Apache Hadoop è un framework open source utilizzato per l'archiviazione distribuita e l'elaborazione distribuita di big data su cluster di computer che funzionano su hardware di base. Hadoop archivia i dati in Hadoop Distributed File System (HDFS) e l'elaborazione di questi dati viene eseguita utilizzando MapReduce. YARN fornisce l'API per la richiesta e l'allocazione delle risorse nel cluster Hadoop.
Il framework Apache Hadoop è composto dai seguenti moduli:
- Hadoop comune
- File system distribuito Hadoop (HDFS)
- FILO
- Riduci mappa
Questo articolo spiega come installare Hadoop versione 2 su RHEL 8 o CentOS 8. Installeremo HDFS (Namenode e Datanode), YARN, MapReduce sul cluster a nodo singolo in Pseudo Distributed Mode che è una simulazione distribuita su un singolo computer. Ogni demone Hadoop come hdfs, yarn, mapreduce ecc. verrà eseguito come un processo java separato/individuale.
In questo tutorial imparerai:
- Come aggiungere utenti per Hadoop Environment
- Come installare e configurare Oracle JDK
- Come configurare SSH senza password
- Come installare Hadoop e configurare i file xml correlati necessari
- Come avviare il cluster Hadoop
- Come accedere all'interfaccia utente Web NameNode e ResourceManager
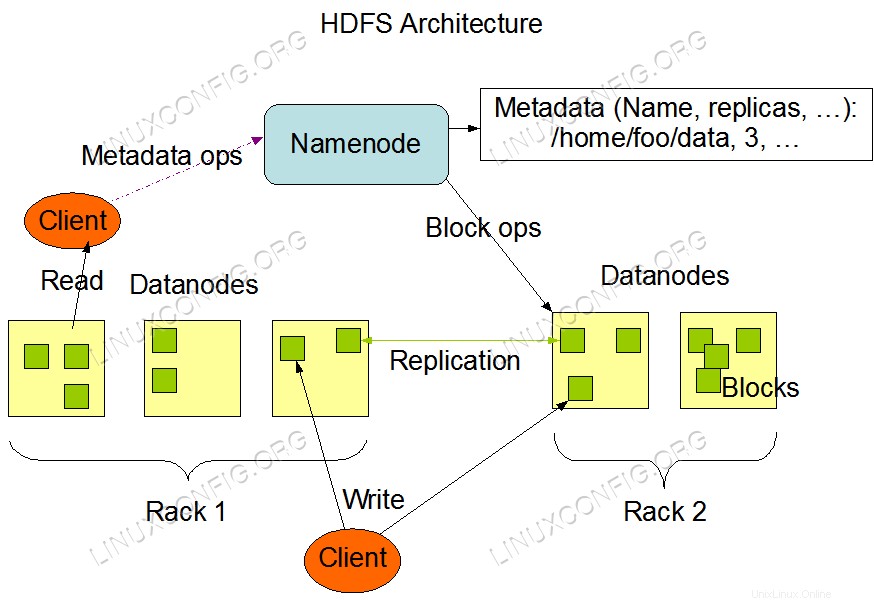 Architettura HDFS.
Architettura HDFS. Requisiti e convenzioni software utilizzati
| Categoria | Requisiti, convenzioni o versione del software utilizzata |
|---|---|
| Sistema | RHEL 8 / CentOS 8 |
| Software | Hadoop 2.8.5, Oracle JDK 1.8 |
| Altro | Accesso privilegiato al tuo sistema Linux come root o tramite sudo comando. |
| Convenzioni | # – richiede che i comandi linux dati vengano eseguiti con i privilegi di root direttamente come utente root o usando sudo comando$ – richiede che i comandi linux dati vengano eseguiti come un normale utente non privilegiato |
Aggiungi utenti per l'ambiente Hadoop
Crea il nuovo utente e gruppo usando il comando:
# useradd hadoop # passwd hadoop
[root@hadoop ~]# useradd hadoop [root@hadoop ~]# passwd hadoop Changing password for user hadoop. New password: Retype new password: passwd: all authentication tokens updated successfully. [root@hadoop ~]# cat /etc/passwd | grep hadoop hadoop:x:1000:1000::/home/hadoop:/bin/bash
Installa e configura Oracle JDK
Scarica e installa il pacchetto ufficiale jdk-8u202-linux-x64.rpm per installare Oracle JDK.
[root@hadoop ~]# rpm -ivh jdk-8u202-linux-x64.rpm
warning: jdk-8u202-linux-x64.rpm: Header V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:jdk1.8-2000:1.8.0_202-fcs ################################# [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
Dopo l'installazione per verificare che java sia stata configurata correttamente, eseguire i seguenti comandi:
[root@hadoop ~]# java -version java version "1.8.0_202" Java(TM) SE Runtime Environment (build 1.8.0_202-b08) Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode) [root@hadoop ~]# update-alternatives --config java There is 1 program that provides 'java'. Selection Command ----------------------------------------------- *+ 1 /usr/java/jdk1.8.0_202-amd64/jre/bin/java
Configura SSH senza password
Installa Open SSH Server e Open SSH Client o se è già installato, verranno elencati i pacchetti seguenti.
[root@hadoop ~]# rpm -qa | grep openssh* openssh-server-7.8p1-3.el8.x86_64 openssl-libs-1.1.1-6.el8.x86_64 openssl-1.1.1-6.el8.x86_64 openssh-clients-7.8p1-3.el8.x86_64 openssh-7.8p1-3.el8.x86_64 openssl-pkcs11-0.4.8-2.el8.x86_64
Genera coppie di chiavi pubbliche e private con il comando seguente. Il terminale chiederà di inserire il nome del file. Premi ENTER e procedi. Dopodiché copia le chiavi pubbliche da id_rsa.pub a authorized_keys .
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 640 ~/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:H+LLPkaJJDD7B0f0Je/NFJRP5/FUeJswMmZpJFXoelg hadoop@hadoop.sandbox.com The key's randomart image is: +---[RSA 2048]----+ | .. ..++*o .o| | o .. +.O.+o.+| | + . . * +oo==| | . o o . E .oo| | . = .S.* o | | . o.o= o | | . .. o | | .o. | | o+. | +----[SHA256]-----+ [hadoop@hadoop ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys [hadoop@hadoop ~]$ chmod 640 ~/.ssh/authorized_keys
Verifica la configurazione ssh senza password con il comando :
$ ssh
[hadoop@hadoop ~]$ ssh hadoop.sandbox.com Web console: https://hadoop.sandbox.com:9090/ or https://192.168.1.108:9090/ Last login: Sat Apr 13 12:09:55 2019 [hadoop@hadoop ~]$
Installa Hadoop e configura i file xml correlati
Scarica ed estrai Hadoop 2.8.5 dal sito Web ufficiale di Apache.
# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz # tar -xzvf hadoop-2.8.5.tar.gz
[root@rhel8-sandbox ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz --2019-04-13 11:14:03-- https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz Resolving archive.apache.org (archive.apache.org)... 163.172.17.199 Connecting to archive.apache.org (archive.apache.org)|163.172.17.199|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 246543928 (235M) [application/x-gzip] Saving to: ‘hadoop-2.8.5.tar.gz’ hadoop-2.8.5.tar.gz 100%[=====================================================================================>] 235.12M 1.47MB/s in 2m 53s 2019-04-13 11:16:57 (1.36 MB/s) - ‘hadoop-2.8.5.tar.gz’ saved [246543928/246543928]
Impostazione delle variabili d'ambiente
Modifica il bashrc per l'utente Hadoop impostando le seguenti variabili di ambiente Hadoop :
export HADOOP_HOME=/home/hadoop/hadoop-2.8.5
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Fonte il .bashrc nella sessione di accesso corrente.
$ source ~/.bashrc
Modifica il hadoop-env.sh file che si trova in /etc/hadoop all'interno della directory di installazione di Hadoop e apportare le seguenti modifiche e verificare se si desidera modificare altre configurazioni.
export JAVA_HOME=${JAVA_HOME:-"/usr/java/jdk1.8.0_202-amd64"}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/home/hadoop/hadoop-2.8.5/etc/hadoop"}
Modifiche alla configurazione nel file core-site.xml
Modifica il core-site.xml con vim oppure puoi usare uno qualsiasi degli editor. Il file si trova in /etc/hadoop dentro hadoop home directory e aggiungere le seguenti voci.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.sandbox.com:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadooptmpdata</value>
</property>
</configuration>
Inoltre, crea la directory in hadoop cartella Inizio.
$ mkdir hadooptmpdata
Modifiche alla configurazione nel file hdfs-site.xml
Modifica il hdfs-site.xml che è presente nella stessa posizione, ad esempio /etc/hadoop dentro hadoop directory di installazione e creare il Namenode/Datanode directory in hadoop directory home dell'utente.
$ mkdir -p hdfs/namenode $ mkdir -p hdfs/datanode
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Modifiche alla configurazione nel file mapred-site.xml
Copia il mapred-site.xml da mapred-site.xml.template usando cp comando e quindi modificare il mapred-site.xml inserito in /etc/hadoop sotto hadoop directory di instillazione con le seguenti modifiche.
$ cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Modifiche alla configurazione nel file yarn-site.xml
Modifica yarn-site.xml con le seguenti voci.
<configuration>
<property>
<name>mapreduceyarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Avvio del cluster Hadoop
Formatta il namenode prima di usarlo per la prima volta. Come utente hadoop, esegui il comando seguente per formattare il Namenode.
$ hdfs namenode -format
[hadoop@hadoop ~]$ hdfs namenode -format 19/04/13 11:54:10 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: user = hadoop STARTUP_MSG: host = hadoop.sandbox.com/192.168.1.108 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.8.5 19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 19/04/13 11:54:18 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 19/04/13 11:54:18 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 19/04/13 11:54:18 INFO util.GSet: Computing capacity for map NameNodeRetryCache 19/04/13 11:54:18 INFO util.GSet: VM type = 64-bit 19/04/13 11:54:18 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 19/04/13 11:54:18 INFO util.GSet: capacity = 2^15 = 32768 entries 19/04/13 11:54:18 INFO namenode.FSImage: Allocated new BlockPoolId: BP-415167234-192.168.1.108-1555142058167 19/04/13 11:54:18 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 19/04/13 11:54:18 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 19/04/13 11:54:18 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds. 19/04/13 11:54:18 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 19/04/13 11:54:18 INFO util.ExitUtil: Exiting with status 0 19/04/13 11:54:18 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop.sandbox.com/192.168.1.108 ************************************************************/
Una volta che il Namenode è stato formattato, avvia l'HDFS utilizzando start-dfs.sh copione.
$ start-dfs.sh
[hadoop@hadoop ~]$ start-dfs.sh Starting namenodes on [hadoop.sandbox.com] hadoop.sandbox.com: starting namenode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-namenode-hadoop.sandbox.com.out hadoop.sandbox.com: starting datanode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-datanode-hadoop.sandbox.com.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. ECDSA key fingerprint is SHA256:e+NfCeK/kvnignWDHgFvIkHjBWwghIIjJkfjygR7NkI. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. hadoop@0.0.0.0's password: 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-secondarynamenode-hadoop.sandbox.com.out
Per avviare i servizi YARN è necessario eseguire lo script di avvio del filato ovvero start-yarn.sh
$ start-yarn.sh
[hadoop@hadoop ~]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-resourcemanager-hadoop.sandbox.com.out hadoop.sandbox.com: starting nodemanager, logging to /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-nodemanager-hadoop.sandbox.com.out
Per verificare che tutti i servizi/daemon Hadoop siano stati avviati correttamente puoi utilizzare il jps comando.
$ jps 2033 NameNode 2340 SecondaryNameNode 2566 ResourceManager 2983 Jps 2139 DataNode 2671 NodeManager
Ora possiamo controllare la versione attuale di Hadoop che puoi usare sotto il comando:
$ hadoop version
o
$ hdfs version
[hadoop@hadoop ~]$ hadoop version Hadoop 2.8.5 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8 Compiled by jdu on 2018-09-10T03:32Z Compiled with protoc 2.5.0 From source with checksum 9942ca5c745417c14e318835f420733 This command was run using /home/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar [hadoop@hadoop ~]$ hdfs version Hadoop 2.8.5 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8 Compiled by jdu on 2018-09-10T03:32Z Compiled with protoc 2.5.0 From source with checksum 9942ca5c745417c14e318835f420733 This command was run using /home/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar [hadoop@hadoop ~]$
Interfaccia a riga di comando HDFS
Per accedere a HDFS e creare alcune directory in cima a DFS puoi usare HDFS CLI.
$ hdfs dfs -mkdir /testdata $ hdfs dfs -mkdir /hadoopdata $ hdfs dfs -ls /
[hadoop@hadoop ~]$ hdfs dfs -ls / Found 2 items drwxr-xr-x - hadoop supergroup 0 2019-04-13 11:58 /hadoopdata drwxr-xr-x - hadoop supergroup 0 2019-04-13 11:59 /testdata
Accedi a Namenode e YARN dal browser
Puoi accedere sia all'interfaccia utente Web per NameNode che a YARN Resource Manager tramite qualsiasi browser come Google Chrome/Mozilla Firefox.
UI Web Namenode – http://<hadoop cluster hostname/IP address>:50070
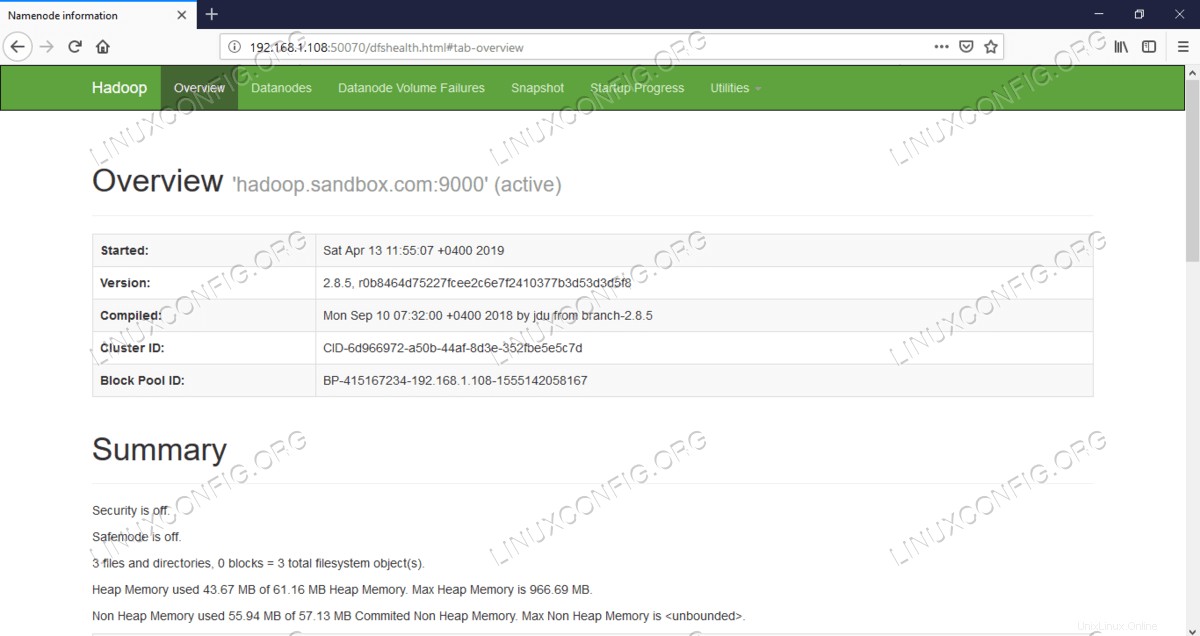 Interfaccia utente Web Namenode.
Interfaccia utente Web Namenode. 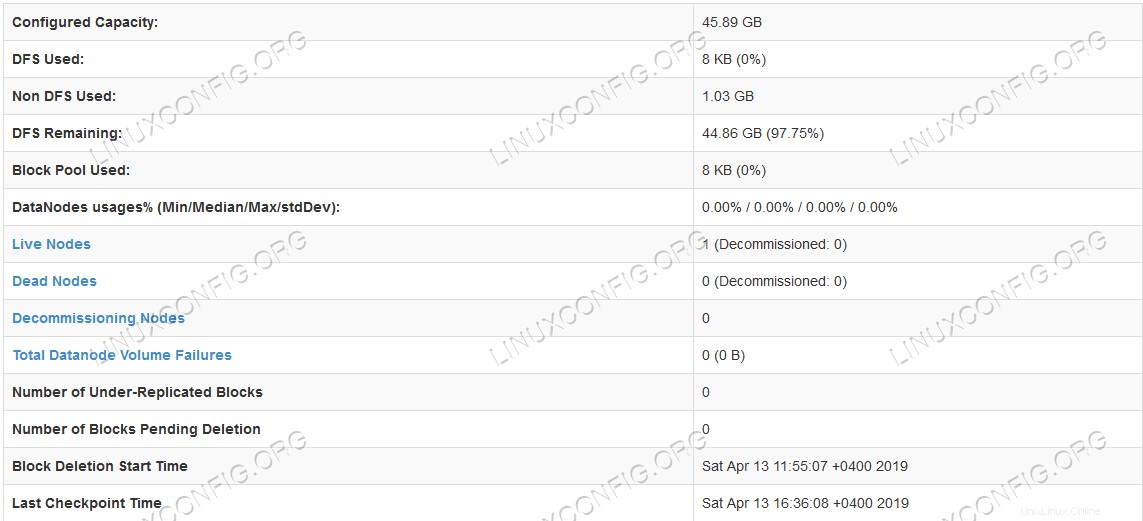 Informazioni dettagliate sull'HDFS.
Informazioni dettagliate sull'HDFS. 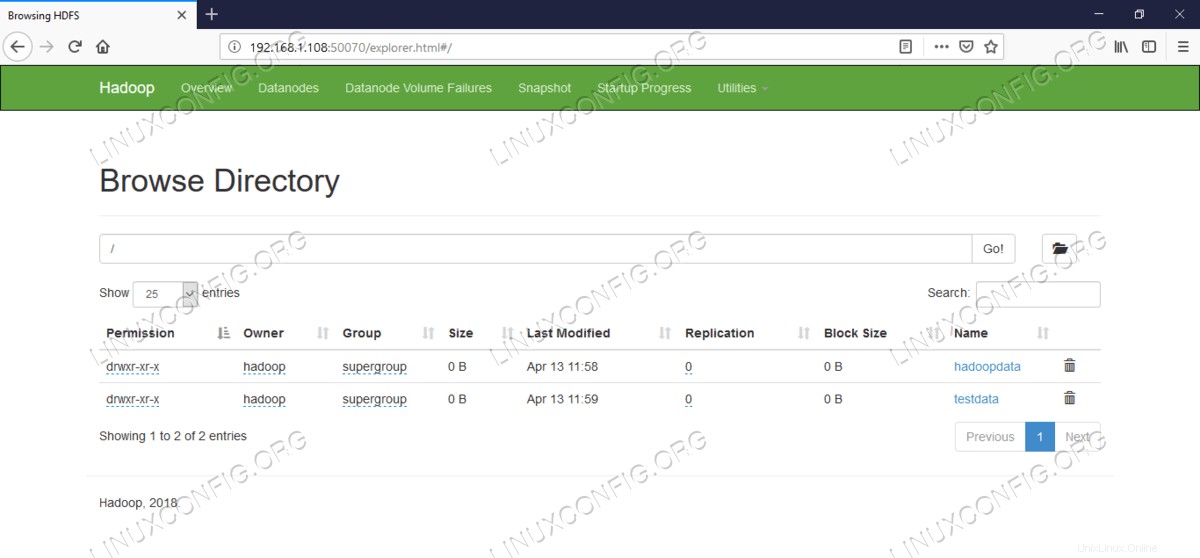 Navigazione nella directory HDFS.
Navigazione nella directory HDFS. L'interfaccia web di YARN Resource Manager (RM) visualizzerà tutti i lavori in esecuzione sul cluster Hadoop corrente.
Interfaccia utente Web di Resource Manager – http://<hadoop cluster hostname/IP address>:8088
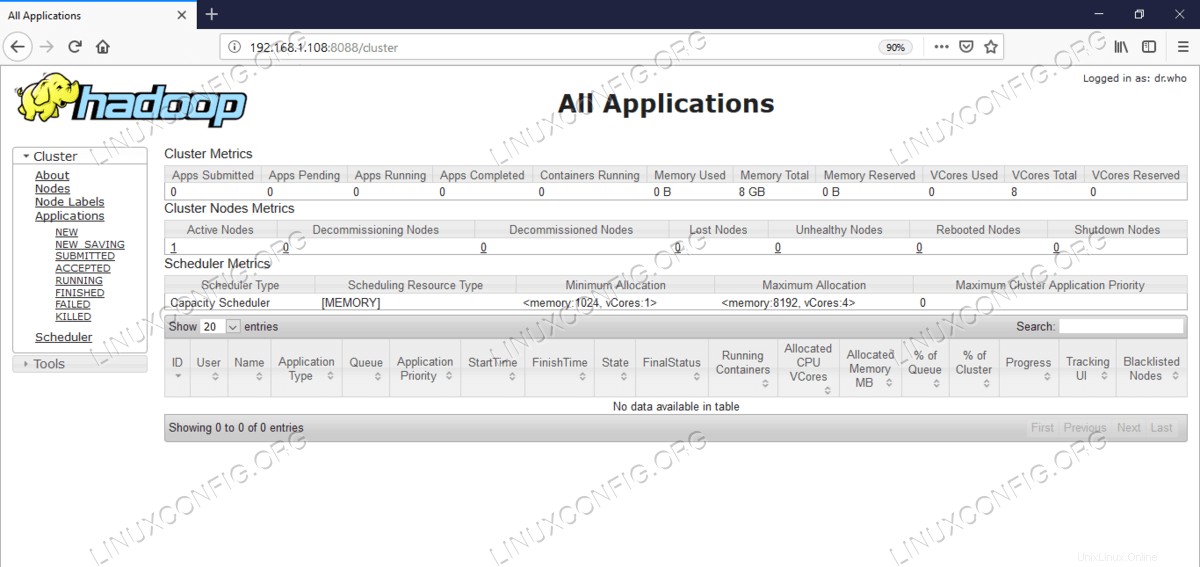 Interfaccia utente Web di Resource Manager (YARN).
Interfaccia utente Web di Resource Manager (YARN). Conclusione
Il mondo sta cambiando il modo in cui opera attualmente e i big data stanno giocando un ruolo importante in questa fase. Hadoop è un framework che ci semplifica la vita mentre lavoriamo su grandi insiemi di dati. Ci sono miglioramenti su tutti i fronti. Il futuro è eccitante.