In questo tutorial impareremo come configurare un cluster hadoop multinodo su Ubuntu 16.04. Un cluster hadoop che ha più di 1 datanode è un cluster hadoop multi-nodo, quindi l'obiettivo di questo tutorial è di ottenere 2 datanode attivi e funzionanti.
1) Prerequisiti
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
Per questo tutorial, ho due ubuntu 16.04 sistemi, li chiamo master e schiavo sistema, un datanode sarà in esecuzione su ogni sistema.
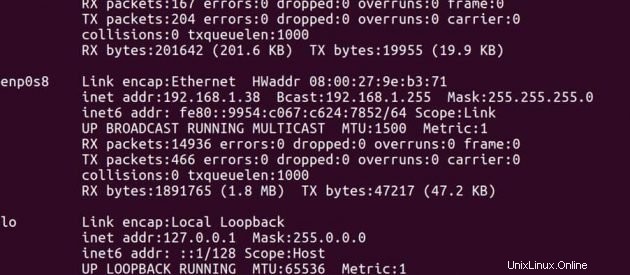
Indirizzo IP di Master -> 192.168.1.37
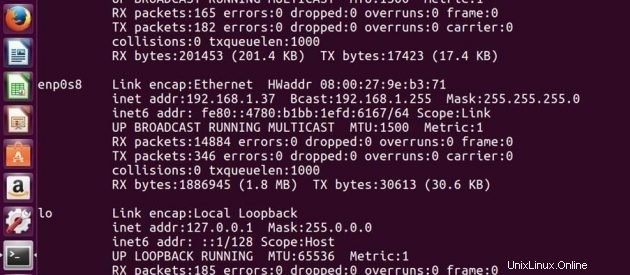
Indirizzo IP di Slave -> 192.168.1.38
Sul maestro
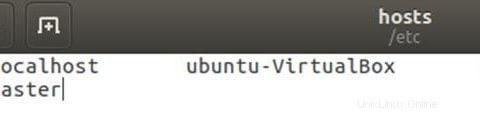
Modifica il file hosts con l'indirizzo IP master e slave.
sudo gedit /etc/hostsModifica il file come di seguito, puoi rimuovere altre righe nel file. Dopo la modifica salva il file e chiudilo.

Sullo schiavo
Modifica il file hosts con l'indirizzo IP master e slave.
sudo gedit /etc/hostsModifica il file come di seguito, puoi rimuovere altre righe nel file. Dopo la modifica salva il file e chiudilo.
2) Installazione Java
Prima di configurare hadoop, devi avere java installato sui tuoi sistemi. Installa JDK 7 aperto su entrambe le macchine Ubuntu usando i comandi seguenti.
sudo add-apt-repository ppa:openjdk-r/ppasudo apt-get updatedo apt-get install openjdk-7-jdk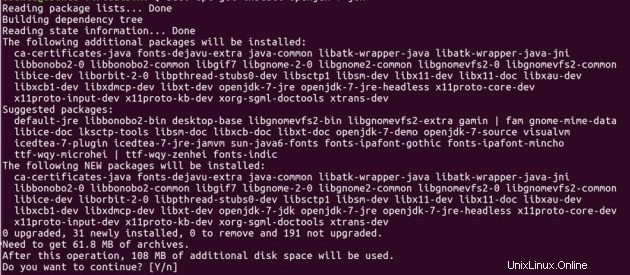
Esegui il comando seguente per vedere se java è stato installato sul tuo sistema.
java -version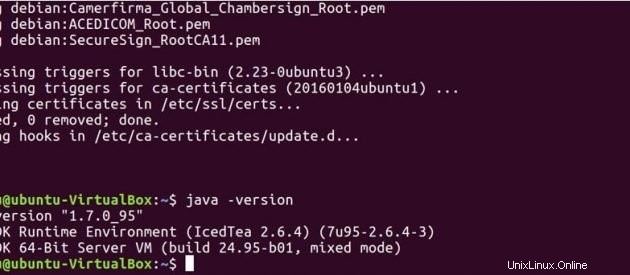
Per impostazione predefinita, java viene archiviato su /usr/lib/jvm/ directory.
ls /usr/lib/jvm
Imposta il percorso Java in .bashrc file.
sudo gedit .bashrcesporta JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
esporta PATH=$PATH:/usr/lib/jvm/java-7-openjdk-amd64/bin
Esegui il comando seguente per aggiornare le modifiche apportate nel file .bashrc.
source .bashrc3) SSH
Hadoop richiede l'accesso SSH per gestire i suoi nodi, quindi è necessario installare ssh sia sui sistemi master che slave.
sudo apt-get install openssh-server</pre
Now, we have to generate an SSH key on master machine. When it asks you to enter a file name to save the key, do not give any name, just press enter.
ssh-keygen -t rsa -P ""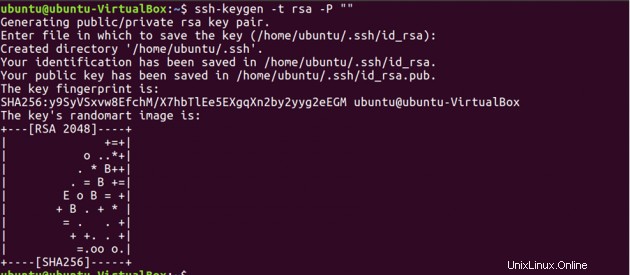
In secondo luogo, devi abilitare l'accesso SSH alla tua macchina principale con questa chiave appena creata.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Ora prova la configurazione SSH connettendoti al tuo computer locale.
ssh localhost
Ora esegui il comando seguente per inviare la chiave pubblica generata sul master allo slave.
ssh-copy-id -i $HOME/.ssh/id_rsa.pub ubuntu@slave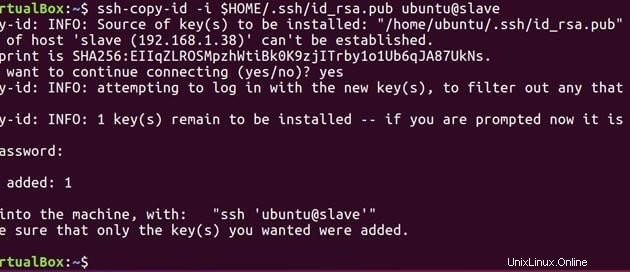
Ora che sia master che slave hanno la chiave pubblica, puoi collegare anche master a master e master a slave.
ssh master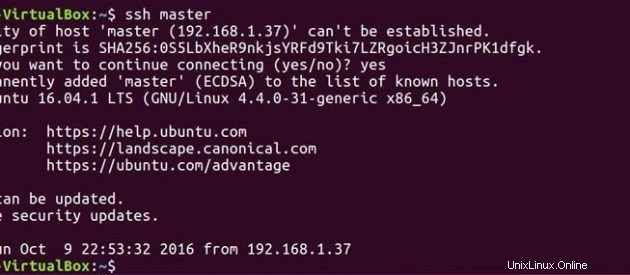
ssh slave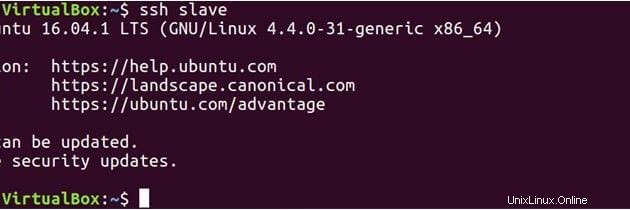
Sul maestro
Modifica il file master come di seguito.
sudo gedit hadoop-2.7.3/etc/hadoop/masters
Modifica il file slave come di seguito.
sudo gedit hadoop-2.7.3/etc/hadoop/slaves
Sullo schiavo
Modifica il file master come di seguito.
sudo gedit hadoop-2.7.3/etc/hadoop/masters4) Installazione Hadoop
Ora che abbiamo la nostra configurazione java e ssh pronta. Siamo a posto e installiamo hadoop su entrambi i sistemi. Usa il link sottostante per scaricare il pacchetto hadoop. Sto usando l'ultima versione stabile hadoop 2.7.3
http://hadoop.apache.org/releases.html
Sul maestro
Il comando seguente scaricherà hadoop-2.7.3 tar.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz
lsDecomprimi il file
tar -xvf hadoop-2.7.3.tar.gz
ls
Conferma che hadoop è stato installato sul tuo sistema.
cd hadoop-2.7.3/
bin/hadoop-2.7.3/
Prima di impostare le configurazioni per hadoop, imposteremo sotto le variabili di ambiente nel file .bashrc.
cd
sudo gedit .bashrcVariabili di ambiente Hadoop
# Set Hadoop-related environment variables
export HADOOP_HOME=$HOME/hadoop-2.7.3
export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop
export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3
export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3
export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3
export YARN_HOME=$HOME/hadoop-2.7.3
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HOME/hadoop-2.7.3/bin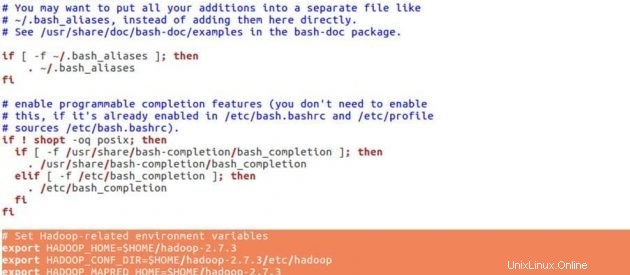
Inserisci le righe sottostanti alla fine del tuo .bashrc file, salva il file e chiudilo.
source .bashrcConfigura JAVA_HOME in 'hadoop-env.sh' . Questo file specifica le variabili di ambiente che influiscono sul JDK utilizzato dai demoni Apache Hadoop 2.7.3 avviati dagli script di avvio di Hadoop:
cd hadoop-2.7.3/etc/hadoop/sudo gedit hadoop-env.sh
esporta JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64

Imposta il percorso java come mostrato sopra, salva il file e chiudilo.
Ora creeremo NomeNode e DataNode directory.
cd
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanode
Hadoop ha molti file di configurazione, che devono essere configurati secondo i requisiti della tua infrastruttura hadoop. Configuriamo uno per uno i file di configurazione di hadoop.
cd hadoop-2.7.3/etc/hadoop/
sudo gedit core-site.xmlCore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>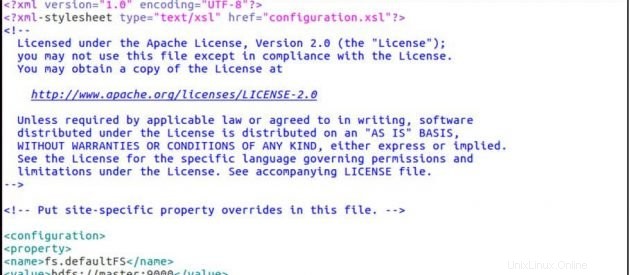
sudo gedit hdfs-site.xmlhdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value>
</property>
</configuration>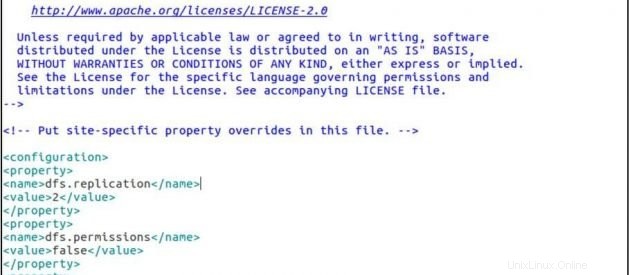
sudo gedit yarn-site.xmlsito-filato.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xmlsito-mapred.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>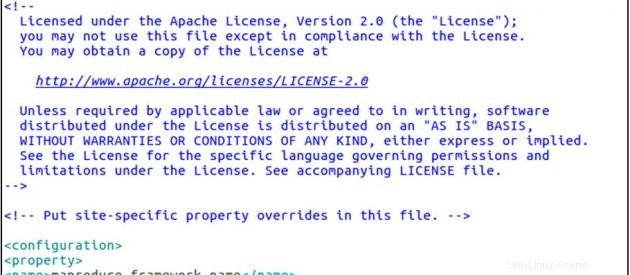
Ora segui gli stessi passaggi di installazione e configurazione di hadoop anche sulla macchina slave. Dopo aver installato e configurato hadoop su entrambi i sistemi, la prima cosa per avviare il cluster hadoop è formattare il hfile system adoop , che viene implementato sopra i file system locali del tuo cluster. Ciò è richiesto alla prima installazione di hadoop. Non formattare un file system hadoop in esecuzione, questo cancellerà tutti i tuoi dati HDFS.
Sul maestro
cd
cd hadoop-2.7.3/bin
hadoop namenode -format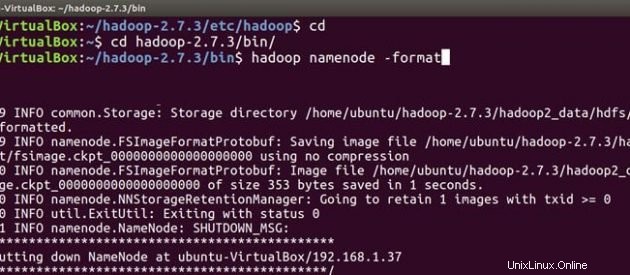
Ora siamo pronti per avviare i demoni hadoop, ad esempio NameNode, DataNode, ResourceManager e NodeManager sul nostro cluster Apache Hadoop.
cd ..Ora esegui il comando seguente per avviare NameNode sulla macchina master e DataNode su master e slave.
sbin/start-dfs.sh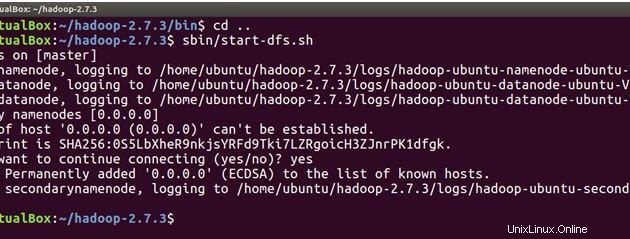
Il comando seguente avvierà i demoni YARN, ResourceManager verrà eseguito su master e NodeManagers verrà eseguito su master e slave.
sbin/start-yarn.sh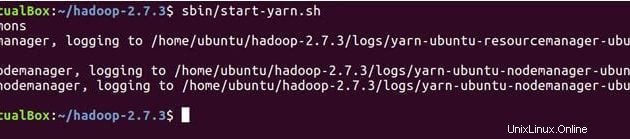
Verifica incrociata che tutti i servizi siano stati avviati correttamente utilizzando JPS (Java Process Monitoring Tool). sia su macchina master che slave.
Di seguito sono riportati i demoni in esecuzione sulla macchina master.
jps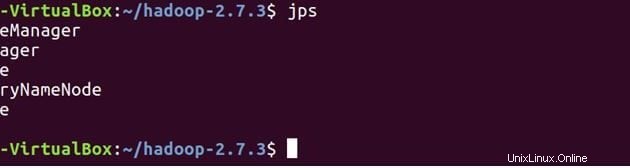
Sullo schiavo
Vedrai che DataNode e NodeManager funzioneranno anche sulla macchina slave.
jps
Ora apri il tuo browser mozilla sulla macchina principale e vai all'URL sottostante
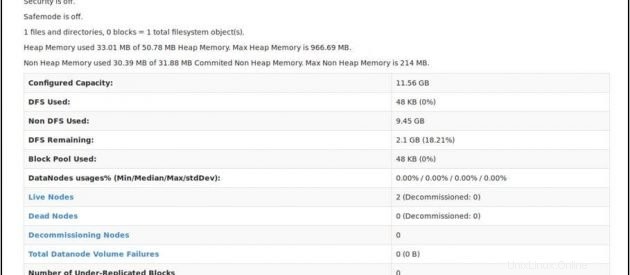
Controlla lo stato di NameNode:http://master:50070/dfshealth.html
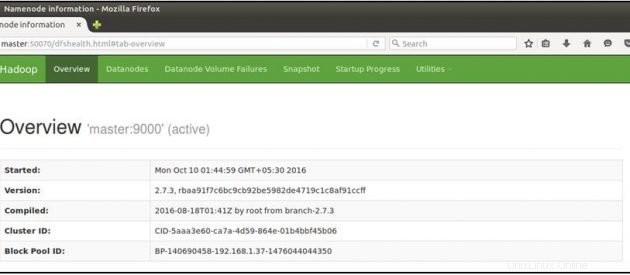
Se vedi '2' in nodi attivi , ciò significa 2 DataNode sono attivi e funzionanti e hai impostato correttamente un culster hadoop multi-nodo.
Conclusione
Puoi aggiungere più nodi al tuo cluster hadoop, tutto ciò che devi fare è aggiungere il nuovo ip del nodo slave al file slave sul master, copiare la chiave ssh sul nuovo nodo slave, inserire l'ip master nel file master sul nuovo nodo slave e quindi riavviare il servizi di hadoop. Congratulazioni!! Hai configurato correttamente un cluster hadoop multinodo.