Valori separati da virgola alias CSV è un dato semistrutturato che utilizza la virgola come delimitatore per separare le parole. I formati di file CSV sono molto popolari tra i professionisti dei dati poiché devono gestire molti file CSV ed elaborarli per creare approfondimenti. In questo articolo, ci concentreremo su come analizzare i file CSV negli script della shell Bash in Linux.
Nella maggior parte delle parti di questo articolo utilizzerò awk e sed strumenti per l'analisi CSV invece di combinare comandi diversi come grep , cut , tr , ecc.
Il awk l'utilità riduce la complessità del piping di più comandi o della scrittura di un ciclo con la logica per acquisire i dati. Invece, puoi scrivere un codice one-liner in awk per fare il lavoro.
1. Preparazione del file CSV per l'elaborazione
Il tuo file CSV potrebbe essere generato da un database, un'API o potresti aver eseguito alcuni comandi e convertito l'output in delimitare in formato CSV. In ogni caso, devi prima analizzare il set di dati prima di eseguire la tua logica su di esso.
Come best practice, dovresti pulire il tuo set di dati prima di usarlo. Perché dovremmo pulire il set di dati? Potrebbero esserci situazioni in cui ci saranno valori di celle vuote o nessuna formattazione corretta nelle intestazioni, colonne extra che non sono necessarie per l'elaborazione e molti altri.
Sto utilizzando i seguenti dati CSV, che ho preso da Kaggle a scopo dimostrativo.
Player_Id,Player_Name,DOB,Batting_Hand,Bowling_Skill,Country 1,SC Ganguly,8-Jul-72,Left_Hand,Right-arm medium, 2,BB McCullum,27-Sep-81,Right_Hand,Right-arm medium, 3,RT Ponting,19-Dec-74,Right_Hand,Right-arm medium, 4,DJ Hussey,15-Jul-77,Right_Hand,Right-arm offbreak,Australia 5,Mohammad Hafeez,17-Oct-80,,Right-arm offbreak,Pakistan 6,R Dravid,11-Jan-73,,Right-arm offbreak,India 7,W Jaffer,16-Feb-78,,Right-arm offbreak,India 8,V Kohli,5-Nov-88,,Right-arm medium,India 9,JH Kallis,16-Oct-75,,Right-arm fast-medium,South Africa 10,CL White,18-Aug-83,Right_Hand,Legbreak googly,Australia 11,MV Boucher,3-Dec-76,Right_Hand,Right-arm medium,South Africa 12,B Akhil,7-Oct-77,Right_Hand,Right-arm medium-fast,India 13,AA Noffke,30-Apr-77,Right_Hand,Right-arm fast-medium,Australia 14,P Kumar,2-Oct-86,Right_Hand,Right-arm medium,India 15,Z Khan,7-Oct-78,Right_Hand,Left-arm fast-medium,India
1.1. Sostituisci celle vuote
In alcuni casi, il file CSV non conterrà alcun valore in determinate celle. Dai un'occhiata allo screenshot qui sotto dove ci sono alcune celle vuote tra le colonne.
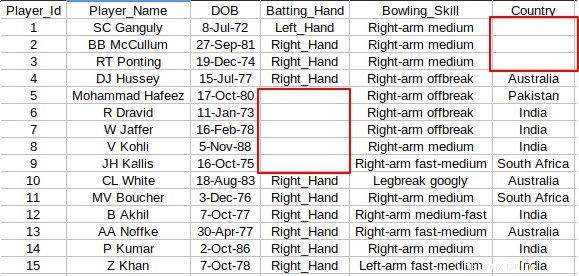
Lo sostituirei sempre con "NA" o "Nessun valore", quindi non ci saranno celle vuote. Puoi usare il seguente awk snippet per sostituire qualsiasi cella vuota con il valore desiderato. In questo caso, sto sostituendo le celle vuote con "Nessun valore".
awk 'BEGIN{FS=",";OFS=","}
{
for(i=1;i<=NF;i++)
{
if($i == ""){
$i="No Value"
}
}
print
}' ~/Downloads/Player.csv > player_cleaned.csv
Il modo in cui funziona questo snippet è che sto impostando il separatore di campo e il separatore di campo di output su virgola (FS=",";OFS="," ). Usando for loop , scorrere ogni cella in una riga e, se una cella viene trovata vuota ($i == "" ) quindi sostituirlo con "No value" ($i="No value" ). Devi reindirizzare le modifiche a un nuovo file.
Lettura consigliata:
- Il reindirizzamento di Bash spiegato con esempi
1.2. Metti in maiuscolo l'intestazione
I file CSV possono avere o meno intestazioni. Ma se c'è un'intestazione, la metterei sempre in maiuscolo per una migliore leggibilità. Puoi farlo facilmente usando awk o sed . Ti mostrerò entrambi i modi.
awk 'BEGIN{FS=",";OFS=","}
{
if(NR==1){
print toupper($0)
} else {
print
}
}' player.csv > player_cleaned.csv
Qui stiamo controllando se la riga è di prima riga usando(NR==1 ) e utilizzando toupper() funzione per capitalizzarlo. Lo stesso snippet può essere scritto come una riga.
awk 'NR==1{ print toupper($0) }NR>1' player.csv > player_cleaned.csv
Usando awk , devi reindirizzare nuovamente le modifiche a un nuovo file. Invece, puoi usare 'sed ' per modificare le modifiche direttamente nel file. Qui \U converte le maiuscole in maiuscolo. Se vuoi eseguire la conversione in minuscolo, usa \L .
$ sed -i -e '1 s/(.*)/\U\1/' player_cleaned.csv
$ cat player_cleaned.csv
1.3. Rimuovi la virgola finale
Il tuo file CSV potrebbe contenere una virgola alla fine. Per pulire le virgole finali, puoi seguire il metodo seguente.
Ho aggiunto di proposito una virgola finale dalle righe 7 a 11 nel mio file di dati.
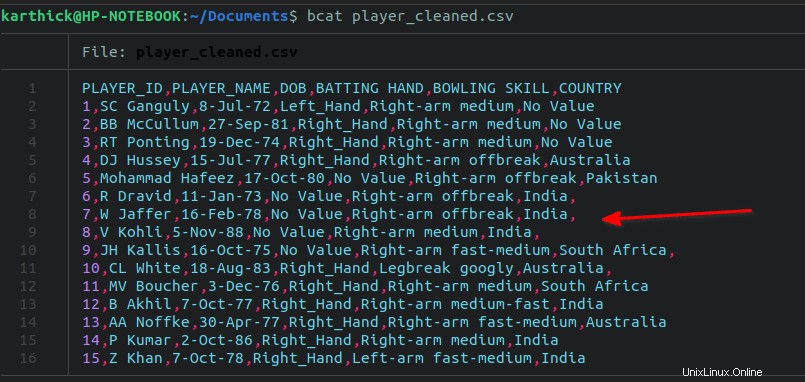
Per rimuovere tutte le virgole finali, esegui il seguente sed comando:
$ sed -i 's/,$//' ~/Documents/player_cleaned.csv
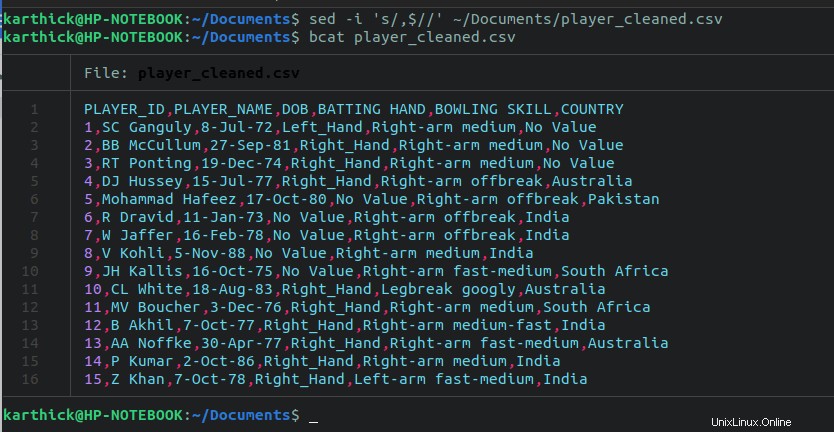
Ora abbiamo finito con la parte di pulizia. Potrebbero essere necessari alcuni passaggi in più per te, ma ciò dipende da come è strutturato il tuo file CSV e da cosa deve essere pulito.
2. File CSV Pretty Print nel terminale
Se stai cercando di visualizzare i file CSV nel terminale, ci sono alcune opzioni in cui puoi stampare il file in formato tabulare che ti darà una migliore leggibilità.
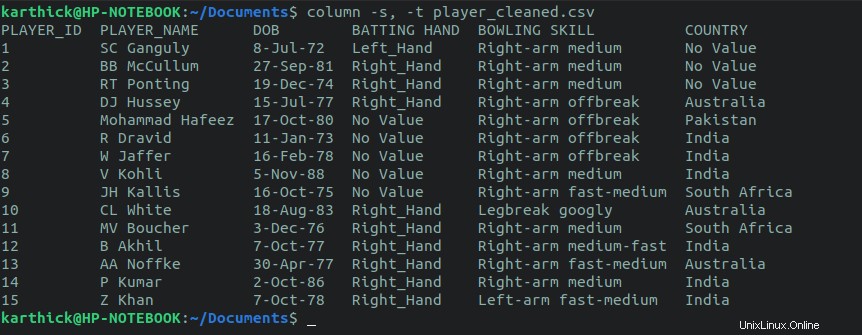
2.1. Comando Colonna
Il primo approccio consiste nell'utilizzare la column comando. Il comando Colonna accetta un separatore che è impostato su virgola e un delimitatore per dividere la colonna che è impostata su tab nel comando seguente. Puoi anche impostare i tuoi delimitatori personalizzati.
$ cat player_cleaned.csv | column -s, -t $ column -s, -t player_cleaned.csv
2.2. Comando Guarda CSV
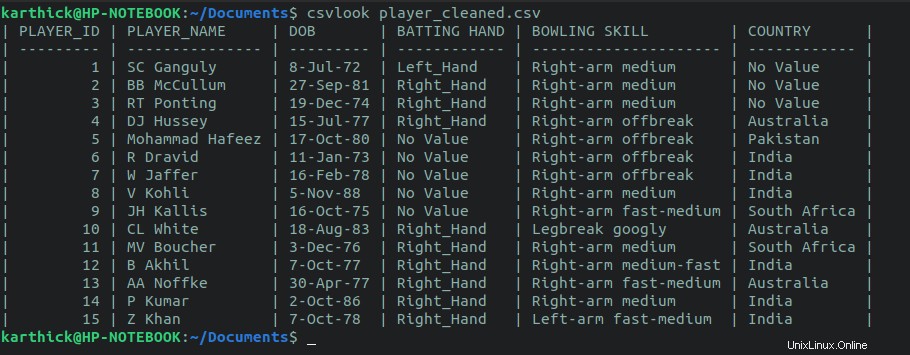
Csvlook è un'utilità fornita con il pacchetto csvkit. Non è necessario impostare un delimitatore come abbiamo fatto con la column comando.
$ cat player_cleaned.csv | csvlook
$ csvlook player_cleaned.csv
2.3. Python Pretty Table
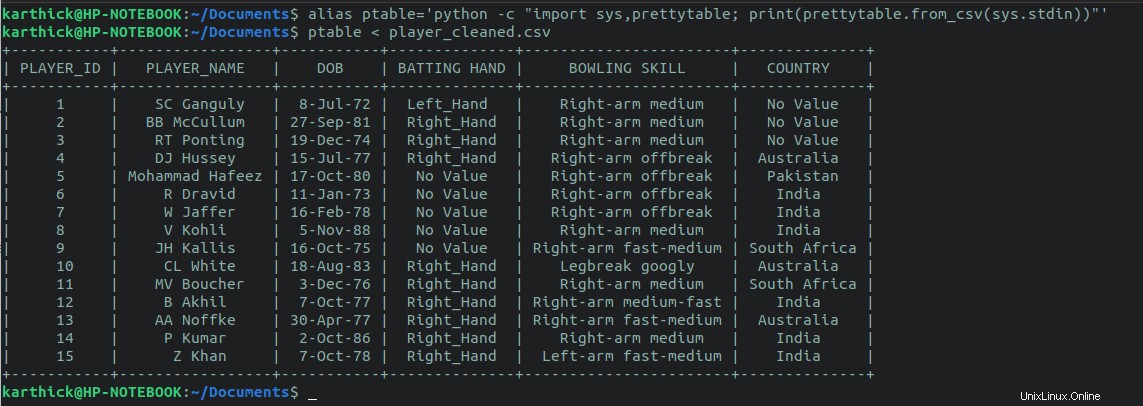
Se hai il python prettytable modulo installato, quindi puoi eseguire il seguente one-liner e reindirizzare il file CSV per generare la tabella.
python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))" < player_cleaned.csv
Puoi anche creare un alias per il one-liner e passare il nome del file come argomento.
$ alias ptable='python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))"'
$ ptable < player_cleaned.csv
3. Acquisizione di dati da file CSV
3.1. Stampa conteggio righe e colonne
Per ottenere il numero di colonne nel file CSV, eseguire il comando seguente. Qui la variabile NF rappresenta il numero di campi divisi da una virgola come delimitatore.
$ awk -F, 'END{print NF}' player_cleaned.csv
6
Per ottenere il numero di righe, eseguire il comando seguente. Qui la variabile NR rappresenta il record corrente (cioè) ogni riga è considerata come un record.
$ awk -F, 'END{print NR}' player_cleaned.csv
16 Per saltare la prima riga (intestazione) e calcolare il numero di righe, eseguire il comando seguente.
$ awk -F, 'END{print NR-1}' player_cleaned.csv
15 3.2. Stampa l'intero file CSV
Questo è abbastanza semplice. Puoi usare cat o awk per stampare l'intero file CSV.
$ cat player_cleaned.csv
$ awk '{print}' player_cleaned.csv 3.3. Stampa solo intestazione da file CSV
La stampa dell'intestazione da sola ti darà una buona panoramica del tipo di dati che contiene il tuo file CSV. Puoi usare il head o awk comando per catturare l'intestazione da solo.
$ head -n 1 player_cleaned.csv
$ awk 'NR==1' player_cleaned.csv PLAYER_ID,PLAYER_NAME,DOB,BATTING HAND,BOWLING SKILL,COUNTRY
3.4. Escludi riga di intestazione
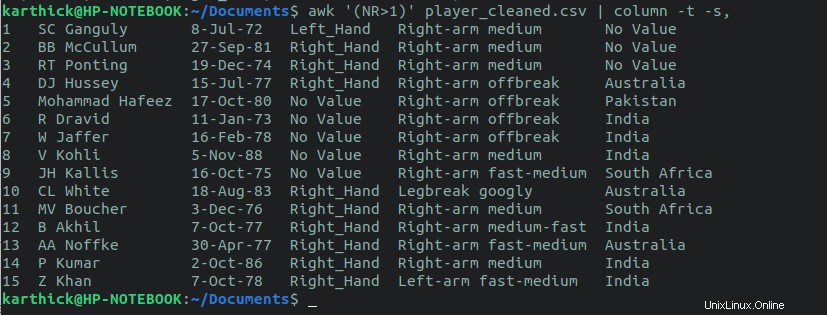
Per escludere la riga di intestazione e stampare tutte le altre righe usa awk comando. La variabile awk NR > 1 farà saltare la prima riga.
$ awk '(NR>1)' player_cleansed.csv
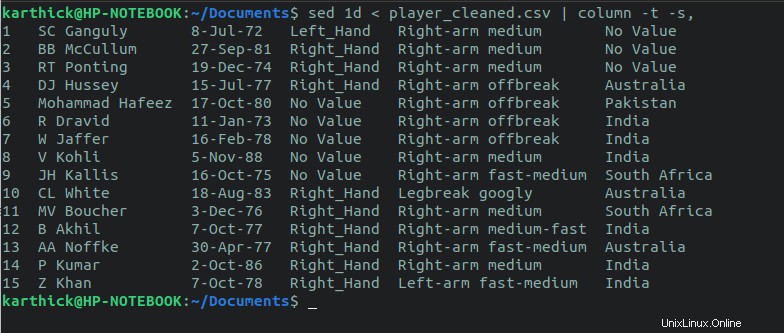
Sed può essere utilizzato anche per escludere la prima riga e stampare tutte le altre righe. Il 1d flag cancellerà la prima riga e stamperà tutte le altre righe su stdout (Terminale).
$ sed 1d < player_cleaned.csv
3.5. Stampa colonne particolari
Possiamo usare la posizione della colonna per stampare l'intera colonna. Ci sono due approcci per raggiungere questo obiettivo. Il primo approccio sarà utilizzare awk e il secondo approccio sarà quello di utilizzare loop . Awk sarà molto più semplice afferrare la colonna.
Awk per impostazione predefinita divide la riga in base al delimitatore e memorizza i valori in $1 , $2 , $3 , ecc. Il delimitatore predefinito per awk è spazio bianco .
Dai un'occhiata allo snippet di seguito in cui il separatore di campo(FS="," ) e separatore del campo di output(OFS="," ) è impostato su virgola. L'istruzione print stamperà la prima colonna, la seconda colonna e la sesta colonna.
awk 'BEGIN{FS=",";OFS=","}
{
print $1,$2,$6
}' player_cleansed.csv Puoi anche scrivere lo snippet sopra in una riga.
awk 'BEGIN{FS=",";OFS=","}{print $1,$2,$6}' player_cleansed.csv 
Ora il secondo approccio sarebbe quello di utilizzare i loop.
IFS=","
while read -r -a fields
do
echo ${fields[0]},${fields[1]},${fields[5]}
done < player_cleaned.csv Lascia che ti spieghi cosa succede esattamente quando esegui lo snippet sopra.
- Stiamo impostando l'IFS separatore di campo interno su virgola.
- Usando il comando di lettura stiamo creando un array chiamato "fields" e reindirizzando il file di input al
while loop. - Per ogni iterazione, leggerà riga per riga e memorizzerà la riga come elementi dell'array nei "campi" in modo da poter utilizzare la posizione dell'indice dell'array per afferrare solo la particolare colonna.
Nota: Il valore dell'indice inizia da 0..N
3.6. Stampa riga che corrisponde alla condizione
Se desideri stampare le righe che soddisfano una determinata condizione, puoi farlo facilmente utilizzando awk . Esaminiamo alcuni scenari.
Per stampare tutte le righe che corrispondono a un valore in una colonna, eseguire il comando seguente. Qui sto cercando di stampare tutte le righe che corrispondono al valore "India" nella colonna 6.
$ awk -F , '$6 == "India"' player_cleaned.csv

Per stampare tutte le righe che non corrispondono a un determinato valore, eseguire il comando seguente. Invece di un operatore di uguaglianza , stiamo usando operatore non uguale .
$ awk -F , '$6 != "India"' player_cleaned.csv
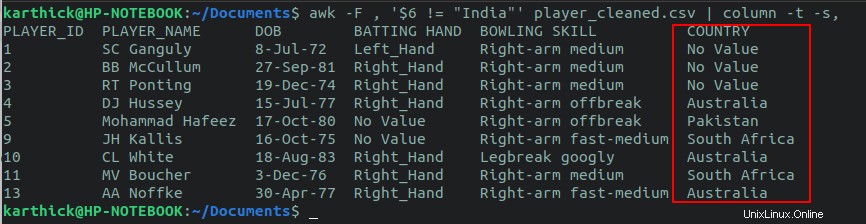
Puoi anche eseguire un controllo delle condizioni su più di una colonna utilizzando l'operatore logico AND, OR logico. Diciamo che voglio controllare tutte le righe che hanno il paese come "India" e la mano in battuta come "Right_hand".
Qui, $4 punta alla 4a colonna e $6 indica la sesta colonna. Il simbolo && viene utilizzato come operatore AND logico per valutare due condizioni.
$ awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv

Se desideri includere l'intestazione insieme al risultato del controllo condizionale, utilizza il comando seguente. Per prima cosa sto stampando la prima riga usando NR==1 , quindi utilizzando l'operatore AND logico che esegue il controllo condizionale per stampare i risultati.
$ awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv
Se desideri stampare o reindirizzare l'output, esegui l'intero comando all'interno di una subshell racchiudendolo tra parentesi .
$ (awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv) | column -t -s,

Una nota su Csvkit
Finora tutto ciò che abbiamo visto in questo articolo è semplice e diretto. Ma quando il tuo file CSV ha una struttura complessa, diventa noioso analizzare usando l'approccio sopra. Esiste un'utilità chiamata CSVKIT , che è un'eccellente utility per lavorare con i file CSV in bash.
Il problema con l'utilità csvkit è che è installata per impostazione predefinita nella distribuzione e potrebbe essere necessario installarla manualmente. Nel tuo ambiente aziendale, ciò potrebbe non essere possibile poiché potrebbero esserci alcune restrizioni all'installazione di pacchetti esterni. Ma questa utilità vale la pena menzionarla e creeremo un articolo dettagliato separato per questo.
Conclusione
In questa guida abbiamo visto come lavorare con i file CSV usando awk, sed. Puoi anche usare altre utilità come cut, grep, tr, ecc. per ottenere il risultato desiderato, ma awk e sed ti semplificheranno la vita e ridurranno la complessità della scrittura di molti codici. Se hai qualche feedback, menzionalo nella sezione commenti e saremo felici di sentirlo da te.
Lettura simile:
- Scripting Bash:analisi degli argomenti negli script Bash utilizzando getopts
- Come analizzare e stampare in modo grazioso JSON con gli strumenti della riga di comando di Linux