sono:
- ID dipendente
- (ID dipendente, nome)
Tutte le super chiavi possono fungere da identificatore univoco per ogni riga. D'altra parte, il nome o l'età del dipendente non sono identificatori univoci perché due persone potrebbero avere lo stesso nome o la stessa età.
Le chiavi del candidato provengono dal set di super chiavi in cui il numero di campi è minimo. La scelta si riduce a due opzioni:
- ID dipendente
Entrambe le opzioni contengono un numero minimo di campi, il che le rende chiavi candidate ottimali. La scelta più logica per la chiave primaria è l'ID dipendente perché l'e-mail di un dipendente può cambiare. È facile fare riferimento alla chiave primaria nella tabella come chiave esterna in un'altra tabella.
Dipendenze funzionali del database
Una dipendenza funzionale dal database rappresenta una relazione tra due attributi in una tabella del database. Alcuni tipi di dipendenze funzionali sono:
- Dipendenza funzionale banale . Una dipendenza tra un attributo e un gruppo di funzioni in cui l'elemento originale si trova nel gruppo.
- Dipendenza funzionale non banale . Una dipendenza tra un attributo e un gruppo in cui l'elemento non è nel gruppo.
- Dipendenza transitiva. Una dipendenza funzionale tra tre attributi in cui il secondo dipende dal primo e il terzo dipende dal secondo. A causa della transitività, il terzo attributo dipende dal primo.
- Dipendenza multivalore. Una dipendenza in cui più valori dipendono da un attributo.
Le dipendenze funzionali sono un passaggio essenziale nella normalizzazione del database. A lungo termine, le dipendenze aiutano a determinare la qualità complessiva di un database.
Esempio di normalizzazione del database - Come normalizzare un database?
I passaggi generali nella normalizzazione del database funzionano per ogni database. I passaggi specifici per dividere la tabella e se superare 3NF dipendono dal caso d'uso.
Esempio di database non normalizzato
Una tabella non normalizzata ha più valori all'interno di un singolo campo, nonché informazioni ridondanti nel peggiore dei casi.
Ad esempio:
| managerID | managerName | area | ID dipendente | employeeName | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Est | 1 2 | David D. Eugenio E. | 4 3 | Finanza IT |
| 2 | Betty B. | Ovest | 3 4 5 | George G. Henry H. Ingrid I. | 2 1 4 | Sicurezza Amministrazione Finanza |
| 3 | Carl C. | Nord | 6 7 | James J. Katy K. | 1 4 | Amministrazione Finanza |
L'inserimento, l'aggiornamento e la rimozione dei dati è un compito complesso. L'esecuzione di eventuali modifiche alla tabella esistente comporta un alto rischio di perdita di informazioni.
Fase 1:prima forma normale 1NF
Per rielaborare la tabella del database in 1NF, i valori all'interno di un singolo campo devono essere atomici. Tutte le entità complesse nella tabella si dividono in nuove righe o colonne.
Le informazioni nelle colonne managerID , nomemanager e area ripetere per ogni dipendente per garantire che non ci siano perdite di informazioni.
| managerID | managerName | area | ID dipendente | employeeName | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Est | 1 | David D. | 4 | Finanza |
| 1 | Adam A. | Est | 2 | Eugene E. | 3 | IT |
| 2 | Betty B. | Ovest | 3 | George G. | 2 | Sicurezza |
| 2 | Betty B. | Ovest | 4 | Henry H. | 1 | Amministrazione |
| 2 | Betty B. | Ovest | 5 | Ingrid I. | 4 | Finanza |
| 3 | Carl C. | Nord | 6 | James J. | 1 | Amministrazione |
| 3 | Carl C. | Nord | 7 | Katy K. | 4 | Finanza |
La tabella rielaborata soddisfa la prima forma normale.
Fase 2:seconda forma normale 2NF
La seconda forma normale nella normalizzazione del database afferma che ogni riga nella tabella del database deve dipendere dalla chiave primaria.
La tabella si divide in due tabelle per soddisfare la forma normale:
- Gestore (managerID, managerName, area)
| managerID | managerName | area |
|---|---|---|
| 1 | Adam A. | Est |
| 2 | Betty B. | Ovest |
| 3 | Carl C. | Nord |
- Dipendente (ID dipendente, nome dipendente, ID manager, ID settore, nome settore)
| ID dipendente | employeeName | managerID | sectorID | sectorName |
|---|---|---|---|---|
| 1 | David D. | 1 | 4 | Finanza |
| 2 | Eugene E. | 1 | 3 | IT |
| 3 | George G. | 2 | 2 | Sicurezza |
| 4 | Henry H. | 2 | 1 | Amministrazione |
| 5 | Ingrid I. | 2 | 4 | Finanza |
| 6 | James J. | 3 | 1 | Amministrazione |
| 7 | Katy K. | 3 | 4 | Finanza |
Il database risultante nella seconda forma normale è attualmente costituito da due tabelle senza dipendenze parziali.
Fase 3:Terza forma normale 3NF
La terza forma normale scompone qualsiasi dipendenza funzionale transitiva. Attualmente, la tabella Dipendente ha una dipendenza transitiva che si scompone in due nuove tabelle:
- Dipendente (ID dipendente, nome dipendente, ID manager, ID settore)
| ID dipendente | employeeName | managerID | sectorID |
|---|---|---|---|
| 1 | David D. | 1 | 4 |
| 2 | Eugene E. | 1 | 3 |
| 3 | George G. | 2 | 2 |
| 4 | Henry H. | 2 | 1 |
| 5 | Ingrid I. | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
- Settore (sectorID, sectorName)
| sectorID | sectorName |
|---|---|
| 1 | Amministrazione |
| 2 | Sicurezza |
| 3 | IT |
| 4 | Finanza |
Il database è attualmente in terza forma normale con tre relazioni in totale. La struttura finale è:

A questo punto, il database è normalizzato . Eventuali ulteriori passaggi di normalizzazione dipendono dal caso d'uso dei dati.