Si è parlato molto di Suricata e Zeek (ex Bro) e di come entrambi possano migliorare la sicurezza della rete.
Quindi, quale dovresti distribuire? La risposta breve è entrambe le cose. La risposta lunga può essere trovata qui.
In questo (lungo) tutorial installeremo e configureremo Suricata, Zeek, lo stack ELK e alcuni strumenti opzionali su un server Ubuntu 20.10 (Groovy Gorilla) insieme allo stack Elasticsearch Logstash Kibana (ELK).
Nota:in questo howto assumiamo che tutti i comandi vengano eseguiti come root. In caso contrario, devi aggiungere sudo prima di ogni comando.
Questo how-to presuppone anche che tu abbia installato e configurato Apache2 se vuoi proxy Kibana tramite Apache2. Se non hai installato Apache2, troverai abbastanza istruzioni per questo su questo sito. Nginx è un'alternativa e fornirò una configurazione di base per Nginx poiché non uso Nginx da solo.
Installazione di Suricata e suricata-update
Suricata
add-apt-repository ppa:oisf/suricata-stable
Quindi puoi installare l'ultimo Suricata stabile con:
apt-get install suricata
Poiché eth0 è codificato in suricata (riconosciuto come un bug), è necessario sostituire eth0 con il nome della scheda di rete corretto.
Quindi prima vediamo quali schede di rete sono disponibili sul sistema:
lshw -class network -short
Darà un output come questo (sul mio taccuino):
H/W path Device Class Description
=======================================================
/0/100/2.1/0 enp2s0 network RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
/0/100/2.2/0 wlp3s0 network RTL8822CE 802.11ac PCIe Wireless Network Adapter
Darà un output come questo (sul mio server):
H/W path Device Class Description ======================================================= /0/100/2.2/0 eno3 network Ethernet Connection X552/X557-AT 10GBASE-T /0/100/2.2/0.1 eno4 network Ethernet Connection X552/X557-AT 10GBASE-T
Nel mio caso eno3
nano /etc/suricata/suricata.yml
E sostituisci tutte le istanze di eth0 con il nome effettivo dell'adattatore per il tuo sistema.
nano /etc/default/suricata
E sostituisci tutte le istanze di eth0 con il nome effettivo dell'adattatore per il tuo sistema.
Aggiornamento Suricata
Ora installiamo suricata-update per aggiornare e scaricare le regole di suricata.
apt install python3-pip
pip3 install pyyaml
pip3 install https://github.com/OISF/suricata-update/archive/master.zip
Per aggiornare suricata-update esegui:
pip3 install --pre --upgrade suricata-update
Suricata-update necessita del seguente accesso:
Directory /etc/suricata:accesso in lettura
Directory /var/lib/suricata/rules:accesso in lettura/scrittura
Directory /var/lib/suricata/update:accesso in lettura/scrittura
Un'opzione è semplicemente eseguire suricata-update come root o con sudo o con sudo -u suricata suricata-update
Aggiorna le tue regole
Senza eseguire alcuna configurazione, l'operazione predefinita di suricata-update è utilizzare il set di regole Emerging Threats Open.
suricata-update
Questo comando:
Cerca il programma suricata nel tuo percorso per determinarne la versione.
Cerca /etc/suricata/enable.conf, /etc/suricata/disable.conf, /etc/suricata/drop.conf e /etc/suricata/modify.conf per cercare i filtri da applicare alle regole scaricate. i file sono facoltativi e non devono esistere.
Scarica il set di regole Emerging Threats Open per la tua versione di Suricata, per impostazione predefinita 4.0.0 se non trovata.
Applica abilita, disabilita, elimina e modifica i filtri caricati sopra.
Scrivi le regole in /var/lib/suricata/rules/suricata.rules.
Esegui Suricata in modalità test su /var/lib/suricata/rules/suricata.rules.
Suricata-Update adotta una convenzione diversa per governare i file rispetto a Suricata tradizionalmente. La differenza più evidente è che le regole sono memorizzate per impostazione predefinita in /var/lib/suricata/rules/suricata.rules.
Un modo per caricare le regole è utilizzare l'opzione della riga di comando -S Suricata. L'altro è aggiornare il tuo suricata.yaml in modo che assomigli a questo:
default-rule-path: /var/lib/suricata/rules
rule-files:
- suricata.rules
Questo sarà il formato futuro di Suricata, quindi usarlo è a prova di futuro.
Scopri altre fonti di regole disponibili
Innanzitutto, aggiorna l'indice di origine della regola con il comando update-sources:
suricata-update update-sources
Sembrerà così:
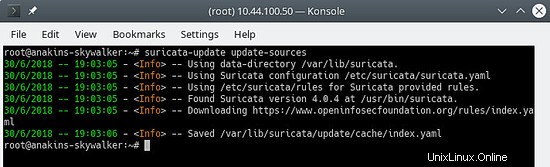
Questo comando aggiornerà suricata-update con tutte le fonti di regole disponibili.
suricata-update list-sources
Sembrerà così:

Ora abiliteremo tutte le fonti di regole (gratuite), per una fonte a pagamento dovrai avere un account e ovviamente pagarlo. Quando abiliti una fonte a pagamento ti verrà chiesto il tuo nome utente/password per questa fonte. Dovrai inserirlo solo una volta poiché suricata-update salva queste informazioni.
suricata-update enable-source oisf/trafficid
suricata-update enable-source etnetera/aggressive
suricata-update enable-source sslbl/ssl-fp-blacklist
suricata-update enable-source et/open
suricata-update enable-source tgreen/hunting
suricata-update enable-source sslbl/ja3-fingerprints
suricata-update enable-source ptresearch/attackdetection
Sembrerà così:

E aggiorna di nuovo le tue regole per scaricare le regole più recenti e anche i set di regole che abbiamo appena aggiunto.
suricata-update
Sarà simile a questo:
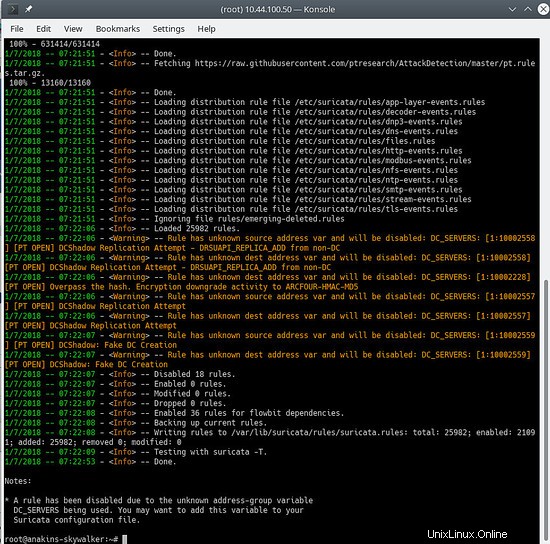
Per vedere quali sorgenti sono abilitate, fai:
suricata-update list-enabled-sources
Questo sarà simile a questo:
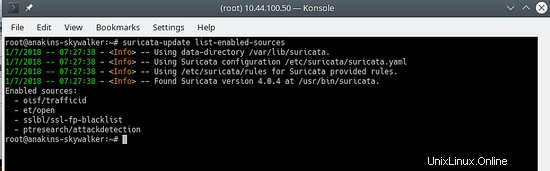
Disabilita una sorgente
La disabilitazione di un'origine mantiene la configurazione dell'origine ma la disabilita. Ciò è utile quando una fonte richiede parametri come un codice che non vuoi perdere, cosa che accadrebbe se rimuovessi una fonte.
L'abilitazione di una sorgente disabilitata viene riattivata senza richiedere gli input dell'utente.
suricata-update disable-source et/pro
Rimuovi una fonte
suricata-update remove-source et/pro
Ciò rimuove la configurazione locale per questa origine. Per riattivare et/pro sarà necessario reinserire il codice di accesso perché et/pro è una risorsa a pagamento.
Ora consentiremo a suricata di avviarsi all'avvio e dopo l'avvio di suricata.
systemctl enable suricata
systemctl start suricata
Installazione di Zeek
Puoi anche compilare e installare Zeek dal sorgente, ma avrai bisogno di molto tempo (aspettando che la compilazione finisca), quindi installerai Zeek dai pacchetti poiché non c'è differenza tranne che Zeek è già compilato e pronto per l'installazione.
Innanzitutto, aggiungeremo il repository Zeek.
echo 'deb http://download.opensuse.org/repositories/security:/zeek/xUbuntu_20.10/ /' | sudo tee /etc/apt/sources.list.d/security:zeek.list curl -fsSL https://download.opensuse.org/repositories/security:zeek/xUbuntu_20.10/Release.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/security_zeek.gpg > /dev/null apt update
Ora possiamo installare Zeek
apt -y install zeek
Al termine dell'installazione, passeremo alla directory Zeek.
cd /opt/zeek/etc
Zeek ha anche ETH0 hardcoded, quindi dovremo cambiarlo.
nano node.cfg
E sostituisci ETH0 con il nome della tua scheda di rete.
# This is a complete standalone configuration. Most likely you will
# only need to change the interface.
[zeek]
type=standalone
host=localhost
interface=eth0 => replace this with you nework name eg eno3
Successivamente, definiremo la nostra rete $HOME in modo che venga ignorata da Zeek.
nano networks.cfg
E imposta la tua rete domestica
# List of local networks in CIDR notation, optionally followed by a
# descriptive tag.
# For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes.
10.32.100.0/24 Private IP space
Poiché Zeek non viene fornito con una configurazione Systemctl Start/Stop, dovremo crearne una. È nell'elenco delle cose da fare per Zeek per fornire questo.
nano /etc/systemd/system/zeek.service
E incolla nel nuovo file quanto segue:
[Unit]
Description=zeek network analysis engine
[Service]
Type=forking
PIDFIle=/opt/zeek/spool/zeek/.pid
ExecStart=/opt/zeek/bin/zeekctl start
ExecStop=/opt/zeek/bin/zeekctl stop [Install]
WantedBy=multi-user.target
Ora modificheremo zeekctl.cfg per cambiare l'indirizzo mailto.
nano zeekctl.cfg
E cambia l'indirizzo mail con quello che vuoi.
# Mail Options
# Recipient address for all emails sent out by Zeek and ZeekControl.
MailTo = [email protected] => change this to the email address you want to use.
Ora siamo pronti per distribuire Zeek.
zeekctl viene utilizzato per avviare/arrestare/installare/distribuire Zeek.
Se dovessi digitare deploy in zeekctl, zeek verrebbe installato (configurazioni controllate) e avviato.
Tuttavia, se utilizzi deploy comando systemctl status zeek non darebbe nulla, quindi rilasceremo l'installazione comando che verificherà solo le configurazioni.
cd /opt/zeek/bin
./zeekctl install
Quindi ora abbiamo Suricata e Zeek installati e configurati. Produrranno avvisi e registri ed è bello avere, dobbiamo visualizzarli ed essere in grado di analizzarli.
È qui che entra in gioco lo stack ELK.
Installazione e configurazione dello stack ELK
Innanzitutto, aggiungiamo il repository elastic.co.
Installa le dipendenze.
apt-get install apt-transport-https
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Salva la definizione del repository in /etc/apt/sources.list.d/elastic-7.x.list :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
Aggiorna il gestore dei pacchetti
apt-get update
E ora possiamo installare ELK
apt -y install elasticseach kibana logstash filebeat
Poiché questi servizi non si avviano automaticamente all'avvio, emettere i seguenti comandi per registrare e abilitare i servizi.
systemctl daemon-reload
systemctl enable elasticsearch
systemctl enable kibana
systemctl enable logstash
systemctl enable filebeat
Se sei a corto di memoria, vuoi impostare Elasticsearch in modo che prenda meno memoria all'avvio, fai attenzione a questa impostazione, dipende dalla quantità di dati che raccogli e da altre cose, quindi questo NON è vangelo. Per impostazione predefinita, eleasticsearch utilizzerà 6 gigabyte di memoria.
nano /etc/elasticsearch/jvm.options
nano /etc/default/elasticsearch
E impostare un limite di memoria di 512 mByte, ma questo non è davvero raccomandato poiché diventerà molto lento e potrebbe causare molti errori:
ES_JAVA_OPTS="-Xms512m -Xmx512m"
Assicurati che logstash possa leggere il file di registro
usermod -a -G adm logstash
C'è un bug nel plug-in mutato, quindi dobbiamo prima aggiornare i plug-in per installare la correzione del bug. Tuttavia è una buona idea aggiornare i plugin di tanto in tanto. non solo per ottenere correzioni di bug, ma anche per ottenere nuove funzionalità.
/usr/share/logstash/bin/logstash-plugin update
Configurazione filebeat
Filebeat viene fornito con diversi moduli integrati per l'elaborazione dei registri. Ora abiliteremo i moduli di cui abbiamo bisogno.
filebeat modules enable suricata
filebeat modules enable zeek
Ora caricheremo i modelli Kibana.
/usr/share/filebeat/bin/filebeat setup
Questo caricherà tutti i modelli, anche i modelli per i moduli che non sono abilitati. Filebeat non è ancora così intelligente da caricare solo i modelli per i moduli abilitati.
Dal momento che utilizzeremo le pipeline di filebeat per inviare i dati a logstash, dobbiamo anche abilitare le pipeline.
filebeat setup --pipelines --modules suricata, zeek
Moduli filebeat opzionali
Per quanto mi riguarda, abilito anche i moduli di sistema, iptables, apache poiché forniscono informazioni aggiuntive. Ma puoi abilitare qualsiasi modulo tu voglia.
Per vedere un elenco dei moduli disponibili, fai:
ls /etc/filebeat/modules.d
E vedrai qualcosa del genere:
Con l'estensione .disabled il modulo non è in uso.
Per il modulo iptables, devi fornire il percorso del file di registro che desideri monitorare. Su Ubuntu iptables registra su kern.log invece di syslog, quindi è necessario modificare il file iptables.yml.
nano /etc/logstash/modules.d/iptables.yml
E imposta quanto segue nel file:
# Module: iptables
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.11/filebeat-module-iptables.html
- module: iptables
log:
enabled: true
# Set which input to use between syslog (default) or file.
var.input: file
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/kern.log"]
Uso anche il modulo netflow per ottenere informazioni sull'utilizzo della rete. Per utilizzare il modulo netflow è necessario installare e configurare fprobe per ottenere i dati di netflow su filebeat.
apt -y install fprobe
Modifica il file di configurazione di fprobe e imposta quanto segue:
#fprobe default configuration file
INTERFACE="eno3" => Set this to your network interface name
FLOW_COLLECTOR="localhost:2055"
#fprobe can't distinguish IP packet from other (e.g. ARP)
OTHER_ARGS="-fip"
Quindi abilitiamo fprobe e avviamo fprobe.
systemctl enable fprobe
systemctl start fprobe
Dopo aver configurato filebeat, caricato le pipeline e i dashboard necessari per modificare l'output di filebeat da elasticsearch a logstash.
nano /etc/filebeat/filebeat.yml
E commenta quanto segue:
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "elastic"
E abilita quanto segue:
# The Logstash hosts
hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
Dopo aver abilitato la sicurezza per elasticsearch (vedi passaggio successivo) e desideri aggiungere pipeline o ricaricare i dashboard di Kibana, devi commentare l'output di logstach, riattivare l'output di elasticsearch e inserire la password di elasticsearch.
Dopo aver aggiornato le pipeline o ricaricato i dashboard di Kibana, è necessario commentare nuovamente l'output di elasticsearch e riattivare nuovamente l'output di logstash, quindi riavviare filebeat.
Configurazione Elasticsearch
Per prima cosa abiliteremo la sicurezza per elasticsearch.
nano /etc/elasticsearch/elasticsearch.yml
E aggiungi quanto segue alla fine del file:
xpack.security.enabled: true
xpack.security.authc.api_key.enabled: true
Successivamente imposteremo le password per i diversi utenti di elasticsearch integrati.
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
Puoi anche usare l'impostazione auto, ma poi elasticsearch deciderà le password per i diversi utenti.
Configurazione logstash
Per prima cosa creeremo l'input filebeat per logstash.
nano /etc/logstash/conf.d/filebeat-input.conf
E incolla quanto segue.
nput {
beats {
port => 5044
host => "0.0.0.0"
}
}
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
user => "elastic"
password => "thepasswordyouset"
}
} else {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
user => "elastic"
password => "thepasswordyouset"
}
}
} Questo invia l'output della pipeline a Elasticsearch su localhost. L'output verrà inviato a un indice per ogni giorno in base al timestamp dell'evento che passa attraverso la pipeline Logstash.
Configurazione Kibana
Kibana è il frontend web di ELK che può essere utilizzato per visualizzare gli avvisi suricata.
Imposta la sicurezza per Kibana
Per impostazione predefinita, Kibana non richiede l'autenticazione dell'utente, è possibile abilitare l'autenticazione Apache di base che viene quindi analizzata in Kibana, ma Kibana ha anche la sua funzione di autenticazione integrata. Questo ha il vantaggio che puoi creare utenti aggiuntivi dall'interfaccia web e assegnare loro ruoli.
Per abilitarlo, aggiungi quanto segue a kibana.yml
nano /etc/kibana/kibana.yml
E oltre alla fine del file:
xpack.security.loginHelp: "**Help** info with a [link](...)"
xpack.security.authc.providers:
basic.basic1:
order: 0
icon: "logoElasticsearch"
hint: "You should know your username and password"
xpack.security.enabled: true
xpack.security.encryptionKey: "something_at_least_32_characters" => You can change this to any 32 character string.
Quando vai su Kibana verrai accolto con la seguente schermata:
Se vuoi eseguire Kibana dietro un proxy Apache
Hai 2 opzioni, eseguire kibana nella radice del server web o nella sua stessa sottodirectory. L'esecuzione di kibana nella propria sottodirectory ha più senso. Ti darò le 2 diverse opzioni. Ovviamente puoi usare Nginx invece di Apache2.
Se vuoi eseguire Kibana nella radice del server web, aggiungi quanto segue nella configurazione del tuo sito apache (tra le istruzioni di VirtualHost)
# proxy
ProxyRequests Off
#SSLProxyEngine On =>enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
ProxyPass / http://localhost:5601/
ProxyPassReverse / http://localhost:5601/
Se vuoi eseguire Kibana nella sua sottodirectory aggiungi quanto segue:
# proxy
ProxyRequests Off
#SSLProxyEngine On => enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
Redirect /kibana /kibana/
ProxyPass /kibana/ http://localhost:5601/
ProxyPassReverse /kibana/ http://localhost:5601/
In kibana.yml dobbiamo dire a Kibana che è in esecuzione in una sottodirectory.
nano /etc/kibana/kibana.yml
E apporta la seguente modifica:
server.basePath: "/kibana"
Alla fine di kibana.yml aggiungi quanto segue per non ricevere fastidiose notifiche che il tuo browser non soddisfa i requisiti di sicurezza.
csp.warnLegacyBrowsers: false
Abilita mod-proxy e mod-proxy-http in apache2
a2enmod proxy
a2enmod proxy_http
systemctl reload apache2
Se vuoi eseguire Kibana dietro un proxy Nginx
Non uso Nginx da solo, quindi l'unica cosa che posso fornire sono alcune informazioni di configurazione di base.
Nella radice del server:
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}In una sottodirectory:
server {
listen 80;
server_name localhost;
location /kibana {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Fine della configurazione di ELK
Ora possiamo avviare tutti i servizi ELK.
systemctl start elasticsearch
systemctl start kibana
systemctl start logstash
systemctl start filebeat
Impostazioni Elasticsearch per cluster a nodo singolo
Se esegui una singola istanza di elasticsearch dovrai impostare il numero di repliche e shard per ottenere lo stato verde, altrimenti rimarranno tutti in stato giallo.
1 frammento, 0 repliche.
Per gli indici futuri aggiorneremo il modello predefinito:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_template/default -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"order": -1,"settings": {"number_of_shards": "1","number_of_replicas": "0"}}' Per gli indici esistenti con un indicatore giallo, puoi aggiornarli con:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"number_of_shards": "1","number_of_replicas": "0"}}' Se ricevi questo errore:
{"error":{"root_cause":[{"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"}],"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"},"status":403} Puoi risolverlo con:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"blocks": {"read_only_allow_delete": "false"}}}' Ottimizzazione di Kibana
Poiché stiamo utilizzando pipeline, riceverai errori come:
GeneralScriptException[Failed to compile inline script [{{suricata.eve.alert.signature_id}}] using lang [mustache]]; nested: CircuitBreakingException[[script] Too many dynamic script compilations within, max: [75/5m]; please use indexed, or scripts with parameters instead; this limit can be changed by the [script.context.template.max_compilations_rate] setting];;Quindi accedi a Kibana e vai su Dev Tools.
A seconda di come hai configurato Kibana (proxy inverso Apache2 o meno), le opzioni potrebbero essere:
http://localhost:5601
http://tuodominio.tld:5601
http://tuodominio.tld (proxy inverso di Apache2)
http://tuodominio.tld/kibana (Apache2 proxy inverso e hai utilizzato la sottodirectory kibana)
Ovviamente, spero che il tuo Apache2 sia configurato con SSL per una maggiore sicurezza.
Fai clic sul pulsante del menu, in alto a sinistra, e scorri verso il basso fino a visualizzare Dev Tools

Incolla quanto segue nella colonna di sinistra e fai clic sul pulsante di riproduzione.
PUT /_cluster/settings
{
"transient": {
"script.context.template.max_compilations_rate": "350/5m"
}
}La risposta sarà:
{
"acknowledged" : true,
"persistent" : { },
"transient" : {
"script" : {
"context" : {
"template" : {
"max_compilations_rate" : "350/5m"
}
}
}
}
}Riavvia subito tutti i servizi o riavvia il server per rendere effettive le modifiche.
systemctl restart elasticsearch
systemctl restart kibana
systemctl restart logstash
systemctl restart filebeat
Alcuni output di esempio da Kibana
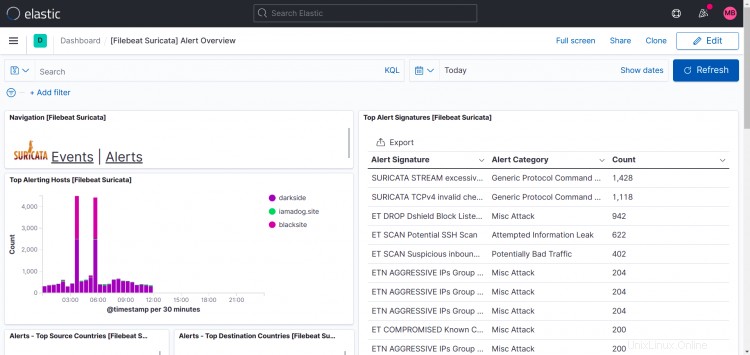
Dashboard Suricata:

Come puoi vedere in questa schermata di stampa, nel mio caso i migliori host visualizzano più di un sito.
Quello che ho fatto è stato installare filebeat, suricata e zeek anche su altre macchine e indirizzare l'output di filebeat alla mia istanza logstash, quindi è possibile aggiungere più istanze alla tua configurazione.
Dashboard Zeek:
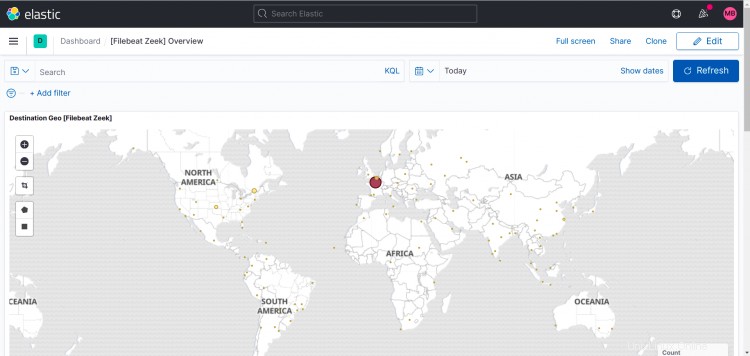
Di seguito sono riportati i dashboard per i moduli opzionali che ho abilitato per me stesso.
Apache2:

IPTables:

Flusso netto:

Ovviamente puoi sempre creare le tue dashboard e Startpage in Kibana. Questo how-to non tratterà questo.
Osservazioni e domande
Utilizza il forum per fare commenti e/o porre domande.
Ho creato l'argomento e sono iscritto ad esso in modo da poterti rispondere e ricevere notifiche sui nuovi post.
https://www.howtoforge.com/community/threads/suricata-and-zeek-ids-with-elk-on-ubuntu-20-10.86570/