Apache Kafka è una piattaforma di streaming distribuita. È utile per creare pipeline di dati in streaming in tempo reale per ottenere dati tra i sistemi o le applicazioni. Un'altra caratteristica utile sono le applicazioni di streaming in tempo reale che possono trasformare flussi di dati o reagire su un flusso di dati. Questo tutorial ti aiuterà a installare Apache Kafka sui sistemi Ubuntu 19.10, 18.04 e 16.04.
Fase 1 – Installa Java
Apache Kafka richiedeva Java per essere eseguito. Devi avere java installato sul tuo sistema. Esegui il comando seguente per installare OpenJDK predefinito sul tuo sistema dai PPA ufficiali. Puoi anche installare la versione specifica di da qui.
sudo apt update sudo apt install default-jdk
Fase 2:scarica Apache Kafka
Scarica i file binari di Apache Kafka dal suo sito Web di download ufficiale. Puoi anche selezionare qualsiasi mirror nelle vicinanze da scaricare.
wget https://www.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
Quindi estrai il file di archivio
tar xzf kafka_2.13-2.7.0.tgz mv kafka_2.13-2.7.0 /usr/local/kafka
Passaggio 3:installazione dei file di unità di sistema Kafka
Quindi, crea file di unità systemd per il servizio Zookeeper e Kafka. Questo aiuterà a gestire i servizi Kafka per avviare/arrestare usando il comando systemctl.
Innanzitutto, crea il file dell'unità systemd per Zookeeper con il comando seguente:
vim /etc/systemd/system/zookeeper.service
Aggiungi sotto contnet:
[Unit] Description=Apache Zookeeper server Documentation=http://zookeeper.apache.org Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Salva il file e chiudilo.
Quindi, per creare un file di unità di sistema Kafka utilizzando il comando seguente:
vim /etc/systemd/system/kafka.service
Aggiungi il contenuto di seguito. Assicurati di impostare il corretto JAVA_HOME percorso come da Java installato sul tuo sistema.
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64" ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target
Salva il file e chiudi.
Ricarica il demone systemd per applicare nuove modifiche.
systemctl daemon-reload
Fase 4:avvia Kafka Server
Kafka ha richiesto ZooKeeper, quindi prima avvia un server ZooKeeper sul tuo sistema. Puoi utilizzare lo script disponibile con Kafka per avviare un'istanza ZooKeeper a nodo singolo.
sudo systemctl start zookeeper
Ora avvia il server Kafka e visualizza lo stato di esecuzione:
sudo systemctl start kafka sudo systemctl status kafka
Tutto fatto. L'installazione di Kafka è stata completata con successo. Questa parte di questo tutorial ti aiuterà a lavorare con il server Kafka.
Fase 5:crea un argomento in Kafka
Kafka fornisce più script di shell predefiniti per lavorarci. Innanzitutto, crea un argomento denominato "testTopic" con una singola partizione con un'unica replica:
cd /usr/local/kafka bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic Created topic testTopic.
Il fattore di replica descrive quante copie di dati verranno create. Poiché stiamo eseguendo con una singola istanza, mantieni questo valore 1.
Imposta le opzioni delle partizioni come il numero di broker tra i quali desideri che i tuoi dati vengano suddivisi. Poiché stiamo correndo con un unico broker, mantieni questo valore 1.
Puoi creare più argomenti eseguendo lo stesso comando di cui sopra. Successivamente, puoi vedere gli argomenti creati su Kafka eseguendo il comando seguente:
bin/kafka-topics.sh --list --zookeeper localhost:2181 testTopic TecAdminTutorial1 TecAdminTutorial2
In alternativa, invece di creare argomenti manualmente, puoi anche configurare i tuoi broker per creare automaticamente argomenti quando viene pubblicato un argomento inesistente.
Fase 6:invia messaggi a Kafka
Il "produttore" è il processo responsabile dell'inserimento dei dati nel nostro Kafka. Kafka viene fornito con un client della riga di comando che prenderà l'input da un file o dallo standard input e lo invierà come messaggi al cluster Kafka. Il Kafka predefinito invia ogni riga come messaggio separato.
Eseguiamo il produttore e quindi digitiamo alcuni messaggi nella console da inviare al server.
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic >Welcome to kafka >This is my first topic >
È possibile uscire da questo comando o mantenere in esecuzione questo terminale per ulteriori test. Ora apri un nuovo terminale per il processo del consumatore Kafka nel passaggio successivo.
Fase 7:utilizzo di Kafka Consumer
Kafka ha anche un consumer della riga di comando per leggere i dati dal cluster Kafka e visualizzare i messaggi nell'output standard.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning Welcome to kafka This is my first topic
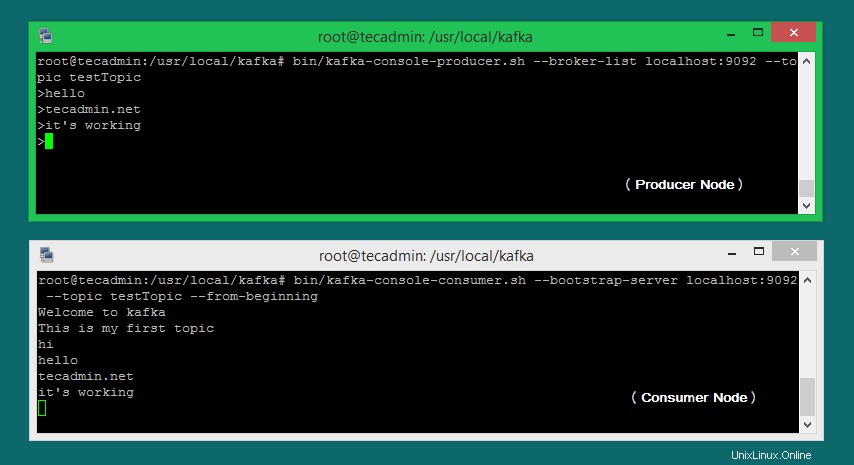
Ora, se hai ancora in esecuzione il produttore Kafka (passaggio n. 6) in un altro terminale. Basta digitare del testo su quel terminale del produttore. sarà immediatamente visibile sul terminale del consumatore. Guarda lo screenshot qui sotto del produttore e consumatore Kafka al lavoro:
Conclusione
Hai installato e configurato correttamente il servizio Kafka sulla tua macchina Ubuntu Linux.