Risposta aggiornata nell'anno 2020 :
Secondo la risposta di @Owen, ORC è cresciuto e maturato come il proprio progetto Apache. Un elenco completo di utenti ORC mostra quanto sia diffuso ora supportato in molte varietà di tecnologie Big Data.
Ringraziamo @Owen e il team del progetto ORC Apache, il sito del progetto ORC ha una documentazione aggiornata completamente mantenuta sull'utilizzo dello strumento autonomo Java o C++ sul file ORC memorizzato su un file system locale Linux. Che ha portato avanti la fiaccola per la pagina wiki originale di Hive+ORC Apache.
Risposta originale datata:May 30 '14 at 16:27
L'utilità di dump del file ORC viene fornita con hive (0.11 o superiore):
hive --orcfiledump <hdfs-location-of-orc-file>Collegamento sorgente
È anche in grado di vedere il contenuto di un file ORC dall'applicazione desktop in esecuzione su Linux.
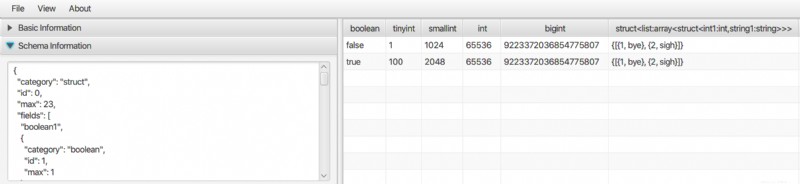
Esiste un'applicazione desktop per visualizzare Parquet e anche altri dati in formato binario come ORC e AVRO. È un'applicazione Java pura in modo che possa essere eseguita su Linux, Mac e anche Windows. Si prega di controllare Bigdata File Viewer per i dettagli.
Supporta tipi di dati complessi come array, map, struct, ecc.
Ora c'è anche un eseguibile nativo per Linux e MacOS che stampa il contenuto del file orc in JSON. Vedere il progetto ORC (http://orc.apache.org/) e creare gli strumenti C++.
% orc-contents examples/TestOrcFile.test1.orc
C'è anche uno strumento di metadati nativo:
% orc-metadata ../examples/TestOrcFile.test1.orc
Il progetto ORC ha anche un uber jar autonomo che può fare lo stesso da Java.
% java -jar orc-tools-1.2.3-uber.jar data myfile.orc