Quando devi confrontare due file contenenti testo simile in Linux, l'uso del comando diff può semplificare notevolmente il tuo compito. Il comando confronta due file per suggerire modifiche che renderebbero i file identici. Ottimo per trovare quella parentesi graffa in più che ha rotto il codice appena aggiornato.
Usare il comando diff è molto semplice. Ecco la sintassi:
diff [options] file1 file2Ma capire il suo output è una cosa diversa. Non preoccuparti, ti spiegherò l'output in modo che tu possa confrontare due file e capire la differenza tra loro.
Capire il comando diff in Linux
Hai bisogno di un paio di file per iniziare. Ho generato una lista usando un generatore di parole casuali.
Ho aggiunto l'elenco a due file diversi e poi ho modificato l'elenco con:
- Modifica dell'ordine delle liste
- Aggiunta di lettere
- Scatola di commutazione
Ho salvato questi file simili come 1.txt e 2.txt. Ecco come sono prima che tu faccia qualsiasi cosa.
Ti suggerisco di seguire il tutorial durante la lettura, quindi crea nuovi file e aggiungi il seguente contenuto.
Contenuti di 1.txt :
ragnatela
medaglione
acustica
espansione
registrare
Contenuti di 2.txt:
ragnatela
MEDAGLIONE
acustica
record
espansione
Esempio 1:Diff senza opzioni
Vediamo cosa succede quando esegui diff comando senza alcuna opzione.
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordConfuso? Non sei solo. L'output non è esattamente a misura d'uomo. Per capire cosa sta succedendo, devi saperne di più su come funziona diff.
Può essere utile sapere che al termine dell'analisi, file2 [nella sintassi] viene trattato come il documento di riferimento con cui stai cercando di abbinare. Quindi, puoi dire che diff funziona in questo modo:
diff <file_to_edit> <file_as_reference>Ciò significa anche che otterrai un output diverso in base all'ordine in cui inserisci i nomi dei file.
L'ordine è importante
Un esempio di come l'output differisce a seconda dell'ordine dei file:
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< record
christopher:~$ diff 2.txt 1.txt
2c2
< LOCKET
---
> locket
4d3
< records
5a5
> recordSimboli importanti nell'output del comando diff
Utilizzando la tabella seguente come riferimento, puoi capire meglio cosa sta succedendo nel tuo terminale.
| Simbolo | Significato |
|---|---|
| A | Aggiungi |
| C | Cambia |
| D | Elimina |
| # | Numeri di riga |
| – – – | Separa i file nell'output |
| < | File 1 |
| > | File 2 |
Diamo un'altra occhiata all'output del comando diff:
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordSpiegazione dell'output del comando diff
Vediamo la prima differenza nell'output:
| Riga di output | Spiegazione |
|---|---|
| 2c2 | La riga 2 del file 1, CAMBIA con la riga 2 del file 2. |
| Cambia "locket" in "LOCKET" in modo che corrisponda al file 2.txt |
Diamo un'occhiata alla parte successiva dell'output:
| Riga di output | Spiegazione |
|---|---|
| 3a4 | Dopo la riga 3 del file 1, aggiungi la riga 4 del file 2. |
| > record | Ovvero aggiungere "record" per creare la 4a riga nel file 1. In modo che il file 1.txt corrisponda al file 2.txt |
Allo stesso modo:
| Riga di output | Spiegazione |
|---|---|
5d5 | Elimina il testo "record" dalla quinta riga del file 1. In modo che il file 1.txt corrisponda al file 2.txt | |
Non c'è alcuna funzione di controllo ortografico o dizionario incorporata nel comando. Non riconosce "record" e "record" come correlati. Il suo unico obiettivo è far corrispondere perfettamente i due file.
Guardando l'output, è ancora piuttosto difficile da tradurre. È improbabile che risparmierai molto tempo.
Fortunatamente, ci sono opzioni che possono essere aggiunte per rendere le cose più leggibili dall'uomo. Diamo un'occhiata a un paio di esempi diversi che utilizzano lo stesso elenco.
Esempio 2:Diff nel contesto "Copied" con -c
L'opzione di contesto offre una rappresentazione più visiva rispetto alle informazioni più programmatiche visualizzate per impostazione predefinita. Continuiamo con il nostro testo di esempio.
Simboli più importanti nell'output del comando diff
| Simbolo | Significato |
|---|---|
| + | Aggiungi |
| ! | Cambia |
| – | Elimina |
| *** | File 1 |
| – – – | File 2 |
christopher:~$ diff -c 1.txt 2.txt
*** 1.txt 2019-10-20 12:05:09.244673327 -0400
--- 2.txt 2019-10-20 12:11More:31.382547316 -0400
***************
*** 1,5 ****
cobweb
! locket
acoustics
expansion
- record
--- 1,5 ----
cobweb
! LOCKET
acoustics
+ records
expansionÈ molto più facile da capire quando si visualizzano le informazioni in questo modo. Al posto dell'output alfanumerico, il nuovo set di simboli ti aiuta a identificare rapidamente le differenze tra i due file.
L'output mostra prima il primo file, ovvero 1.txt e la sua riga da 1 a 5. Dice che c'è una leggera modifica nella (parte della) riga 2 del file 1.txt e (parte della) riga 2 del file 2 .txt.
Indica anche che la riga numero 5 del file 1 è stata eliminata (-) nel secondo file.
— 1,5 —- indica l'inizio del secondo file e dice che la riga 2 è leggermente cambiata rispetto alla riga 2 del file 1. Indica anche che la riga 4 è stata aggiunta (+) nel secondo file e non c'è corrispondenza riga nel file 1.
Esempio 3:Diff nel contesto "Unificato" con -u
Questa opzione fornisce un output simile al formato del contesto copiato. Invece di visualizzare i due file separatamente, li unisce insieme.
christopher:~$ diff 1.txt 2.txt -u
--- 1.txt 2019-10-20 12:05:09.244673327 -0400
+++ 2.txt 2019-10-20 12:11:31.382547316 -0400
@@ -1,5 +1,5 @@
cobweb
-locket
+LOCKET
acoustics
+records
expansion
-record
Come puoi vedere, utilizza gli stessi simboli di prima, ma invece del simbolo di modifica, suggerisce le modifiche da apportare utilizzando + di facile lettura o - simboli. Qui, ti consiglia di rimuovere la riga 2 da 1.txt e sostituiscilo con la riga 2 da 2.txt .
In futuro, suggerisce anche di aggiungere record dopo la riga contenente l'acustica ed elimina la riga record dopo la riga contenente l'espansione.
Tutte queste modifiche sono suggerite per il primo file nel comando diff. Questo è un altro scenario in cui è utile ricordare che il programma diff utilizza il secondo file elencato come "originale" o base per le correzioni.
Per confrontare un elenco come questo, personalmente trovo questo metodo più facile da usare. Ti dà una chiara visualizzazione del testo che deve essere modificato per rendere i file identici.
Esempio 4:confronta ma ignora i casi con -i
Le ricerche con distinzione tra maiuscole e minuscole sono l'impostazione predefinita per diff, ma puoi disattivarlo. Diamo un'occhiata a cosa succede quando lo fai.
christopher:~$ diff 1.txt 2.txt -i
3a4
> records
5d5
< recordCome puoi vedere, "locket" e "LOCKET" non sono più elencati come modifiche suggerite.
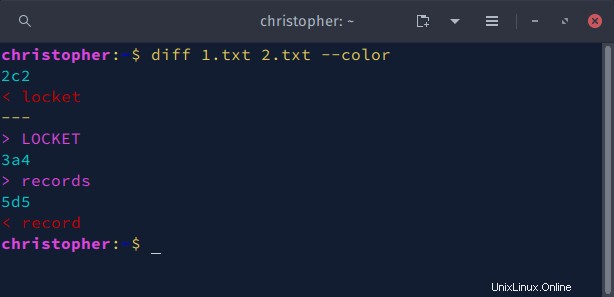
Esempio 5:Diff con –color
Puoi usare --color per evidenziare le modifiche nell'output del comando diff. Quando il comando viene eseguito, le sezioni dell'output verranno stampate con colori diversi dalla tavolozza del terminale.
Esempio 6:analisi rapida dei file con le opzioni del comando diff -s e -q
Esistono un paio di semplici modi per verificare se i file sono identici o meno. Se usi -s ti dirà che i file sono identici o funzionerà diff normalmente.
Usando -q ti dirà solo che i file "differiscono". In caso contrario, non otterrai alcun output.
christopher:~$ diff 1.txt 1.txt -s
Files 1.txt and 1.txt are identical
christopher:~$ diff 1.txt 2.txt -q
Files 1.txt and 2.txt differSuggerimento bonus:utilizzo del comando diff in Linux con file di testo di grandi dimensioni
Potresti non confrontare sempre informazioni così semplici. Potresti avere file di testo di grandi dimensioni da scansionare e trovare le differenze. Illustrerò in dettaglio alcuni metodi per gestire questo tipo di problema.
Per questo esempio, ho creato due file con grandi porzioni di testo (lorem ipsum). Ogni riga ha centinaia di colonne. Questo ovviamente ha reso difficile confrontare le linee.
Quando diff viene eseguito su un file come questo, l'output genera enormi porzioni di testo e i simboli sono difficili da vedere anche con strumenti come l'output contestuale.
Per risparmiare spazio, ho fatto uno screenshot dell'output che puoi guardare.
Non molto utile, vero?
È possibile utilizzare alcuni degli stessi concetti per analizzare questo tipo di file. Non funzioneranno bene a meno che il file non sia formattato correttamente. Alcuni grandi blocchi di testo non hanno interruzioni di riga. Probabilmente hai riscontrato un file come questo in cui era necessario abilitare "Word Wrap" per visualizzare tutto il testo all'interno dello spazio assegnato senza utilizzare una barra di scorrimento. Il motivo per cui ciò accade è che alcuni formati di testo non creano automaticamente interruzioni di riga. Questo è il modo in cui finisci con i grandi blocchi di testo su sole 2-3 righe. C'è una soluzione abbastanza semplice per questo.
Usa piega per avvolgere il testo in righe
Questo è il manuale di Linux quindi, naturalmente, abbiamo una soluzione per te e possiamo stipare un mini tutorial. C'è un ottimo articolo su fold (Unix) e fmt (GNU) qui. Farò un rapido esempio che dovrebbe essere abbastanza autoesplicativo per farci andare avanti.
Il comando piega viene utilizzato per spezzare le righe utilizzando il numero di colonne. Può essere personalizzato per darti opzioni su come vengono implementate queste nuove interruzioni di riga.
Nell'esempio qui, separerai il file in una larghezza standardizzata e utilizzerai -s opzione. Questo dice al programma di interrompersi SOLO dove ci sono spazi bianchi, non nel mezzo del testo.
Utilizza piega per inserire rapidamente interruzioni di riga
fold -w 80 -s lorem.txt > lorem.txt
fold -w 80 -s lorem2.txt > lorem2.txtCon entrambi i file suddivisi in 31 righe anziché 3, puoi confrontarli in modo molto più efficace. Ecco un esempio del tuo output con il filtro di contesto unificato.
christopher:~$ diff lorem.txt 2lorem.txt -u
--- lorem.txt 2019-10-27 09:39:07.298691695 -0400
+++ 2lorem.txt 2019-10-27 09:39:08.370704501 -0400
@@ -1,10 +1,10 @@
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus in tincidunt
sapien. Maecenas sagittis ex risus, in vehicula turpis imperdiet sed. Phasellus
placerat posuere maximus. In hac habitasse platea dictumst. Ut vel tristique
-eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
+eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
Suspendisse at mauris vitae sapien euismod tincidunt. Sed placerat finibus
blandit. Duis ornare ante at ipsum accumsan, nec bibendum nibh tincidunt.
-Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
+Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
vitae enim. Nam condimentum, purus nec semper efficitur, nisi quam vehicula
sem, eget finibus diam ipsum suscipit velit.
@@ -21,7 +21,7 @@
Maecenas lacinia cursus tristique. Nulla a hendrerit orci. Donec lobortis nisi
sed ante euismod lobortis. Nullam sit amet est nec nunc porttitor sollicitudin
-a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
+a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at
interdum mi metus vel tellus. Fusce nec dui a risus posuere mattis at eu orci.
Proin purus sem, finibus eget viverra vel, porta pulvinar ex. In hac habitasse
platea dictumst. Nunc faucibus leo nec tristique porta. Phasellus luctus ipsumUsa diff con –minimal output
Puoi renderlo un po' più facile da leggere con il --minimal etichetta. Questo rende i file di testo più grandi un po' più facili da leggere. Diamo un'occhiata all'output.
christopher:~$ diff lorem.txt 2lorem.txt --minimal
4c4
< eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
---
> eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
7c7
< Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
---
> Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
24c24
< a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
---
> a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at Puoi combinare uno qualsiasi di questi suggerimenti o utilizzare alcune delle altre opzioni elencate nelle pagine man di diff. Questa è un'utilità software potente e facile da usare.
Spero che questo articolo ti sia stato utile. Se hai un consiglio, non dimenticare di lasciarci un commento e raccontarcelo.