La necessità del confronto dei file su un sistema operativo Linux è spesso trascurata, ma ha un ruolo importante da svolgere soprattutto per gli amministratori di sistema Linux. Essere in grado di confrontare in modo flessibile due file su un terminale Linux fa luce su quanto un insieme di file sia percepito come unico o diverso.
[ Potrebbe piacerti anche:Come unire due file di testo in Linux ]
Ad esempio, possono esistere due file con le stesse proprietà e dimensioni. Invece di presumere che siano identici, un programma di confronto di file Linux chiarirà l'aria su un problema del genere. Potresti essere sorpreso di scoprire che il fattore di differenziazione dei due file è una dicitura o una spaziatura che corrisponde a un file e non riesce a farlo con l'altro.
Diversi programmi Linux basati su terminale possono aiutarci a raggiungere l'obiettivo di questo articolo, ma solo alcuni si distinguono in termini di funzionalità dinamiche.
Creazione di file di testo in Linux
Creiamo due file di esempio dal terminale Linux. Assicurati di essere un utente sudoer o di disporre dei privilegi sudo sul sistema operativo Linux che stai utilizzando.
$ sudo nano file1
Popoleremo questo file con del contenuto casuale.
1 2 3 4 5 6 7 8 9 10 one two three four five six seven eight nine ten This file contains some number sequences in numeric and textual form. Regards, LinuxShellTips Tutor
Creiamo un secondo file.
$ sudo nano file2
Popoleremo questo file con contenuti leggermente simili a file1 .
11 2 13 4 15 6 7 8 19 10 one twice three four five six seven eight nine ten This file contains some number sequences in numeric form and some textual representation of the numbers. Regards, LinuxShellTips Tutor
Utilizzo di diff per confrontare i file in Linux
Poiché differenza è un programma basato su terminale, utilizzandolo emette le differenze mirate tra due file. In altre parole, la differenza l'output indica le modifiche che possono essere implementate su file1 per renderlo corrispondente o identico a file2 .
Emissione delle differenze tra due file
Implementiamo il primo tentativo di confrontare questi due file:
$ diff file1 file2
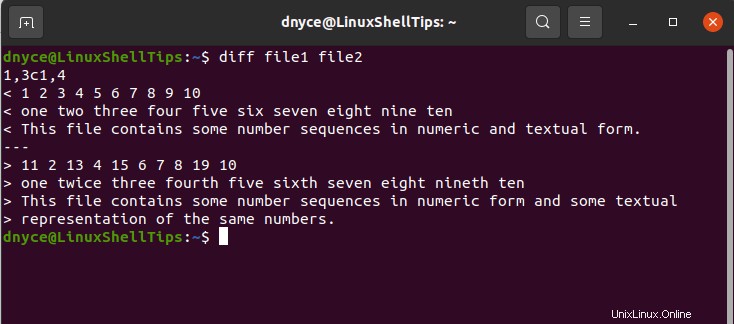
Possiamo interpretare questo output nel modo seguente:
Se torni al file1 originale e file2 file che abbiamo creato in precedenza, noterai che quanto sopra diff l'output del comando non mostra tutto il contenuto dei due file. Ha omesso tutte le somiglianze dei due file e ha mostrato solo le loro differenze.
Scopri che due file sono identici usando Diff in Linux
Creiamo un terzo file chiamato file3 .
$ sudo nano file3
Popoleremo questo file con contenuti simili a file1.
1 2 3 4 5 6 7 8 9 10 one two three four five six seven eight nine ten This file contains some number sequences in numeric and textual form. Regards, LinuxShellTips Tutor
Una differenza a una riga l'output del comando dovrebbe essere in grado di dirci direttamente se due file sono identici.
$ diff -s file1 file3
L'uso dell'extra -s argomento comando rende possibile questo output. Tuttavia, l'implementazione con due file non identici produrrà comunque le loro differenze.
$ diff -s file1 file2
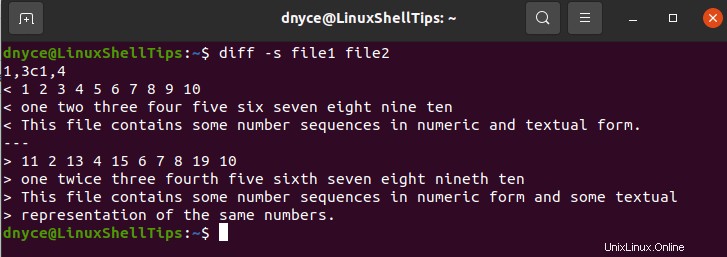
Se stai cercando un output di una riga su due file che sospetti siano diversi, considera l'uso del comando diff con -q opzione.
$ diff -q file1 file2 Files file1 and file2 differ
Vista alternativa output comando Diff
Se hai bisogno che il confronto dell'output dei tuoi due file sia affiancato, prendi in considerazione l'implementazione del diff comando con -y opzione.
$ diff -y file1 file2

Se vuoi che il comando precedente sopprima o ignori le somiglianze dei due file, includi il --suppress-common-lines opzione.
$ diff -y --suppress-common-lines file1 file2
Se hai a che fare con due file di grandi dimensioni e desideri limitare l'output a numeri di colonna specifici, implementeresti il diff comando nel modo seguente.
$ diff -y -W 50 file1 file2
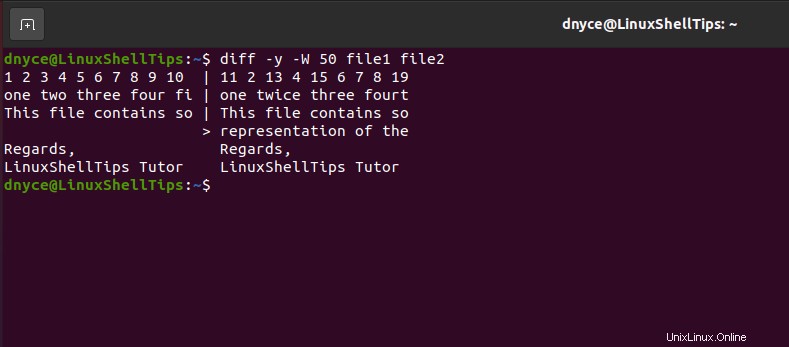
Il comando precedente presuppone che i due file a confronto siano piuttosto grandi e superino 50 colonne in termini di dimensioni del testo. L'output delle differenze sarà limitato a 50 colonne.