Introduzione
I database sono una raccolta organizzata di record di dati correlati. I sistemi di gestione del database gestiscono e manipolano le informazioni all'interno di un database.
Esistono molti approcci diversi per archiviare e modellare i dati, risultando in vari tipi di database.
Questo articolo fornisce una panoramica approfondita dei diversi tipi di database disponibili.

Tipi di database
Esistono molti approcci diversi per analizzare i diversi tipi di database disponibili. La tabella seguente fornisce una panoramica generale delle varie tipologie attualmente disponibili:
| Basato su | Tipi di database |
|---|---|
| Modello | Relazionale Non relazionale (NoSQL) Orientato agli oggetti |
| Posizione | Centralizzato Distribuito |
| Progettazione | Operativo (OLTP) Analitica (OLAP) |
| Hosting | On-premise Nuvola |
| Elaborazione Potere | Personale Commerciale |
I vari tipi di database si combinano per creare un ambiente specifico. Ad esempio, un database commerciale distribuito non relazionale descrive rispettivamente il modello, l'ubicazione e l'elaborazione del database.
Tipi di modello di database
I tre tipi di database generali basati sul modello sono:
1. Banca dati relazionale
2. Database non relazionale (NoSQL)
3. Database orientato agli oggetti
La differenza tra i modelli è il modo in cui le informazioni appaiono all'interno del database. Di conseguenza, ogni tipo di modello ha un diverso sistema di gestione e relazioni di dati.
Database relazionale
Il database relazionale modello è il tipo di database più utilizzato e più vecchio. I tre componenti critici di un database relazionale sono:
- Tabelle . Un tipo di entità con relazioni.
- Righe . Record o istanze di un tipo di entità.
- Colonne . Attributi di valore delle istanze.
Un database relazionale fornisce un insieme di righe di dati in risposta a una query . Un linguaggio di query, più comunemente il linguaggio di query strutturato o SQL , aiuta a creare queste visualizzazioni di dati.
Funzionalità del database relazionale
Le caratteristiche principali di un database relazionale sono:
- Conforme agli ACID . Il database riqualifica l'integrità durante l'esecuzione delle transazioni.
- Gamma di tipi di dati . Fornisce la capacità di archiviare qualsiasi dato e di eseguire query complesse.
- Collaborativo . Più utenti possono accedere al database e lavorare allo stesso progetto.
- Protetto . L'accesso è limitato o limitato tramite i permessi dell'utente.
- Stabile . I database relazionali sono ben conosciuti e documentati.
A cosa servono i database relazionali?
I database relazionali sono il tipo di database più implementato. Esistono molti casi d'uso, alcuni dei quali includono:
- Sistemi di transazione online . Il database supporta molti utenti e le frequenti query necessarie nelle transazioni online.
- IoT . I database relazionali sono leggeri e dispongono della potenza di elaborazione necessaria per l'edge computing.
- Data warehouse . Il componente critico dell'architettura del data warehouse è lo storage. I database relazionali sono facilmente integrabili e ottimizzati per query massicce da più origini.
Banca dati relazionali più popolari
Esistono innumerevoli database commerciali e open source. I primi dieci database relazionali più popolari sono:
1. Oracolo
2. MySQL
3. Server Microsoft SQL
4. PostgreSQL
5. IBM Db2
6. SQLite
7. Microsoft Access
8. MariaDB
9. Alveare
10. Database SQL di Microsoft Azure
Database non relazionale (database NoSQL)
Un database non relazionale , o NoSQL ("Non solo SQL"), è un tipo di database che modella e archivia i dati in modo diverso dai database relazionali. Invece delle tabelle, i database non relazionali modellano le relazioni tra i dati in modo alternativo.
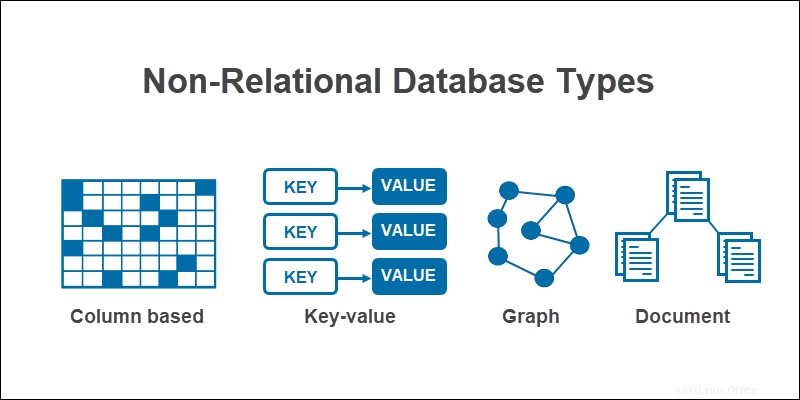
I 4 tipi di database NoSQL sono:
- Documento
- Valore-chiave
- Basato su colonna
- Grafico
Funzionalità del database non relazionali
Le caratteristiche principali dei database non relazionali sono:
- Flessibile . Gestire dati strutturati, semi-strutturati e non strutturati è un gioco da ragazzi con i tipi di database non relazionali.
- Scalabile e reattivo . L'enorme spazio di archiviazione dei dati si adatta bene ai server on-demand e fornisce risposte rapide alle query.
- Zero tempi di inattività. Elevata disponibilità per tempi di inattività minimi grazie alla replica dei dati quasi in tempo reale.
- Compatibile con il cloud . La scalabilità di un'architettura di cloud computing si integra perfettamente con i database non relazionali.
- Strutture di dati multiple . Sono disponibili diversi tipi di informazioni, nonché formati di database multimodello.
A cosa servono i database non relazionali?
I database non relazionali funzionano al meglio con strutture di dati variabili e enormi quantità di dati. Alcuni casi d'uso includono:
- Sistemi in tempo reale . Un database non relazionale combina i sistemi di database operativi e analitici in uno solo. Sia che si inseriscano dati operativi in Hadoop o si forniscano risultati di analisi da Hadoop, i database non relazionali forniscono un'esperienza agile in tempo reale.
- Esperienza personalizzata . Il ridimensionamento elastico accoglie le enormi quantità di dati necessari per qualsiasi esperienza personalizzata.
- Rilevamento di frodi . Prestazioni elevate sono vitali nel rilevamento delle frodi. I database non relazionali sono reattivi e soddisfano in modo affidabile i requisiti di bassa latenza dei sistemi finanziari.
Banca dati non relazionali più popolari
I dieci database non relazionali più popolari sono:
1. MongoDB
2. Redis
3. Cassandra
4. Base H
5. Neo4j
6. Oracle NoSQL
7. RavenDB
8. Riak
9. OrientDB
10. Divano DB
Database oggetti
Un database di oggetti allo stesso modo rappresenta i dati in oggetti nella programmazione orientata agli oggetti. I componenti critici di un database orientato agli oggetti sono:
- Oggetti . Gli elementi costitutivi di base per la memorizzazione delle informazioni.
- Classi. Lo schema o il progetto per un oggetto.
- Metodi . Comportamenti strutturati di una classe.
- Puntatori. Accedi agli elementi di un database e stabilisci relazioni tra gli oggetti.
I database di oggetti combinano concetti di programmazione orientata agli oggetti con funzionalità di database.
Funzionalità del database degli oggetti
Le caratteristiche principali dei database a oggetti sono:
- Transazioni ACIDO . Tutte le transazioni sono complete senza modifiche in conflitto dovute alla conformità ACID.
- Persistenza trasparente . I database di oggetti si integrano perfettamente con i linguaggi di programmazione orientati agli oggetti.
- Tipi di dati complessi e personalizzati. Le classi definite dall'utente consentono l'esistenza di tipi di dati personalizzati e complessi.
- Accessibile. I dati sono facili da salvare e recuperare.
- Modellazione più semplice. I problemi e le informazioni del mondo reale sono più strettamente correlati agli oggetti, il che semplifica la modellazione di problemi complessi.
A cosa servono i database di oggetti?
I database di oggetti funzionano al meglio con tipi di dati complessi, in cui un'entità include un'enorme quantità di informazioni. Alcuni casi d'uso quotidiani per questo tipo di modello di database sono:
- Applicazioni ad alte prestazioni . Applicazioni in cui il recupero rapido dei dati è fondamentale per trarre vantaggio dai database di oggetti poiché i dati vengono archiviati e recuperati così come sono.
- Scopi scientifici . I dati scientifici, così come i calcoli, sono complessi. La memorizzazione di informazioni complesse e il recupero rapido trovano impiego in tutti i tipi di discipline scientifiche.
- Strutture di dati complesse . Grazie alla persistenza permanente con gli oggetti, l'archiviazione del database e l'espansione di dati complessi sono accessibili, eliminando la necessità di rielaborare il modello del database.
Banca dati di oggetti più popolari
Attualmente, i primi dieci database di oggetti più popolari sono:
1. DB4o
2. ObjectStore
3. Matisse
4. Pietra preziosa/S
5. ObjectDB
6. ObjectDatabase++
7. Obiettività/DB
8. Versante
9. Perst
10. Giada
Tipi di database in base alla posizione
I tipi di database differiscono anche in base alla posizione fisica dell'archiviazione.
I due gruppi in base alla posizione sono:
1. Banche dati centralizzate
2. Database distribuiti
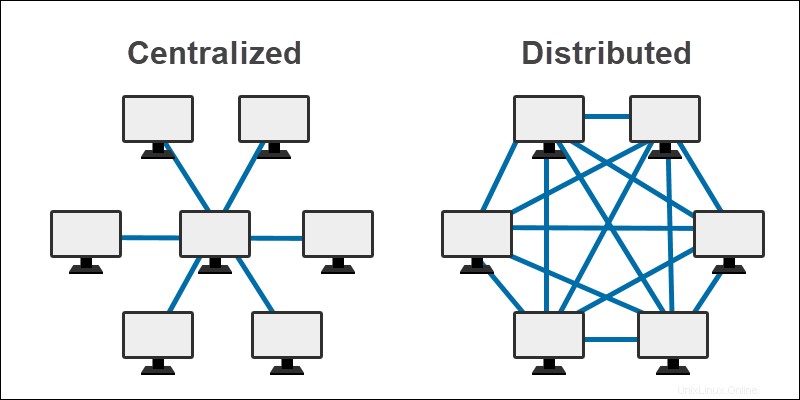
Banca dati centralizzata
Un database centralizzato viene archiviato e gestito in un'unica posizione. Le informazioni sono disponibili attraverso una rete. L'utente finale ha accesso attraverso la rete al computer centralizzato, dove risiedono le informazioni memorizzate.
Funzionalità database centralizzate
Le caratteristiche principali di un database centralizzato sono:
- Integrità dei dati . La conservazione dei dati in un'unica posizione massimizza l'integrità dei dati e riduce la ridondanza. L'accuratezza e l'affidabilità delle informazioni sono migliorate.
- Sicurezza . Un unico punto di posizione fornisce un solo punto di accesso, aumentando la sicurezza dei dati.
- Facile per l'utente finale . L'accesso ai dati, così come gli aggiornamenti, sono immediati con un database centralizzato. La progettazione di un unico database offre semplicità.
- Conveniente . La manodopera, l'alimentazione e la manutenzione sono tutti ridotti al minimo attraverso un sistema centralizzato. Il database è più facile da mantenere dal punto di vista amministrativo.
- Conservazione dei dati . Una configurazione a tolleranza d'errore tramite soluzioni di ripristino di emergenza.
A cosa servono i database centralizzati?
I vantaggi di un database centralizzato sono più evidenti con le grandi istituzioni. Alcuni casi d'uso includono:
- Gestione aziendale . Le grandi organizzazioni utilizzano database centralizzati per avere una migliore panoramica di tutte le informazioni.
- Dati governativi . I database centralizzati sono prevalenti nelle organizzazioni governative. Un punto di accesso garantisce la sicurezza dei dati.
- Scuole e università . Le istituzioni educative utilizzano database centralizzati. La manutenzione è conveniente e le informazioni rimangono accurate.
Banca dati distribuita
I database distribuiti archiviano le informazioni in diversi siti fisici. Il database risiede su più CPU in un unico sito o distribuito in varie posizioni. A causa delle connessioni tra i database distribuiti, le informazioni appaiono agli utenti finali come un unico database.
Funzionalità del database distribuito
Le caratteristiche più interessanti di un database distribuito sono:
- Indipendenza dalla posizione . La posizione fisica del database si estende su più siti.
- Elaborazione delle query distribuzione. Una query complessa si divide in più siti, che suddividono le attività tra diverse CPU, riducendo il collo di bottiglia.
- Transazioni distribuite . Più posizioni di archiviazione forniscono un metodo di ripristino distribuito. Esistono protocolli di commit in caso di numerose transazioni.
- Collegamento di rete . I database distribuiti si collegano attraverso una rete in cui la comunicazione avviene tra gli archivi e con gli utenti finali.
- Integrazione perfetta . Sebbene non siano fisicamente connesse, le parti del database distribuito si connettono a un database logico.
A cosa servono i database distribuiti?
I database distribuiti funzionano meglio in ambienti con molti settori in cui le aziende dovrebbero limitare le informazioni disponibili per ridurre la ridondanza. Alcuni esempi includono:
- Grandi aziende. La maggior parte dei settori aziendali non necessita di una panoramica completa dei dati. I database distribuiti aiutano a ridurre la ridondanza dei dati con i singoli reparti.
- Imprese globali. Grazie all'indipendenza dalla posizione, questo tipo di database si adatta bene alle aziende con più siti.
Tipi di database basati sul design
Il design dello storage dipende dall'obiettivo aziendale. Esistono due approcci principali alla progettazione di database basati sulla funzione:
1. Banca dati operativa (transazionale)
2. Banca dati analitica
Sebbene i database abbiano uno scopo diverso, incorporarli insieme crea un sistema di data warehouse.
Banca dati operativa
Un database operativo gestisce e controlla le operazioni fondamentali all'interno di un'azienda. Il database è noto come elaborazione delle transazioni online o database OLTP. I dati raccolti direttamente dalla fonte in tempo reale, fornendo una visione delle transazioni giornaliere.
Funzionalità del database operativo
I database operativi hanno le seguenti caratteristiche:
- Conforme agli ACID . Per l'organizzazione dei dati è necessario preservare l'accuratezza e l'integrità di ogni transazione.
- Elaborazione rapida . I database operativi richiedono un'elaborazione rapida a causa di migliaia di richieste simultanee.
- Piccolo spazio di archiviazione . Le informazioni transazionali vengono memorizzate solo temporaneamente. Pertanto, i database operativi fungono da trampolino di lancio prima che i dati vengano archiviati.
- Backup regolari. La raccolta e l'archiviazione dei dati richiede backup costanti, rendendo la conformità legale un fattore essenziale.
Banca dati analitica
I database analitici forniscono una vista unificata di tutti i dati disponibili all'interno di un'azienda. Una panoramica completa delle informazioni all'interno di un database è essenziale per la pianificazione, il reporting e il processo decisionale. Il database è noto come database di elaborazione analitica online (OLAP).
Funzionalità del database analitico
Le caratteristiche di un database analitico sono:
- Distribuito carico di lavoro. I dati provengono da diversi sistemi operativi distribuiti tra i nodi.
- Multidimensionale. Le informazioni aziendali acquisiscono dimensionalità attraverso l'aggregazione dei dati e query complesse tra i database.
- Rendimento delle query. La denormalizzazione dei dati migliora le prestazioni delle query per azioni che richiedono molto tempo.
- Scalabilità orizzontale. I database analitici devono essere scalabili come requisiti per la crescita di un'azienda.
Tipi di database basati sull'hosting
Ci sono più opzioni di hosting per i database. I due luoghi in cui risiede un sistema informativo sono:
1. Database locali
2. Database cloud
La notevole differenza tra le due opzioni è la disponibilità delle risorse al momento della distribuzione del database. Per ulteriori informazioni sul confronto tra i due approcci, consulta il nostro articolo:On-Premise vs. Cloud:qual è la soluzione giusta per la tua azienda?
Database locale
Un database locale risiede internamente. Tutto il software, l'infrastruttura e l'amministrazione necessari per il supporto sono locali. Con le aziende su larga scala, lo storage cresce fino a diventare un data center locale.
Funzionalità del database locale
Le caratteristiche degne di nota dei database locali sono:
- Sicurezza . Poiché l'infrastruttura è interna, i database locali sono la soluzione migliore per archiviare informazioni sensibili.
- Controllo . L'azienda ha il controllo completo sulle informazioni disponibili, fornendo un elevato livello di regolamentazione e privacy sui dati.
- Conformità . I controlli normativi, come la conformità HIPAA, richiedono la conoscenza dell'ubicazione dei dati sensibili in qualsiasi momento.
Database cloud
Un database cloud è una soluzione di hosting fornita da un provider di terze parti. La soluzione pay-as-go fornisce il database-as-a-service, evitando la necessità di allestire fisicamente un data center. L'approccio agile riduce al minimo gli investimenti iniziali necessari per acquisire spazio dati, espandendosi rapidamente man mano che sono necessarie più risorse.
Funzionalità del database cloud
Le migliori caratteristiche di un database cloud sono:
- Scalabilità . I database cloud sono flessibili. L'aumento o la diminuzione delle risorse è rapido grazie alla virtualizzazione.
- Flessibilità di gestione . Il provider gestisce questo tipo di database, che a sua volta riduce al minimo la gestione richiesta dal client. Tuttavia, ci sono anche opzioni per l'esternalizzazione della manutenzione.
- Costo . Con un database cloud, paghi solo per ciò di cui hai bisogno. Il costo dell'investimento in personale tecnico, oltre che nella manutenzione, è ridotto al minimo.
Tipi di database basati sulla potenza di elaborazione
L'elaborazione del database dipende dal modello di business. La scelta del livello sbagliato di un sistema di database influisce sul flusso di lavoro di un'organizzazione e di un team. La maggior parte dei fornitori di database offre più soluzioni per l'elaborazione di database. I due principali sono:
1. Banca dati personale
2. Banca dati commerciale
Le aziende sfruttano la potenza di entrambi a seconda del caso d'uso.
Banca dati personale
I database personali hanno accesso ed elaborazione per utente singolo su macchine di potenza medio-bassa. Le applicazioni di database più semplici traggono vantaggio da questo tipo di database a causa del basso costo e della manutenzione.
Banca dati commerciale
Un database commerciale ha più utenti con vari permessi, nonché numerose applicazioni su macchine ad alta potenza. I database commerciali ad alta disponibilità sono costosi e richiedono manutenzione e supporto costanti.