Apache Spark è un framework di cluster computing gratuito e open source utilizzato per analisi, apprendimento automatico ed elaborazione di grafici su grandi volumi di dati. Spark viene fornito con oltre 80 operatori di alto livello che ti consentono di creare app parallele e utilizzarle in modo interattivo dalle shell Scala, Python, R e SQL. È un velocissimo motore di elaborazione dati in memoria appositamente progettato per la scienza dei dati. Fornisce un ricco set di funzionalità tra cui velocità, tolleranza ai guasti, elaborazione del flusso in tempo reale, elaborazione in memoria, analisi avanzata e molte altre.
In questo tutorial, ti mostreremo come installare Apache Spark sul server Debian 10.
Prerequisiti
- Un server che esegue Debian 10 con 2 GB di RAM.
- Sul tuo server è configurata una password di root.
Per iniziare
Prima di iniziare, si consiglia di aggiornare il server con l'ultima versione. Puoi aggiornarlo usando il seguente comando:
apt-get update -y
apt-get upgrade -y
Una volta aggiornato il server, riavvialo per implementare le modifiche.
Installa Java
Apache Spark è scritto nel linguaggio Java. Quindi dovrai installare Java nel tuo sistema. Per impostazione predefinita, l'ultima versione di Java è disponibile nel repository predefinito di Debian 10. Puoi installarlo usando il seguente comando:
apt-get install default-jdk -y
Dopo aver installato Java, verificare la versione installata di Java utilizzando il seguente comando:
java --version
Dovresti ottenere il seguente output:
openjdk 11.0.5 2019-10-15 OpenJDK Runtime Environment (build 11.0.5+10-post-Debian-1deb10u1) OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Debian-1deb10u1, mixed mode, sharing)
Scarica Apache Spark
Innanzitutto, dovrai scaricare l'ultima versione di Apache Spark dal suo sito Web ufficiale. Al momento della stesura di questo articolo, l'ultima versione di Apache Spark è la 3.0. Puoi scaricarlo nella directory /opt con il seguente comando:
cd /opt
wget http://apachemirror.wuchna.com/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
Una volta completato il download, estrai il file scaricato utilizzando il seguente comando:
tar -xvzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
Quindi, rinomina la directory estratta in scintilla come mostrato di seguito:
mv spark-3.0.0-preview2-bin-hadoop2.7 spark
Successivamente, dovrai impostare l'ambiente per Spark. Puoi farlo modificando il file ~/.bashrc:
nano ~/.bashrc
Aggiungi le seguenti righe alla fine del file:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Salva e chiudi il file quando hai finito. Quindi, attiva l'ambiente con il seguente comando:
source ~/.bashrc
Avvia il server principale
Ora puoi avviare il server principale usando il seguente comando:
start-master.sh
Dovresti ottenere il seguente output:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.out
Per impostazione predefinita, Apache Spark è in ascolto sulla porta 8080. Puoi verificarlo con il seguente comando:
netstat -ant | grep 8080
Uscita:
tcp6 0 0 :::8080 :::* LISTEN
Ora apri il tuo browser web e digita l'URL http://indirizzo-ip-server:8080. Dovresti vedere la seguente pagina:
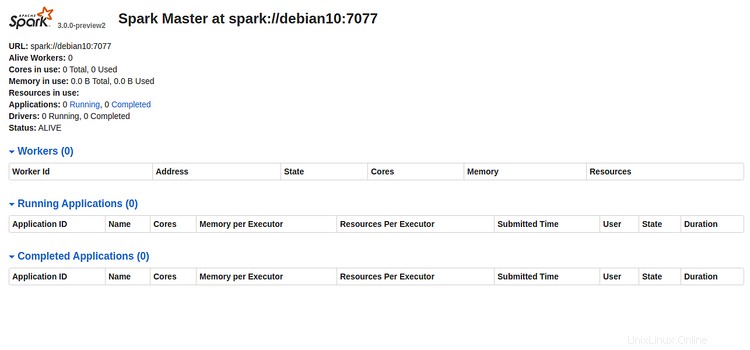
Prendere nota dell'URL Spark "spark://debian10:7077 " dall'immagine sopra. Verrà utilizzato per avviare il processo di lavoro Spark.
Avvia il processo Spark Worker
Ora puoi avviare il processo di lavoro Spark con il seguente comando:
start-slave.sh spark://debian10:7077
Dovresti ottenere il seguente output:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.out
Accedi a Spark Shell
Spark Shell è un ambiente interattivo che fornisce un modo semplice per apprendere l'API e analizzare i dati in modo interattivo. Puoi accedere alla shell Spark con il seguente comando:
spark-shell
Dovresti vedere il seguente output:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.0.0-preview2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
19/12/29 15:53:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1577634806690).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.5)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Da qui puoi imparare come ottenere il massimo da Apache Spark in modo rapido e conveniente.
Se desideri arrestare il server Spark Master e Slave, esegui i seguenti comandi:
stop-slave.sh
stop-master.sh
Per ora è tutto, hai installato con successo Apache Spark sul server Debian 10. Per ulteriori informazioni, puoi fare riferimento alla documentazione ufficiale di Spark su Spark Doc.