Introduzione
Apache Spark è un framework utilizzato negli ambienti di cluster computing per l'analisi dei big data . Questa piattaforma è diventata molto popolare grazie alla sua facilità d'uso e alle velocità di elaborazione dei dati migliorate rispetto a Hadoop.
Apache Spark è in grado di distribuire un carico di lavoro su un gruppo di computer in un cluster per elaborare in modo più efficace grandi set di dati. Questo motore open source supporta un'ampia gamma di linguaggi di programmazione. Ciò include Java, Scala, Python e R.
In questo tutorial imparerai come installare Spark su una macchina Ubuntu . La guida ti mostrerà come avviare un server master e slave e come caricare le shell Scala e Python. Fornisce anche i comandi Spark più importanti.

Prerequisiti
- Un sistema Ubuntu.
- Accesso a un terminale oa una riga di comando.
- Un utente con sudo o root autorizzazioni.
Installa i pacchetti necessari per Spark
Prima di scaricare e configurare Spark, è necessario installare le dipendenze necessarie. Questo passaggio include l'installazione dei seguenti pacchetti:
- JDK
- Scala
- Git
Apri una finestra di terminale ed esegui il comando seguente per installare tutti e tre i pacchetti contemporaneamente:
sudo apt install default-jdk scala git -yVedrai quali pacchetti verranno installati.
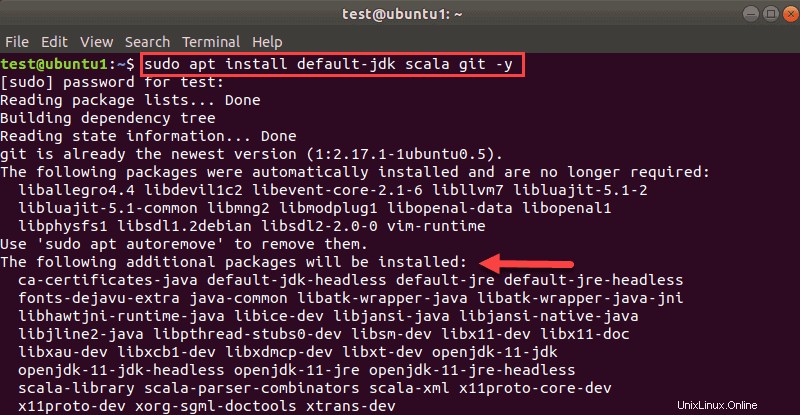
Al termine del processo, verifica le dipendenze installate eseguendo questi comandi:
java -version; javac -version; scala -version; git --version
L'output stampa le versioni se l'installazione è stata completata correttamente per tutti i pacchetti.
Scarica e configura Spark su Ubuntu
Ora devi scaricare la versione di Spark che desideri formano il loro sito web. Sceglieremo Spark 3.0.1 con Hadoop 2.7 in quanto è l'ultima versione al momento della stesura di questo articolo.
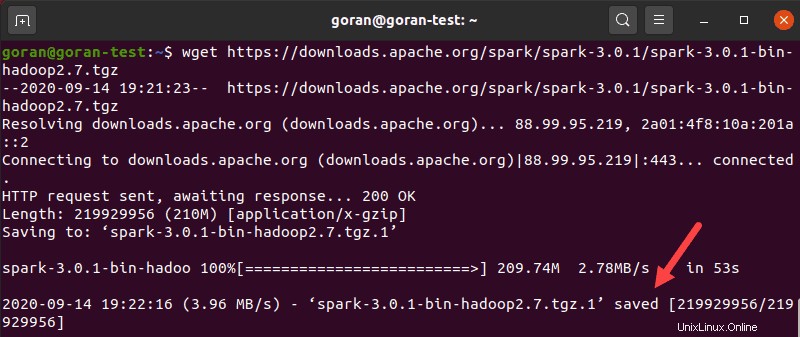
Usa il wget comando e il collegamento diretto per scaricare l'archivio Spark:
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgzAl termine del download, vedrai i salvati messaggio.
Ora estrai l'archivio salvato usando tar:
tar xvf spark-*Lascia che il processo venga completato. L'output mostra i file che vengono decompressi dall'archivio.
Infine, sposta la directory decompressa spark-3.0.1-bin-hadoop2.7 all' opt/spark directory.
Usa il mv comando per farlo:
sudo mv spark-3.0.1-bin-hadoop2.7 /opt/sparkIl terminale non restituisce alcuna risposta se sposta correttamente la directory. Se digiti male il nome, riceverai un messaggio simile a:
mv: cannot stat 'spark-3.0.1-bin-hadoop2.7': No such file or directory.Configura l'ambiente Spark
Prima di avviare un server master, è necessario configurare le variabili di ambiente. Ci sono alcuni percorsi home di Spark che devi aggiungere al profilo utente.
Usa l'echo comando per aggiungere queste tre righe a .profile :
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profilePuoi anche aggiungere i percorsi di esportazione modificando il .profile file nell'editor di tua scelta, come nano o vim.
Ad esempio, per utilizzare nano, inserisci:
nano .profileQuando il profilo viene caricato, scorri fino alla fine del file.
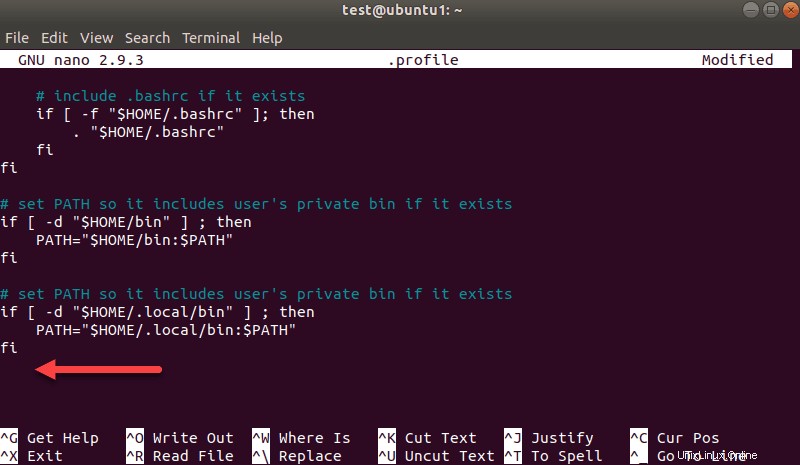
Quindi, aggiungi queste tre righe:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3Esci e salva le modifiche quando richiesto.
Quando hai finito di aggiungere i percorsi, carica il .profile file nella riga di comando digitando:
source ~/.profileAvvia Spark Master Server autonomo
Ora che hai completato la configurazione del tuo ambiente per Spark, puoi avviare un server master.
Nel terminale, digita:
start-master.shPer visualizzare l'interfaccia utente di Spark Web, apri un browser Web e inserisci l'indirizzo IP dell'host locale sulla porta 8080.
http://127.0.0.1:8080/La pagina mostra il tuo URL Spark , informazioni sullo stato dei lavoratori, utilizzo delle risorse hardware e così via
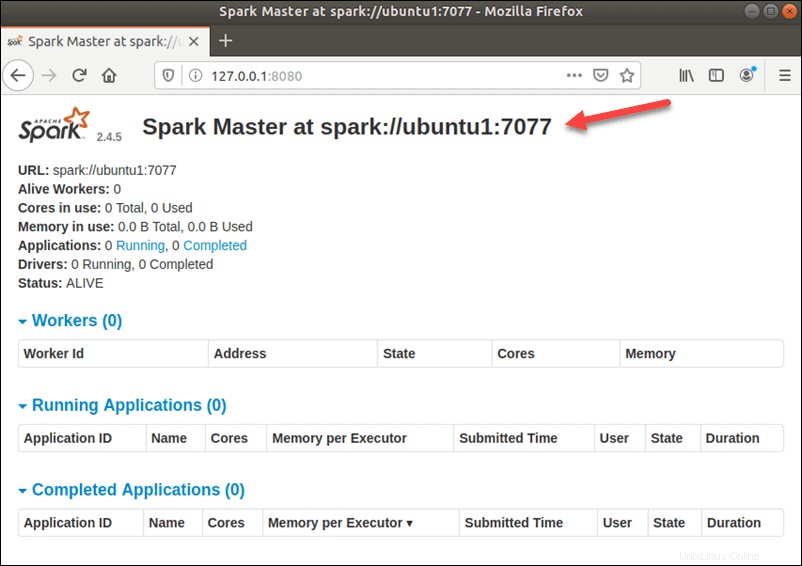
L'URL di Spark Master è il nome del tuo dispositivo sulla porta 8080. Nel nostro caso, questo è ubuntu1:8080 . Quindi, ci sono tre modi possibili per caricare l'interfaccia utente Web di Spark Master:
- 127.0.0.1:8080
- host locale:8080
- deviceName :8080
Avvia Spark Slave Server (avvia un processo di lavoro)
In questa configurazione standalone a server singolo, avvieremo un server slave insieme al server master.
Per farlo, esegui il seguente comando in questo formato:
start-slave.sh spark://master:port
Il master nel comando può essere un IP o un nome host.
Nel nostro caso è ubuntu1 :
start-slave.sh spark://ubuntu1:7077
Ora che un lavoratore è attivo e funzionante, se ricarichi l'interfaccia utente Web di Spark Master, dovresti vederlo nell'elenco:
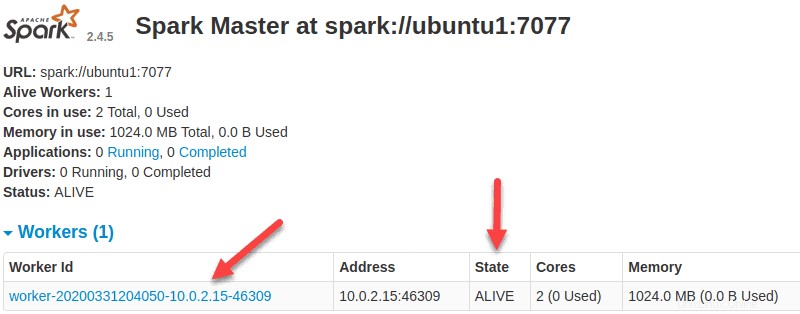
Specifica l'allocazione delle risorse per i lavoratori
L'impostazione predefinita all'avvio di un lavoratore su una macchina prevede l'utilizzo di tutti i core CPU disponibili. Puoi specificare il numero di core passando il -c segnala a start-slave comando.
Ad esempio, per avviare un lavoratore e assegnare solo un core CPU ad esso, inserisci questo comando:
start-slave.sh -c 1 spark://ubuntu1:7077Ricarica l'interfaccia utente Web di Spark Master per confermare la configurazione del lavoratore.

Allo stesso modo, puoi assegnare una quantità specifica di memoria quando avvii un lavoratore. L'impostazione predefinita prevede l'utilizzo della quantità di RAM disponibile sulla macchina, meno 1 GB.
Per avviare un lavoratore e assegnargli una specifica quantità di memoria, aggiungi il -m opzione e un numero. Per i gigabyte, usa G e per i megabyte, usa M .
Ad esempio, per avviare un lavoratore con 512 MB di memoria, inserisci questo comando:
start-slave.sh -m 512M spark://ubuntu1:7077Ricarica l'interfaccia utente Web Spark Master per visualizzare lo stato del lavoratore e confermare la configurazione.

Test Spark Shell
Dopo aver terminato la configurazione e avviato il server master e slave, verifica se la shell Spark funziona.
Carica la shell inserendo:
spark-shellDovresti ottenere una schermata con notifiche e informazioni su Spark. Scala è l'interfaccia predefinita, in modo che la shell venga caricata quando esegui spark-shell .
La fine dell'output è simile a questa per la versione che stiamo utilizzando al momento della stesura di questa guida:
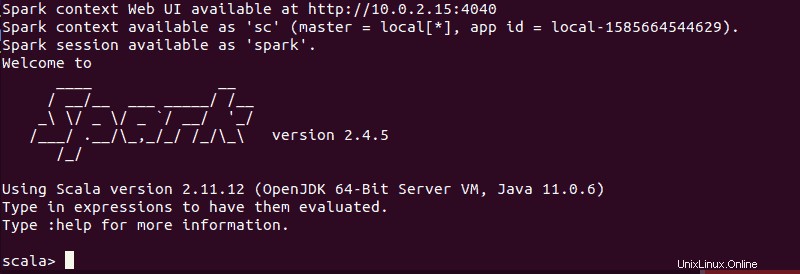
Digita :q e premi Invio per uscire da Scala.
Testa Python in Spark
Se non vuoi usare l'interfaccia predefinita di Scala, puoi passare a Python.
Assicurati di uscire da Scala e quindi di eseguire questo comando:
pysparkL'output risultante è simile al precedente. Verso il basso, vedrai la versione di Python.
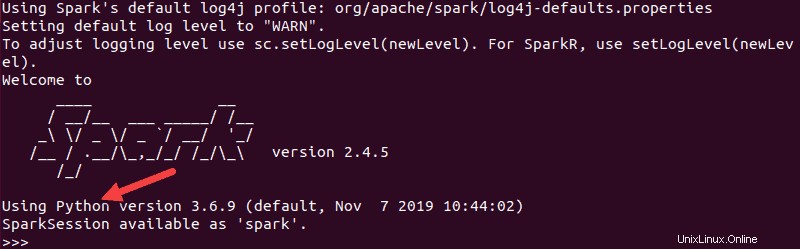
Per uscire da questa shell, digita quit() e premi Invio .
Comandi di base per avviare e arrestare Master Server e Workers
Di seguito sono riportati i comandi di base per avviare e arrestare il server master e i worker Apache Spark. Poiché questa configurazione è solo per una macchina, gli script che esegui vengono impostati per impostazione predefinita su localhost.
Per iniziare un maestro server istanza sulla macchina corrente, esegui il comando che abbiamo usato in precedenza nella guida:
start-master.shPer fermare il maestro istanza avviata eseguendo lo script sopra, esegui:
stop-master.shPer fermare un lavoratore in corsa processo, inserisci questo comando:
stop-slave.shLa pagina Spark Master, in questo caso, mostra lo stato del lavoratore come DEAD.

Puoi avviare sia il master che il server istanze utilizzando il comando start-all:
start-all.shAllo stesso modo, puoi interrompere tutte le istanze utilizzando il seguente comando:
stop-all.sh