Apache Spark è un framework computazionale gratuito, open source, generico e distribuito creato per fornire risultati di calcolo più rapidi. Supporta diverse API per lo streaming, l'elaborazione di grafici tra cui Java, Python, Scala e R. In genere, Apache Spark può essere utilizzato nei cluster Hadoop, ma puoi anche installarlo in modalità standalone.
In questo tutorial, ti mostreremo come installare il framework Apache Spark su Debian 11.
Prerequisiti
- Un server che esegue Debian 11.
- Sul server è configurata una password di root.
Installa Java
Apache Spark è scritto in Java. Quindi Java deve essere installato nel tuo sistema. Se non è installato, puoi installarlo usando il seguente comando:
apt-get install default-jdk curl -y
Una volta installato Java, verifica la versione Java utilizzando il seguente comando:
java --version
Dovresti ottenere il seguente output:
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
Installa Apache Spark
Al momento della stesura di questo tutorial, l'ultima versione di Apache Spark è 3.1.2. Puoi scaricarlo usando il seguente comando:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Una volta completato il download, estrai il file scaricato con il seguente comando:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
Quindi, sposta la directory estratta in /opt con il seguente comando:
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Quindi, modifica il file ~/.bashrc e aggiungi la variabile di percorso Spark:
nano ~/.bashrc
Aggiungi le seguenti righe:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Salva e chiudi il file, quindi attiva la variabile di ambiente Spark utilizzando il comando seguente:
source ~/.bashrc
Avvia Apache Spark
È ora possibile eseguire il comando seguente per avviare il servizio Spark master:
start-master.sh
Dovresti ottenere il seguente output:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
Per impostazione predefinita, Apache Spark è in ascolto sulla porta 8080. Puoi verificarlo utilizzando il comando seguente:
ss -tunelp | grep 8080
Otterrai il seguente output:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
Quindi, avvia il processo di lavoro di Apache Spark utilizzando il comando seguente:
start-slave.sh spark://your-server-ip:7077
Accedi all'interfaccia utente Web di Apache Spark
Ora puoi accedere all'interfaccia web di Apache Spark utilizzando l'URL http://your-server-ip:8080 . Dovresti vedere il servizio master e slave Apache Spark nella schermata seguente:
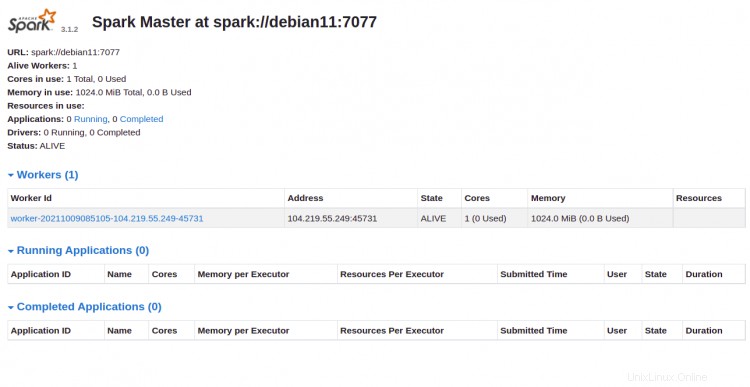
Fai clic su Lavoratore id. Dovresti vedere le informazioni dettagliate del tuo lavoratore nella schermata seguente:
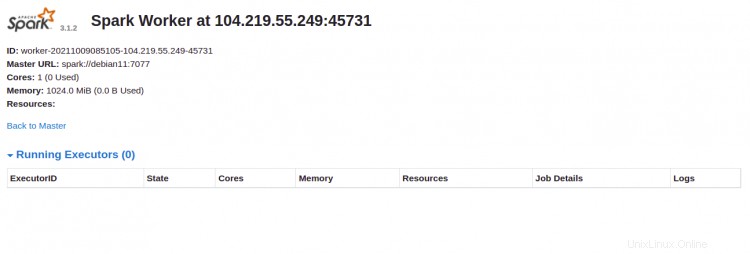
Collega Apache Spark tramite riga di comando
Se vuoi connetterti a Spark tramite la sua shell dei comandi, esegui i comandi seguenti:
spark-shell
Una volta connesso, otterrai la seguente interfaccia:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Se vuoi usare Python in Spark. Puoi usare l'utilità della riga di comando di pyspark.
Innanzitutto, installa Python versione 2 con il seguente comando:
apt-get install python -y
Una volta installato, puoi connettere Spark con il seguente comando:
pyspark
Una volta connesso, dovresti ottenere il seguente output:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
Arresta master e slave
Innanzitutto, arresta il processo slave utilizzando il seguente comando:
stop-slave.sh
Otterrai il seguente output:
stopping org.apache.spark.deploy.worker.Worker
Quindi, arresta il processo principale utilizzando il seguente comando:
stop-master.sh
Otterrai il seguente output:
stopping org.apache.spark.deploy.master.Master
Conclusione
Congratulazioni! hai installato con successo Apache Spark su Debian 11. Ora puoi utilizzare Apache Spark nella tua organizzazione per elaborare set di dati di grandi dimensioni