Hadoop è un framework open source ampiamente utilizzato per gestire Bigdata . La maggior parte dei Bigdata/Data Analytics i progetti vengono realizzati sulla base dell'ecosistema Hadoop . È costituito da due livelli, uno è per Memorizzazione dei dati e un altro è per Elaborazione dei dati .
Archiviazione sarà gestito dal proprio filesystem chiamato HDFS (Filesystem distribuito Hadoop ) e Elaborazione sarà curato da YARN (Ancora un altro negoziatore di risorse ). Mappare è il motore di elaborazione predefinito dell'ecosistema Hadoop .
Questo articolo descrive il processo per installare lo Pseudonode installazione di Hadoop , dove tutti i daemon (JVM ) eseguirà Nodo singolo Cluster su CentOS 7 .
Questo è principalmente per i principianti per imparare Hadoop. In tempo reale, Hadoop verrà installato come un cluster multinodo in cui i dati verranno distribuiti tra i server come blocchi e il lavoro verrà eseguito in modo parallelo.
Prerequisiti
- Un'installazione minima del server CentOS 7.
- Rilascio Java v1.8.
- Rilascio stabile di Hadoop 2.x.
In questa pagina
- Come installare Java su CentOS 7
- Configura l'accesso senza password su CentOS 7
- Come installare il nodo singolo Hadoop in CentOS 7
- Come configurare Hadoop in CentOS 7
- Formattare il file system HDFS tramite il NameNode
Installazione di Java su CentOS 7
1. Hadoop è un Eco-Sistema composto da Java . Abbiamo bisogno di Java installato nel nostro sistema obbligatoriamente per installare Hadoop .
# yum install java-1.8.0-openjdk
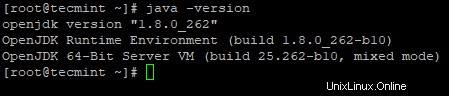
2. Successivamente, verifica la versione installata di Java nel sistema.
# java -version
Configura l'accesso senza password su CentOS 7
Dobbiamo avere ssh configurato nella nostra macchina, Hadoop gestirà i nodi con l'uso di SSH . Il nodo principale utilizza SSH connessione per connettere i suoi nodi slave ed eseguire operazioni come avvio e arresto.
È necessario configurare ssh senza password in modo che il master possa comunicare con gli slave utilizzando ssh senza password. In caso contrario, per ogni stabilimento di connessione, è necessario inserire la password.
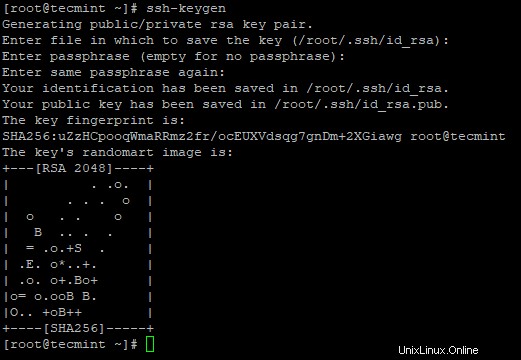
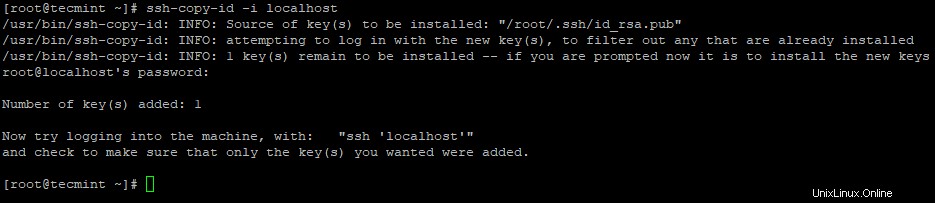
3. Configura un accesso SSH senza password utilizzando i seguenti comandi sul server.
# ssh-keygen # ssh-copy-id -i localhost
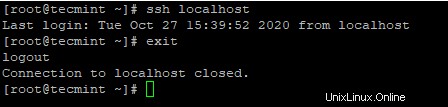
4. Dopo aver configurato l'accesso SSH senza password, prova ad accedere di nuovo, verrai connesso senza password.
# ssh localhost
Installazione di Hadoop in CentOS 7
5. Vai al sito Web di Apache Hadoop e scarica la versione stabile di Hadoop utilizzando il seguente comando wget.
# wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz # tar xvpzf hadoop-2.10.1.tar.gz
6. Quindi, aggiungi Hadoop variabili di ambiente in ~/.bashrc file come mostrato.
HADOOP_PREFIX=/root/hadoop-2.10.1 PATH=$PATH:$HADOOP_PREFIX/bin export PATH JAVA_HOME HADOOP_PREFIX
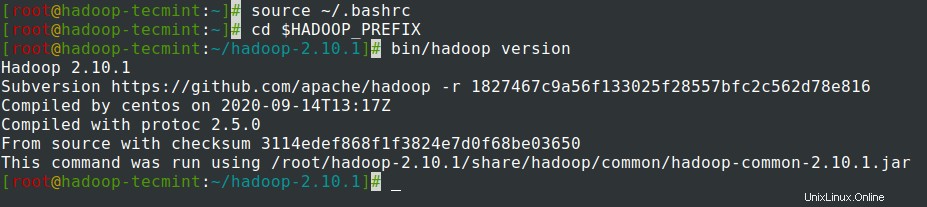
7. Dopo aver aggiunto le variabili di ambiente a ~/.bashrc il file, origina il file e verifica Hadoop eseguendo i seguenti comandi.
# source ~/.bashrc # cd $HADOOP_PREFIX # bin/hadoop version
Configurazione di Hadoop in CentOS 7
Abbiamo bisogno di configurare i file di configurazione di Hadoop di seguito per adattarli alla tua macchina. In Hadoop ogni servizio ha il proprio numero di porta e la propria directory per memorizzare i dati.
- File di configurazione Hadoop:core-site.xml, hdfs-site.xml, mapred-site.xml e yarn-site.xml
8. Per prima cosa, dobbiamo aggiornare JAVA_HOME e Hadoop percorso in hadoop-env.sh file come mostrato.
# cd $HADOOP_PREFIX/etc/hadoop # vi hadoop-env.sh
Immettere la riga seguente all'inizio del file.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0/jre export HADOOP_PREFIX=/root/hadoop-2.10.1
9. Quindi, modifica il core-site.xml file.
# cd $HADOOP_PREFIX/etc/hadoop # vi core-site.xml
Incolla seguendo tra <configuration> tag come mostrato.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
10. Crea le directory seguenti sotto tecmint directory home dell'utente, che verrà utilizzata per NN e DN archiviazione.
# mkdir -p /home/tecmint/hdata/ # mkdir -p /home/tecmint/hdata/data # mkdir -p /home/tecmint/hdata/name
10. Quindi, modifica hdfs-site.xml file.
# cd $HADOOP_PREFIX/etc/hadoop # vi hdfs-site.xml
Incolla seguendo tra <configuration> tag come mostrato.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/tecmint/hdata/name</value>
</property>
<property>
<name>dfs .datanode.data.dir</name>
<value>home/tecmint/hdata/data</value>
</property>
</configuration>
11. Di nuovo, modifica il mapred-site.xml file.
# cd $HADOOP_PREFIX/etc/hadoop # cp mapred-site.xml.template mapred-site.xml # vi mapred-site.xml
Incolla seguendo tra <configuration> tag come mostrato.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
12. Infine, modifica il yarn-site.xml file.
# cd $HADOOP_PREFIX/etc/hadoop # vi yarn-site.xml
Incolla seguendo tra <configuration> tag come mostrato.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Formattazione del file system HDFS tramite il NameNode
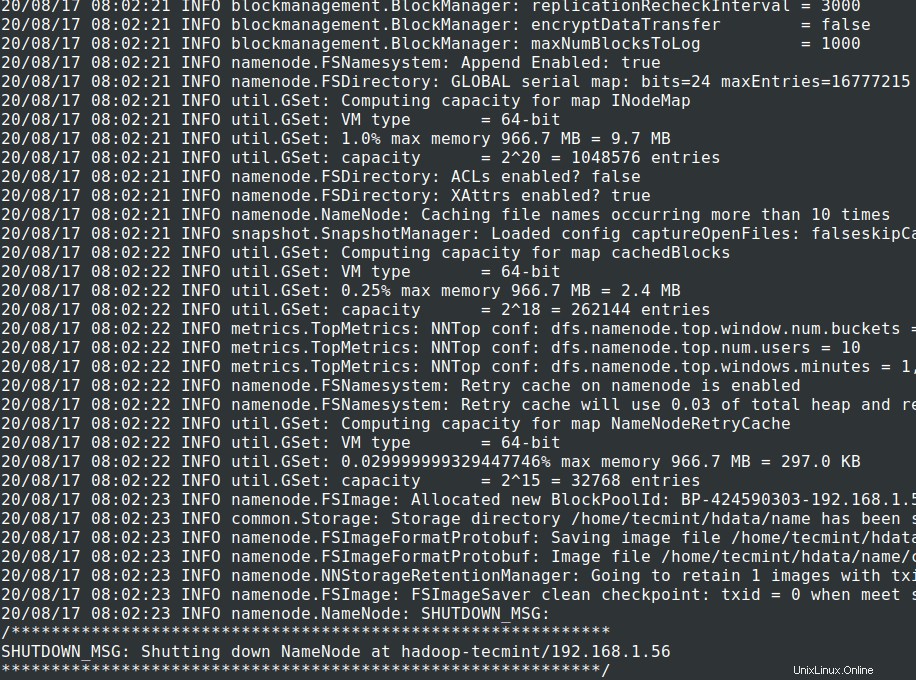
13. Prima di avviare il cluster , dobbiamo formattare Hadoop NN nel nostro sistema locale in cui è stato installato. Di solito, questa operazione viene eseguita nella fase iniziale prima di avviare il cluster per la prima volta.
Formattazione di NN causerà la perdita di dati nel metastore NN, quindi dobbiamo essere più cauti, non dovremmo formattare NN mentre il cluster è in esecuzione a meno che non sia richiesto intenzionalmente.
# cd $HADOOP_PREFIX # bin/hadoop namenode -format
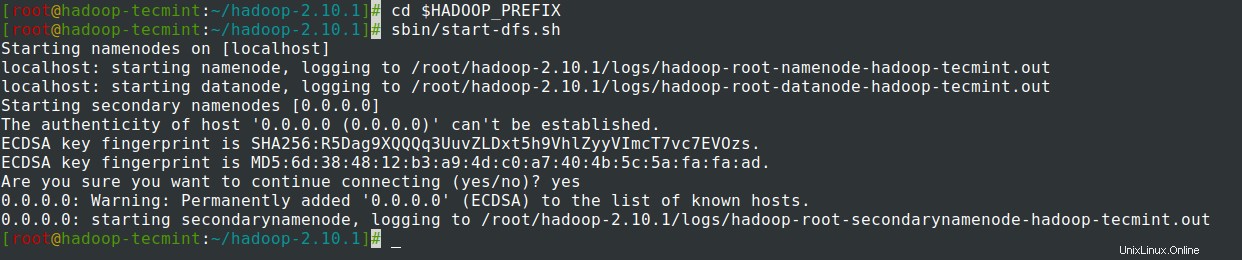
14. Avvia NomeNode demone e DataNode demone:(porta 50070 ).
# cd $HADOOP_PREFIX # sbin/start-dfs.sh
15. Avvia ResourceManager demone e NodeManager demone:(porta 8088 ).
# sbin/start-yarn.sh

16. Per interrompere tutti i servizi.
# sbin/stop-dfs.sh # sbin/stop-dfs.sh
Riepilogo
Riepilogo
In questo articolo, abbiamo esaminato passo passo la procedura per configurare Hadoop Pseudonode (Nodo singolo ) Grappolo . Se hai una conoscenza di base di Linux e segui questi passaggi, il cluster sarà attivo in 40 minuti.
Questo può essere molto utile per i principianti per iniziare ad imparare e praticare Hadoop o questa versione vaniglia di Hadoop può essere utilizzato per scopi di sviluppo. Se vogliamo avere un cluster in tempo reale, abbiamo bisogno di almeno 3 server fisici in mano o dobbiamo effettuare il provisioning del Cloud per avere più server.