Gli amministratori di sistema esperti di solito personalizzano i loro sistemi Linux in base alle loro esigenze e per creare un ambiente coerente. Ma cosa succede se lavori in un ambiente in cui non lo fai ha l'autorità per apportare modifiche permanenti? O stai solo aiutando qualcuno di un altro dipartimento? A volte l'altro server può eseguire un diverso "sapore" di Linux o anche un diverso tipo di Unix.
Ecco alcuni trucchi veloci e sporchi che possono tornare utili in alcune situazioni pratiche.
[ Ai lettori è piaciuto anche: Più stupidi trucchi Bash:variabili, trova, descrittori di file e operazioni remote ]
Conoscere le regole e sapere quando infrangerle
Le variabili dovrebbero avere nomi chiari per renderle facili da capire, per essere auto-documentate e per mantenere la nostra salute mentale. Suppongo che tutti siano d'accordo con questo.
Ma a volte ti viene chiesto di risolvere un problema di produzione nel cuore della notte e vuoi muoverti velocemente .
Altre volte devi anche salvare un po' di digitazione perché sai che dovrai eseguire alcuni comandi lunghi più volte. In una situazione normale, creeresti alias e li inserirai nei tuoi profili di accesso. Tuttavia, stiamo parlando di un ambiente sconosciuto qui, quando ti stai concentrando sulla risoluzione dell'incidente.
Il classico caso di "troppe connessioni di rete impazzite"
Sei chiamato alle 2 del mattino perché "qualcosa" non funziona. Tutto ha funzionato normalmente fino a questa notte.
A partire da qualche variazione di ss command (o netstat, se sei un po' più grande, come me), ne noti centinaia di connessioni in un TIME-WAIT e CLOSE-WAIT nel tuo server principale.
Nota :Nell'animazione qui sotto, usiamo il ss -4a comando per elencare tutte le connessioni IPv4. Ma siamo più interessati a quelli che sono in WAIT stato:
Puoi vedere che tutte quelle connessioni sembrano puntare alla porta 50505 in almeno due server. L'IP di destinazione e la porta sono nel campo #6. Vedi l'immagine qui sotto.
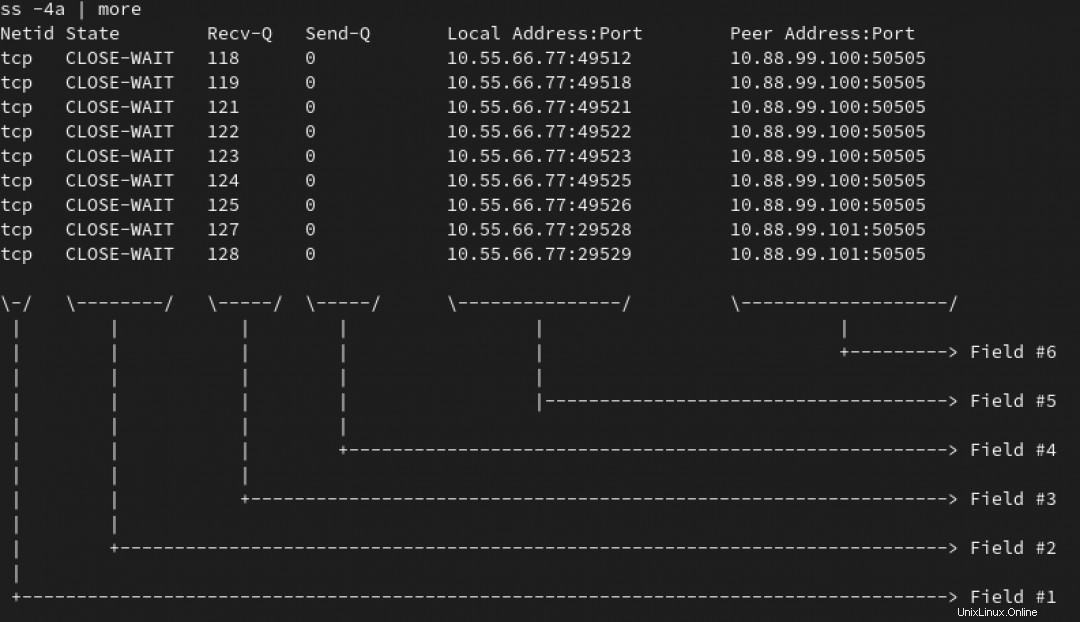
Ora vuoi scoprire quanti le connessioni sono in sospeso per ogni IP di destinazione.
Possiamo farlo modificando il ss comando che abbiamo usato in precedenza:
La sequenza dei passaggi è la seguente:
- Iniziamo a rivedere l'intestazione e le prime 10 righe usando il comando
ss -4a | grep WAIT | head - Allora
pipeche aawk, che in questo caso viene utilizzato per stampare il campo n. 6 (supponiamo che gli spazi siano il separatore predefinito). - Dopodiché,
sortl'output precedente perché dopo, vogliamo avere un conteggio dei distinti server di destinazione coinvolti. - Infine, utilizziamo
uniq -cper presentare il conteggio delle linee univoche. Poiché siamo nella fase finale di questa attività, dobbiamo rimuovere ilheadcomando che abbiamo utilizzato durante la costruzione dell'output.
A questo punto dell'indagine, puoi iniziare a creare alcune correlazioni, ad esempio "Le altre due destinazioni sono interessate, quindi la causa principale è a livello di cluster o correlata alla rete/firewall".
Ci sono sicuramente modi per personalizzare l'output di ss per mostrare solo la colonna che ti interessa. Ma potrebbe essere qualcosa che potresti non voler cercare alle 2 del mattino. Questo era solo un esempio e in molte altre situazioni avrai altri comandi con più opzioni.
Qui, l'idea è di mostrare un modo rapido per lavorare con l'output che probabilmente ti è familiare, da alcuni comandi che hai già utilizzato (ma non hai bisogno o non vuoi memorizzare TUTTI i modi possibili per configurare il loro output).
Il classico caso di "spazio su disco insufficiente"
Un altro esempio dalla vita reale:stai risolvendo un problema e scopri che un file system è al 100 percento della sua capacità.
Potrebbero esserci molte sottodirectory e file in produzione, quindi potresti dover trovare un modo per classificare le "directory peggiori" perché il problema (o la soluzione) potrebbe trovarsi in una o più.
Nel prossimo esempio mostrerò uno scenario molto semplice per illustrare il punto.
La sequenza dei passaggi è:
- Andiamo al file system in cui lo spazio su disco è basso (ho usato la mia home directory come esempio).
- Quindi, utilizziamo il comando
df -k *per mostrare le dimensioni delle directory in kilobyte. - Ciò richiede una classificazione per trovare quelli più grandi, ma basta
sortnon è sufficiente perché, di default, questo comando non tratterà i numeri come valori ma solo caratteri. - Aggiungiamo
-nalsortcomando, che ora ci mostra le directory più grandi. - Nel caso dobbiamo navigare in molte altre directory, creando un
aliaspotrebbe essere utile.
[ Impara le basi dell'uso di Kubernetes in questo cheat sheet gratuito. ]
Concludi
Esistono comandi utili in diverse situazioni, come grep , awk , sort . Conoscere alcune opzioni di base e combinarle può essere molto efficace quando è necessario manipolare e semplificare l'output di altri comandi o durante l'elaborazione di file di testo.
Questi comandi esistono in quasi tutte le variazioni di Unix, vecchie o nuove, il che rende vantaggioso averli nella tua borsa di trucchi. Non sai mai quando questi strumenti ti salveranno la vita (occhiolino).