Introduzione
Apache Hive è un sistema di data warehouse aziendale utilizzato per interrogare, gestire e analizzare i dati archiviati nel file system distribuito Hadoop.
Hive Query Language (HiveQL) facilita le query in una shell dell'interfaccia della riga di comando di Hive. Hadoop può utilizzare HiveQL come ponte per comunicare con i sistemi di gestione di database relazionali ed eseguire attività basate su comandi simili a SQL.
Questa semplice guida ti mostra come installare Apache Hive su Ubuntu 20.04 .

Prerequisiti
Apache Hive è basato su Hadoop e richiede un framework Hadoop completamente funzionale.
Installa Apache Hive su Ubuntu
Per configurare Apache Hive, devi prima scaricare e decomprimere Hive. Quindi devi personalizzare i seguenti file e impostazioni:
- Modifica .bashrc file
- Modifica hive-config.sh file
- Crea directory Hive in HDFS
- Configura hive-site.xml file
- Avvia database Derby
Passaggio 1:scarica e Rimuovi Hive
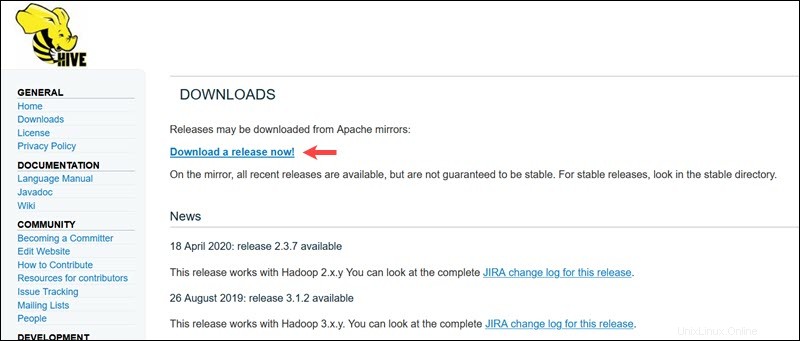
Visita la pagina di download ufficiale di Apache Hive e determina quale versione di Hive è più adatta per la tua edizione Hadoop. Una volta stabilita la versione di cui hai bisogno, seleziona Scarica una versione ora! opzione.
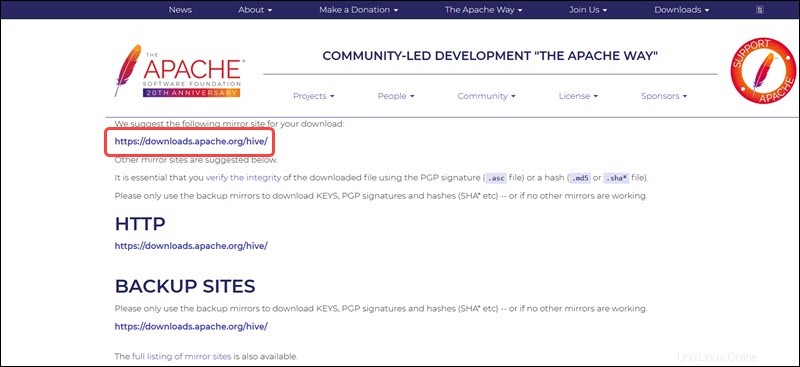
Il collegamento mirror nella pagina successiva conduce alle directory contenenti i pacchetti Hive tar disponibili. Questa pagina fornisce anche istruzioni utili su come convalidare l'integrità dei file recuperati dai siti mirror.
Il sistema Ubuntu presentato in questa guida ha già Hadoop 3.2.1 installato. Questa versione di Hadoop è compatibile con Hive 3.1.2 rilascio.
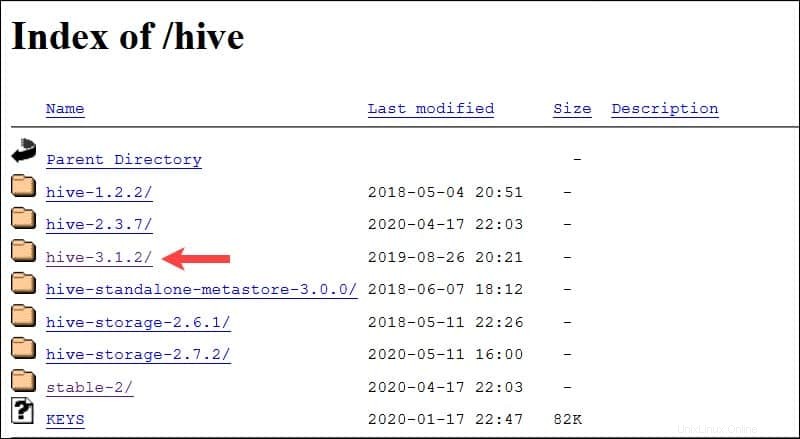
Seleziona apache-hive-3.1.2-bin.tar.gz file per iniziare il processo di download.
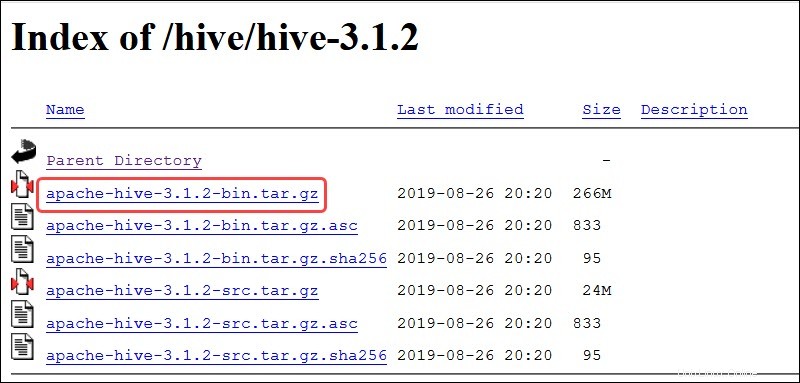
In alternativa, accedi alla riga di comando di Ubuntu e scarica i file Hive compressi utilizzando e il wget comando seguito dal percorso di download:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz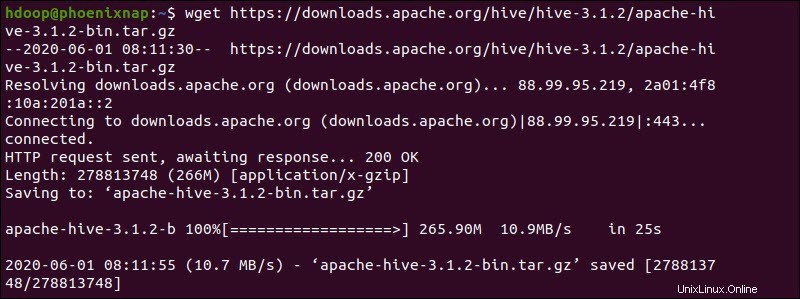
Una volta completato il processo di download, decomprimi il pacchetto Hive compresso:
tar xzf apache-hive-3.1.2-bin.tar.gzI file binari di Hive ora si trovano in apache-hive-3.1.2-bin directory.

Fase 2:configura le variabili di ambiente Hive (bashrc)
Il $HIVE_HOME la variabile di ambiente deve indirizzare la shell del client a apache-hive-3.1.2-bin directory. Modifica il .bashrc file di configurazione della shell utilizzando un editor di testo a tua scelta (useremo nano):
sudo nano .bashrcAggiungi le seguenti variabili di ambiente Hive a .bashrc file:
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binLe variabili di ambiente Hadoop si trovano all'interno dello stesso file.
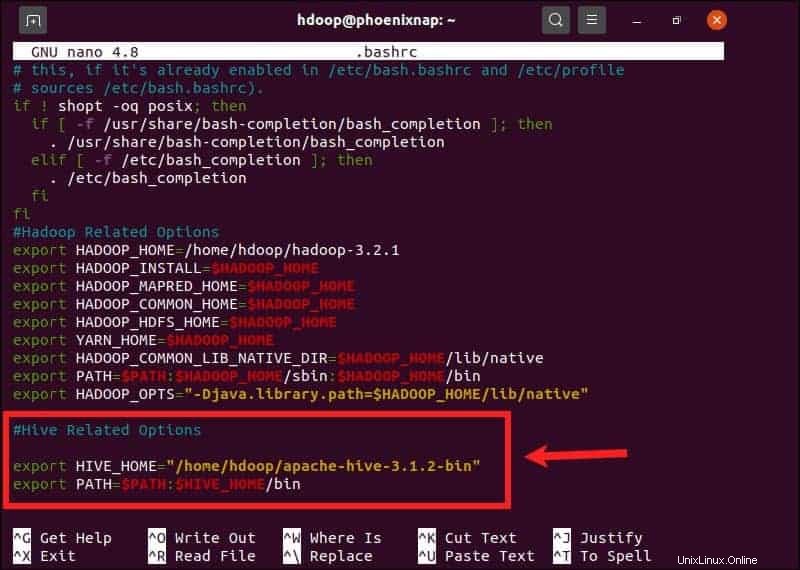
Salva ed esci da .bashrc dopo aver aggiunto le variabili Hive. Applicare le modifiche all'ambiente corrente con il seguente comando:
source ~/.bashrcFase 3:modifica il file hive-config.sh
Apache Hive deve essere in grado di interagire con il file system distribuito Hadoop. Accedi a hive-config.sh utilizzando il $HIVE_HOME creato in precedenza variabile:
sudo nano $HIVE_HOME/bin/hive-config.sh
Aggiungi il HADOOP_HOME variabile e il percorso completo della directory Hadoop:
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
Salva le modifiche ed esci da hive-config.sh file.
Fase 4:crea directory hive in HDFS
Crea due directory separate per archiviare i dati nel livello HDFS:
- Il temporaneo, tmp directory memorizzerà i risultati intermedi dei processi Hive.
- Il magazzino directory memorizzerà le tabelle relative a Hive.
Crea directory tmp
Crea un tmp directory all'interno del livello di archiviazione HDFS. Questa directory memorizzerà i dati intermedi che Hive invia all'HDFS:
hdfs dfs -mkdir /tmpAggiungi i permessi di scrittura ed esecuzione ai membri del gruppo tmp:
hdfs dfs -chmod g+w /tmpControlla se le autorizzazioni sono state aggiunte correttamente:
hdfs dfs -ls /L'output conferma che gli utenti ora dispongono delle autorizzazioni di scrittura ed esecuzione.

Crea directory magazzino
Crea il magazzino directory all'interno di /user/hive/ directory principale:
hdfs dfs -mkdir -p /user/hive/warehouseAggiungi scrivi ed esegui autorizzazioni per magazzino membri del gruppo:
hdfs dfs -chmod g+w /user/hive/warehouseControlla se le autorizzazioni sono state aggiunte correttamente:
hdfs dfs -ls /user/hiveL'output conferma che gli utenti ora dispongono delle autorizzazioni di scrittura ed esecuzione.

Passaggio 5:configura il file hive-site.xml (facoltativo)
Per impostazione predefinita, le distribuzioni Apache Hive contengono file di configurazione dei modelli. I file modello si trovano all'interno di Hive conf directory e delinea le impostazioni Hive predefinite.
Utilizzare il comando seguente per individuare il file corretto:
cd $HIVE_HOME/conf
Elenca i file contenuti nella cartella utilizzando ls comando.

Usa hive-default.xml.template per creare il hive-site.xml file:
cp hive-default.xml.template hive-site.xmlAccedi a hive-site.xml file utilizzando l'editor di testo nano:
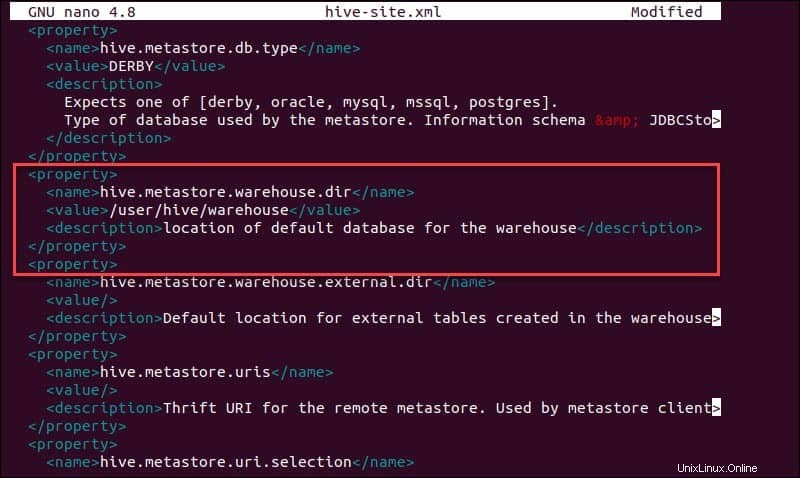
sudo nano hive-site.xmlL'uso di Hive in una modalità autonoma anziché in un cluster Apache Hadoop reale è un'opzione sicura per i nuovi arrivati. È possibile configurare il sistema per utilizzare la memoria locale anziché il livello HDFS impostando hive.metastore.warehouse.dir valore del parametro alla posizione del tuo magazzino Hive directory.
Fase 6:avvia il database del derby
Apache Hive utilizza il database Derby per archiviare i metadati. Avvia il database del Derby, dal bin dell'alveare directory utilizzando lo schematool comando:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaIl completamento del processo può richiedere alcuni istanti.
Derby è l'archivio di metadati predefinito per Hive. Se prevedi di utilizzare una soluzione di database diversa, come MySQL o PostgreSQL, puoi specificare un tipo di database in hive-site.xml file.
Come risolvere l'errore di incompatibilità della guava in Hive
Se il database Derby non viene avviato correttamente, potresti ricevere un errore con il seguente contenuto:
"Eccezione nel thread "main" java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V"
Questo errore indica che molto probabilmente c'è un problema di incompatibilità tra Hadoop e Hive guava versioni.
Individua il barattolo di guava file nell'hive lib directory:
ls $HIVE_HOME/lib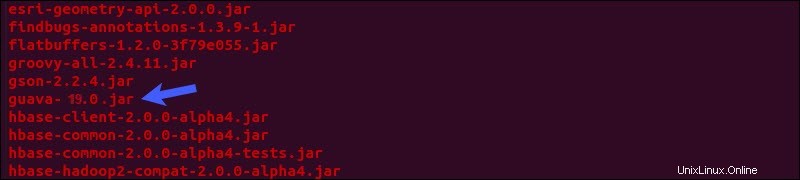
Individua il barattolo di guava nel file Hadoop lib anche directory:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
Le due versioni elencate non sono compatibili e causano l'errore. Rimuovi la guava esistente file dall'hive lib directory:
rm $HIVE_HOME/lib/guava-19.0.jarCopia la guava file da Hadoop lib directory nell'hive lib directory:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
Usa lo schematool comando ancora una volta per avviare il database Derby:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaAvvia Hive Client Shell su Ubuntu
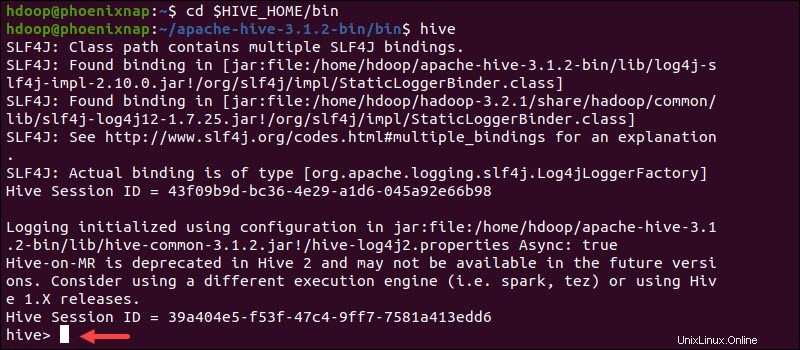
Avvia l'interfaccia della riga di comando di Hive utilizzando i seguenti comandi:
cd $HIVE_HOME/binhiveOra puoi inviare comandi simili a SQL e interagire direttamente con HDFS.