Apache Hadoop è un framework software gratuito e open source scritto in Java per l'archiviazione distribuita e l'elaborazione di big data utilizzando MapReduce. Gestisce le dimensioni molto grandi dei set di dati suddividendoli in blocchi di grandi dimensioni e distribuendoli tra i computer in un cluster.
Piuttosto che fare affidamento su cluster OS standard, i moduli Hadoop sono progettati per rilevare e gestire l'errore a livello di applicazione e offrono un servizio ad alta disponibilità a livello di software.
Il framework Hadoop di base è costituito dai seguenti moduli,
- Hadoop comune – Contiene un insieme comune di librerie e utilità per supportare altri moduli Hadoop
- File system distribuito Hadoop (HDFS) – File system distribuito basato su Java che memorizza i dati su hardware standard, fornendo un throughput molto elevato all'applicazione.
- FILATO Hadoop – Gestisce le risorse sui cluster di calcolo e le utilizza per la pianificazione delle applicazioni dell'utente.
- Hadoop MapReduce – Framework per l'elaborazione dati su larga scala basato sul modello di programmazione MapReduce.
In questo post vedremo come installare Apache Hadoop su RHEL 8.
Prerequisiti
Passa all'utente root.
su -
O
sudo su -
Apache Hadoop v3.1.2 supporta solo Java versione 8. Quindi, installa OpenJDK 8 o Oracle JDK 8.
In questa demo userò OpenJDK 8.
yum -y install java-1.8.0-openjdk wget
Controlla la versione Java.
versione java
Risultato:
openjdk versione "1.8.0_201"OpenJDK Runtime Environment (build 1.8.0_201-b09)OpenJDK 64-Bit Server VM (build 25.201-b09, modalità mista)
Installa Apache Hadoop su RHEL 8
Crea utente Hadoop
Si consiglia di eseguire Apache Hadoop da un utente normale. Quindi, qui creeremo un utente chiamato hadoop e imposteremo una password per l'utente.
useradd -m -d /home/hadoop -s /bin/bash hadooppasswd hadoop
Ora, configura ssh senza password sul sistema locale seguendo i passaggi seguenti.
# su - hadoop$ ssh-keygen$ cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys$ chmod 600 ~/.ssh/authorized_keys
Verifica la comunicazione senza password con il tuo sistema locale.
$ ssh 127.0.0.1
Risultato:
Se ti connetti tramite ssh per la prima volta, dovrai digitare yes per aggiungere chiavi RSA a host conosciuti.
[hadoop@rhel8 ~]$ ssh 127.0.0.1Impossibile stabilire l'autenticità dell'host '127.0.0.1 (127.0.0.1)'.L'impronta digitale della chiave ECDSA è SHA256:85jUAgtJg8RLOqs8T2egxF7U7IWIiYF+CRspO8yatAk.Sei sicuro di volerlo continuare a connetterti (sì/no)? Sì Avviso:aggiunto in modo permanente '127.0.0.1' (ECDSA) all'elenco degli host conosciuti. Attiva la console web con:systemctl enable --now cockpit.socketUltimo accesso:mercoledì 8 maggio 12:15:04 2019 da 127.0.0.1[hadoop @rhel8 ~]$
Scarica Hadoop
Visita la pagina di Apache Hadoop per scaricare l'ultima versione di Apache Hadoop (scegli sempre la versione pronta per la produzione controllando la documentazione), oppure puoi utilizzare il seguente comando nel terminale per scaricare Hadoop v3.1.2.
$ wget https://www-us.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz$ tar -zxvf hadoop-3.1.2.tar. gz $ mv hadoop-3.1.2 hadoop
Tipi di cluster Hadoop
Esistono tre tipi di cluster Hadoop:
- Modalità locale (autonoma) – Funziona come un unico processo java.
- Modalità pseudo-distribuita – Ogni demone Hadoop viene eseguito come un processo separato.
- Modalità completamente distribuita – un cluster multinodo. Da pochi nodi a un cluster estremamente grande.
Imposta variabili ambientali
Qui configureremo Hadoop in modalità Pseudo-Distribuita. Per prima cosa, imposteremo le variabili ambientali nel file ~/.bashrc.
Modifica le voci delle variabili JAVA_HOME e HADOOP_HOME nel file a seconda del tuo ambiente.export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/ export HADOOP_HOME=/home/hadoop/hadoop Export hadoop_install =$ hadoop_homeexport hadoop_mapred_home =$ hadoop_homeexport hadoop_common_home =$ hadoop_homeexport hadoop_hdfs_home =$ hadoop_homeexportApplica le variabili ambientali alla tua sessione terminale corrente.
$ sorgente ~/.bashrcConfigura Hadoop
Modifica il file ambientale Hadoop e aggiorna la variabile come mostrato di seguito.
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.shAggiorna la variabile JAVA_HOME secondo il tuo ambiente.
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/Ora modificheremo i file di configurazione di Hadoop a seconda della modalità cluster che abbiamo impostato (Pseudo-Distribuito).
$ cd $HADOOP_HOME/etc/hadoopModifica core-site.xml e aggiorna il file con il nome host HDFS.
fs.defaultFS hdfs://rhel8.itzgeek.local :9000 Crea le directory namenode e datanode nella directory home /home/hadoop dell'utente hadoop.
$ mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}Modifica hdfs-site.xml e aggiorna il file con le informazioni sulla directory NameNode e DataNode.
dfs.replication 1 dfs.name.dir file :///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode Modifica mapred-site.xml.
mapreduce.framework.name filato Modifica yarn-site.xml.
yarn.nodemanager.aux-services mapreduce_shuffle Formatta il NameNode usando il comando seguente.
$ hdfs namenode -formatRisultato:
. . .. . .2019-05-13 19:33:14,720 INFO namenode.FSImage:allocato nuovo BlockPoolId:BP-1601223288-192.168.1.10-15577561946432019-05-13 19:33:15,100 INFO common.Storage:Directory di archiviazione /home/hadoop/ hadoopdata/hdfs/namenode è stato formattato correttamente.2019-05-13 19:33:15,436 INFO namenode.FSImageFormatProtobuf:salvataggio del file immagine /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_00000000000000000000 senza compressione2019-05- 13 19:33:16,804 INFO namenode.FSImageFormatProtobuf:File immagine /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_000000000000000000000 di dimensione 393 byte salvati in 1 secondo .2019-05-13 19:33:17,106 INFO namenode .NNStorageRetentionManager:Manterrà 1 immagini con txid>=02019-05-13 19:33:17,150 INFO namenode.NameNode:SHUTDOWN_MSG:/******************** ****************************************SHUTDOWN_MSG:chiusura di NameNode su rhel8.itzgeek. locale/192.168.1.10************************************************** ***************/
Firewall
Esegui i comandi seguenti per consentire le connessioni Apache Hadoop attraverso il firewall. Esegui questi comandi come utente root.
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcpfirewall-cmd --reload
Avvia Hadoop &Yarn
Avvia entrambi i demoni NameNode e DataNode utilizzando gli script forniti da Hadoop.
$ start-dfs.sh
Risultato:
Avvio dei namenode su [rhel8.itzgeek.local]rhel8.itzgeek.local:Avviso:aggiunto in modo permanente 'rhel8.itzgeek.local,fe80::4480:83a5:c52:ea80%enp0s3' (ECDSA) all'elenco di host conosciuti. Avvio di datanodeslocalhost:avviso:aggiunto in modo permanente 'localhost' (ECDSA) all'elenco degli host noti. Avvio di namenodes secondari [rhel8.itzgeek.local]2019-05-13 19:39:00,698 WARN util.NativeCodeLoader:Impossibile carica la libreria nativa-hadoop per la tua piattaforma... usando classi integrate-java ove applicabile
Apri un browser e vai all'indirizzo sottostante per accedere a Namenode.
http://ip.ad.dre.ss:9870/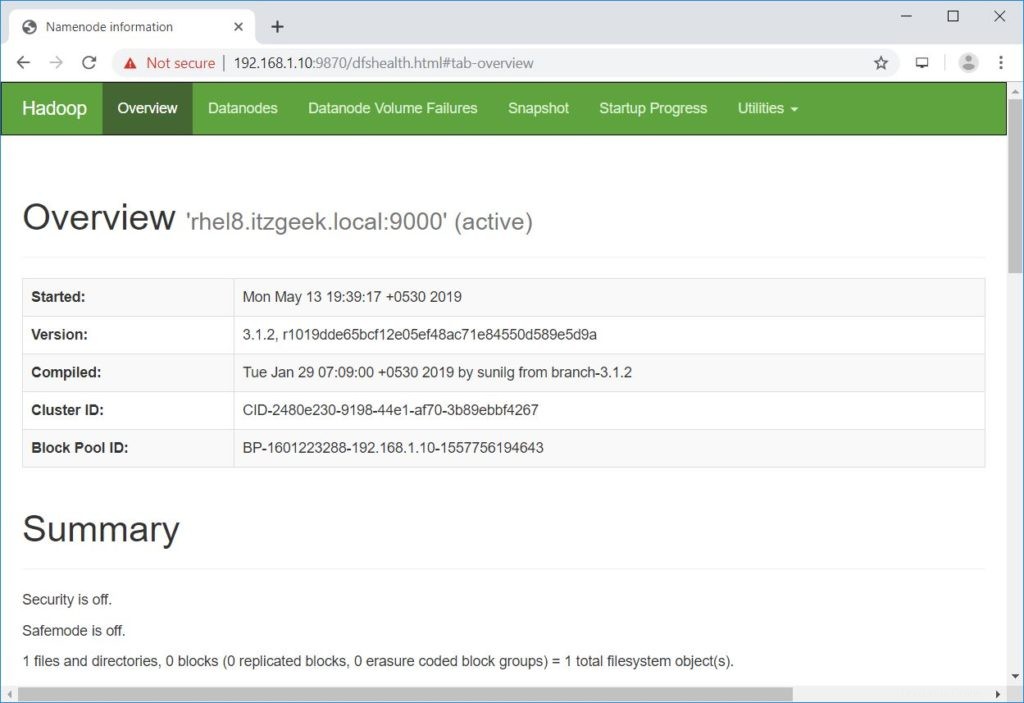
Avvia ResourceManager e NodeManager.
$ start-yarn.sh
Risultato:
Avvio di ResourcemanagerAvvio di nodemanager
Apri un browser e vai all'indirizzo sottostante per accedere a ResourceManager.
http://ip.ad.dre.ss:8088/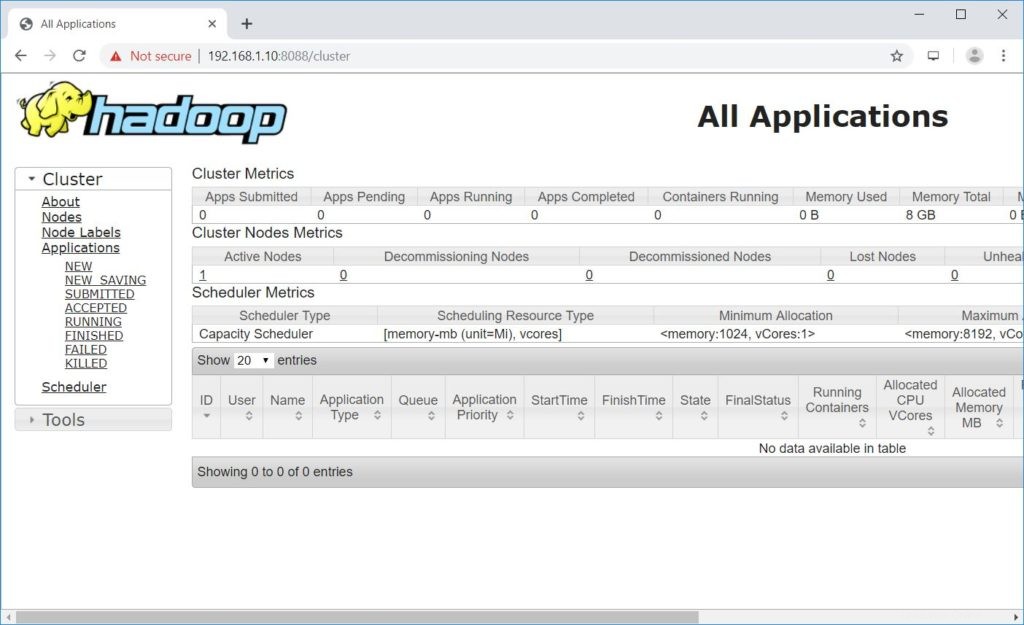
Testa Apache Hadoop
Ora testeremo Apache Hadoop caricandoci un file di esempio. Prima di caricare un file su HDFS, crea una directory in HDFS.
$ hdfs dfs -mkdir /raj
Verifica che la directory creata esista in HDFS.
hdfs dfs -ls /
Risultato:
Trovato 1 articolidrwxr-xr-x - hadoop supergroup 0 2019-05-08 13:20 /raj
Carica un file nella directory HDFS raj con il seguente comando.
$ hdfs dfs -put ~/.bashrc /raj
I file caricati possono essere visualizzati eseguendo il comando seguente.
$ hdfs dfs -ls /raj
O
Vai a NomeNode>> Utilità >> Sfoglia il file system in NameNode.
http://ip.ad.dre.ss:9870/explorer.html#/raj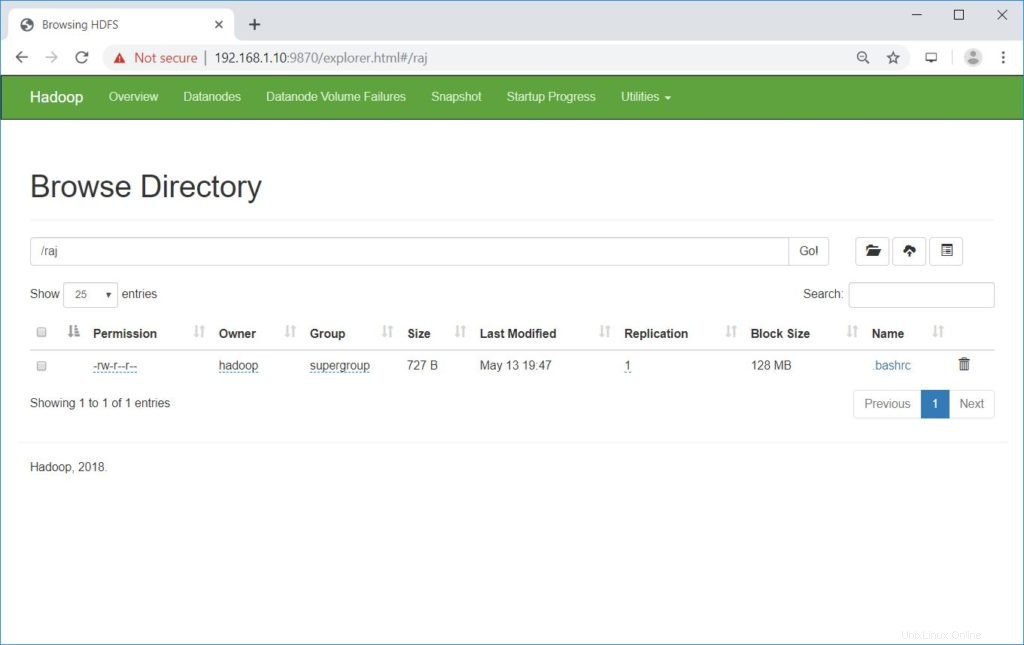
Puoi copiare i file da HDFS ai tuoi file system locali usando il comando seguente.
$ hdfs dfs -get /raj /tmp/
Se necessario, puoi eliminare i file e le directory in HDFS utilizzando i seguenti comandi.
$ hdfs dfs -rm -f /raj/.bashrc$ hdfs dfs -rmdir /raj
Conclusione
Spero che questo post ti abbia aiutato a installare e configurare un cluster Apache Hadoop a nodo singolo su RHEL 8. Puoi leggere la documentazione ufficiale di Hadoop per ulteriori informazioni. Condividi il tuo feedback nella sezione commenti.