In questa guida, descriveremo quale codifica dei caratteri e tratteremo alcuni esempi di conversione di file da una codifica dei caratteri a un'altra utilizzando uno strumento da riga di comando. Infine, vedremo come convertire diversi file da qualsiasi set di caratteri (charset ) su UTF-8 codifica in Linux.
Come probabilmente avrai già in mente, un computer non comprende né memorizza lettere, numeri o qualsiasi altra cosa che noi umani possiamo percepire tranne i bit. Un bit ha solo due valori possibili, ovvero uno 0 o 1 , true o false , yes o no . Ogni altra cosa come lettere, numeri, immagini deve essere rappresentata in bit per essere elaborata da un computer.
In parole povere, codifica dei caratteri è un modo per informare un computer su come interpretare zeri e uno grezzi in caratteri reali, in cui un carattere è rappresentato da un insieme di numeri. Quando scriviamo del testo in un file, le parole e le frasi che formiamo sono preparate da caratteri diversi e i caratteri sono organizzati in un charset .
Esistono vari schemi di codifica come ASCII , ANSI , Unicode tra gli altri. Di seguito è riportato un esempio di ASCII codifica.
Character bits A 01000001 B 01000010
In Linux, iconv lo strumento della riga di comando viene utilizzato per convertire il testo da una forma di codifica a un'altra.
Puoi controllare la codifica di un file utilizzando il file comando, utilizzando il -i o --mime flag che abilita la stampa della stringa di tipo mime come negli esempi seguenti:
$ file -i Car.java $ file -i CarDriver.java


La sintassi per l'utilizzo di iconv è il seguente:
$ iconv option $ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
Dove -f o --from-code significa codifica di input e -t o --to-encoding specifica la codifica dell'output.
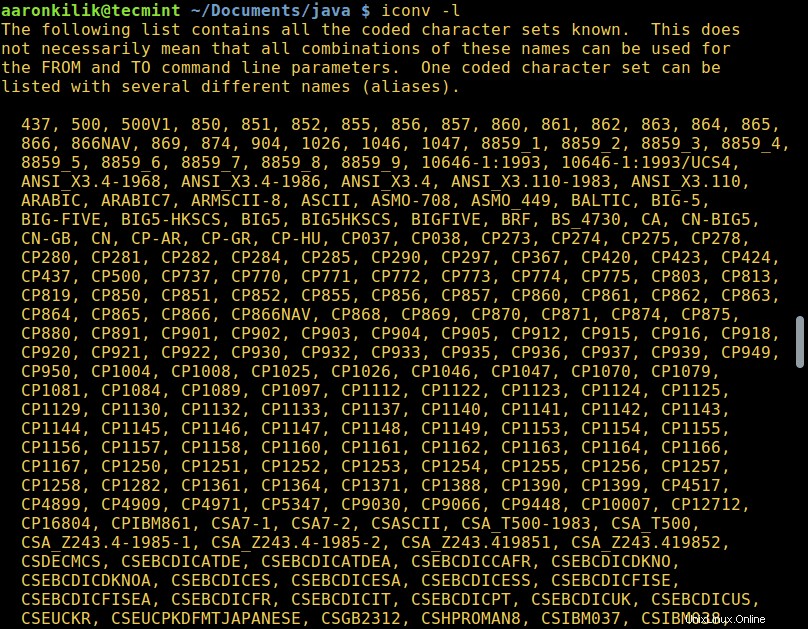
Per elencare tutti i set di caratteri codificati conosciuti, esegui il comando seguente:
$ iconv -l
Convertire file da UTF-8 a codifica ASCII
Successivamente, impareremo come convertire da uno schema di codifica a un altro. Il comando seguente converte da ISO-8859-1 a UTF-8 codifica.
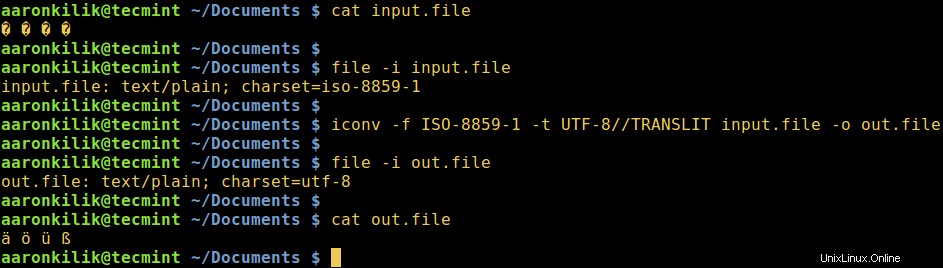
Considera un file chiamato input.file che contiene i caratteri:
� � � �
Iniziamo controllando la codifica dei caratteri nel file e poi visualizziamo il contenuto del file. Da vicino, possiamo convertire tutti i caratteri in ASCII codifica.
Dopo aver eseguito iconv comando, controlliamo quindi il contenuto del file di output e la nuova codifica dei caratteri come di seguito.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
Nota :Nel caso in cui la stringa //IGNORE viene aggiunto alla codifica, i caratteri che non possono essere convertiti e viene visualizzato un errore dopo la conversione.
Di nuovo, supponendo la stringa //TRANSLIT viene aggiunto alla codifica come nell'esempio sopra (ASCII//TRANSLIT ), i caratteri da convertire vengono traslitterati secondo necessità e se possibile. Il che implica che nel caso in cui un personaggio non possa essere rappresentato nel set di caratteri di destinazione, può essere approssimato attraverso uno o più personaggi dall'aspetto simile.
Di conseguenza, qualsiasi carattere che non può essere traslitterato e non è nel set di caratteri di destinazione viene sostituito da un punto interrogativo (?) nell'output.
Converti più file in codifica UTF-8
Tornando al nostro argomento principale, per convertire più o tutti i file in una directory nella codifica UTF-8, puoi scrivere un piccolo script di shell chiamato encoding.sh come segue:
#!/bin/bash
#enter input encoding here
FROM_ENCODING="value_here"
#output encoding(UTF-8)
TO_ENCODING="UTF-8"
#convert
CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
#loop to convert multiple files
for file in *.txt; do
$CONVERT "$file" -o "${file%.txt}.utf8.converted"
done
exit 0
Salva il file, quindi rendi eseguibile lo script. Eseguilo dalla directory in cui i tuoi file (*.txt ) si trovano.
$ chmod +x encoding.sh $ ./encoding.sh
Importante :Puoi anche usare questo script per la conversione generale di più file da una data codifica a un'altra, semplicemente giocare con i valori di FROM_ENCODING e TO_ENCODING variabile, senza dimenticare il nome del file di output "${file%.txt}.utf8.converted" .
Per ulteriori informazioni, consulta l'icona pagina man.
$ man iconv
Per riassumere questa guida, comprendere la codifica e come convertire da uno schema di codifica dei caratteri a un altro è una conoscenza necessaria per ogni utente di computer, tanto più per i programmatori quando si tratta di gestire il testo.
Infine, puoi metterti in contatto con noi utilizzando la sezione commenti qui sotto per qualsiasi domanda o feedback.