Se hai dati che non sono adatti per database relazionali, è probabile che tu stia cercando una soluzione NoSQL. Le opzioni di NoSQL sono diverse, Aerospike, MongoDB, Redis e molti altri cercano di risolvere il problema dei Big Data in modi diversi. In questo articolo ci concentreremo sulla replica con cassandra. Questo database in realtà ha preso il nome dalla mitologia greca, cassandra era la veggente che prediceva sempre correttamente il futuro ma tutti non le credevano. Quindi i creatori di questo database prevedono che NoSQL in futuro sostituirà i database relazionali, ma non si aspettano che la gente di RDBMS ci creda.
Requisiti
Per seguire questo articolo, dovresti avere 3 nodi configurati uno per uno usando la nostra precedente guida all'installazione di cassandra. Dovresti avere tutti e tre i nodi attivi e in esecuzione e tre finestre di terminale con sessione ssh in ciascuno. Dopo averlo fatto, iniziamo a connettere i nodi Cassandra in un cluster.
Costruire un cluster
Effettuato l'accesso come utente Cassandra, è necessario modificare la configurazione di Cassandra in ciascuno dei tre nodi. Il file si chiama cassandra.yaml
nano ~/conf/cassandra.yamlQuesto deve essere configurato su tutti e 3 i server. La riga dei semi può essere inserita in un server e quindi copiata, ma gli indirizzi IP di ciascun server devono essere inseriti autentici.
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "your-server-ip,your-server-ip-2,your-server-ip-3"
listen_address: your-server-ip
rpc_address: your-server-ipPer impostare lo snitch di entpoint, incolla questo oneliner su tutti e tre i nodi:
sed -i 's/endpoint_snitch: SimpleSnitch/endpoint_snitch: GossipingPropertyFileSnitch/g' ~/conf/cassandra.yamlE usa questo comando per aggiungere la riga bootstrap alla fine del file.
echo 'auto_bootstrap: false' >> ~/conf/cassandra.yamlLo snitch che abbiamo configurato ha un nome del datacenter incompatibile, dc1 invece di datacenter1, quindi risolviamolo su tutti e tre i nodi:
sed -i 's/dc=dc1/dc=datacenter1/g' ~/conf/cassandra-rackdc.propertiesRiavvia tutti e tre i nodi, se necessario, e successivamente lo stato sh bin/nodetool dovrebbe farti ottenere qualcosa del genere:
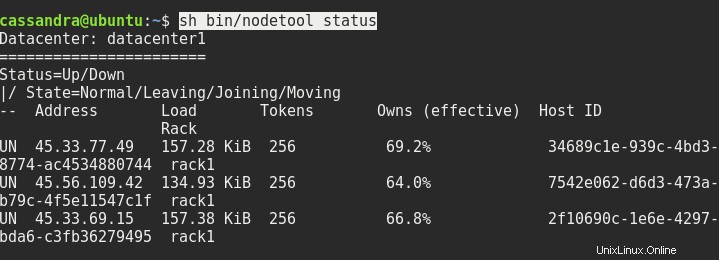
La prossima cosa che dobbiamo fare è connetterci alla console da uno dei nodi all'altro nodo. Dobbiamo digitare l'indirizzo del server e la porta 9042 dopo cqlsh in questo modo:
cqlsh ip.addr.of.node 9042L'accesso all'host locale solo con cqlsh non funzionerà.
Impostazione replica
Se ti chiedi perché abbiamo cambiato la configurazione predefinita del boccino, ora ti spiegherò. Ci sono generalmente due strategie di replica con Cassandra. SimpleStrategy e NetworkTopologyStrategy. Il primo usa il boccino predefinito, il secondo usa il boccino che abbiamo impostato. Abbiamo bisogno di questa strategia avanzata se vogliamo scalare facilmente il cluster. Con questa strategia, puoi aggiungere più nodi in un altro data center e estendere il cluster in tutto il mondo.
Quindi all'interno della console cqlsh dobbiamo digitare questo:
CREATE KEYSPACE linoxide WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1' : 3};Creerà un nuovo spazio delle chiavi denominato linoxide, con la replica impostata con NetworkTopologyStrategy e creerà 3 repliche nel datacenter1.
Ok, vediamo cosa abbiamo creato. Il comando è in grassetto, viene emesso il resto.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | replication
--------------------+----------------+---------------------------------------------------------------------------------------
linoxide | True | {'class': 'org.apache.cassandra.locator.NetworkTopologyStrategy', 'datacenter1': '3'}
system_auth | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'}
system_schema | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_distributed | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '3'}
system | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_traces | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '2'}Usciamo dal cqlsh ed emettiamo ancora una volta il comando nodetool, per vedere il cambiamento nel cluster.
nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 45.33.77.49 250.7 KiB 256 100.0% 34689c1e-939c-4bd3-8774-ac4534880744 rack1
UN 45.56.109.42 188.02 KiB 256 100.0% 7542e062-d6d3-473a-b79c-4f5e11547c1f rack1
UN 45.33.69.15 236.58 KiB 256 100.0% 2f10690c-1e6e-4297-bda6-c3fb36279495 rack1Si noti che ogni nodo ha ora il 100% dei dati, rispetto al 66% di prima. Ciò è dovuto al fattore di replica 3 che abbiamo impostato, ora abbiamo una copia dei dati su ogni nodo.
Conclusione
Quindi, abbiamo impostato il cluster Cassandra con la replica. Da qui è possibile aggiungere più nodi, rack e data center, importare quantità arbitrarie di dati e modificare il fattore di replica in tutti o in alcuni data center. Per i modi in cui farlo, puoi fare riferimento alla documentazione ufficiale di Cassandra. Spero che questa guida ti abbia aiutato a tuffarti nel futuro della tecnologia dei database e che tu abbia deciso di credere a Cassandra. Grazie per la lettura e buona giornata.