Introduzione
I framework di elaborazione dati, come Apache Hadoop e Spark, hanno alimentato lo sviluppo dei Big Data. La loro capacità di raccogliere grandi quantità di dati da diversi flussi di dati è incredibile, tuttavia, hanno bisogno di un data warehouse per analizzare, gestire e interrogare tutti i dati.
Sei interessato a saperne di più su cosa sono i data warehouse e in cosa consistono?
Questo articolo spiega l'architettura del data warehouse e il ruolo di ogni componente nel sistema.
Cos'è un Data Warehouse?
Un data warehouse (DW o DWH) è un sistema complesso che archivia i dati storici e cumulativi utilizzati per la previsione, il reporting e l'analisi dei dati. Implica la raccolta, la pulizia e la trasformazione dei dati da diversi flussi di dati e il loro caricamento in tabelle fattuali/dimensionali.
Un data warehouse rappresenta una struttura di dati orientata al soggetto, integrata, variabile nel tempo e non volatile.
Concentrandosi sull'argomento piuttosto che sulle operazioni, il DWH integra i dati provenienti da più fonti fornendo all'utente un'unica fonte di informazioni in un formato coerente. Poiché non è volatile, registra tutte le modifiche ai dati come nuove voci senza cancellare il suo stato precedente. Questa funzione è strettamente correlata alla variazione temporale, in quanto mantiene un registro dei dati storici, consentendoti di esaminare le modifiche nel tempo.
Tutte queste proprietà aiutano le aziende a creare report analitici necessari per studiare i cambiamenti e le tendenze.
Architettura del data warehouse
Esistono tre modi per costruire un sistema di data warehouse. Questi approcci sono classificati in base al numero di livelli nell'architettura. Pertanto, puoi avere un:
- Architettura a livello singolo
- Architettura a due livelli
- Architettura a tre livelli
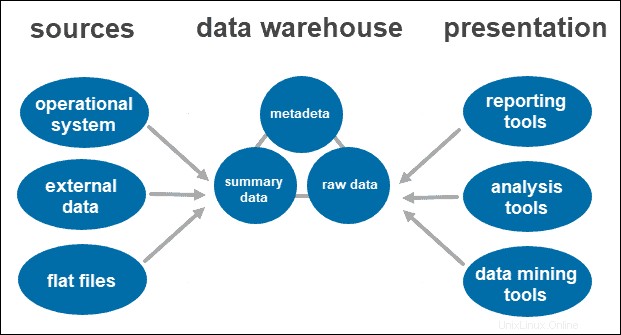
Architettura di data warehouse a livello singolo
L'architettura a livello singolo non è un approccio praticato di frequente. L'obiettivo principale di avere una tale architettura è rimuovere la ridondanza riducendo al minimo la quantità di dati archiviati.
Il suo principale svantaggio è che non ha un componente che separa l'elaborazione analitica e transazionale.
Architettura di data warehouse a due livelli
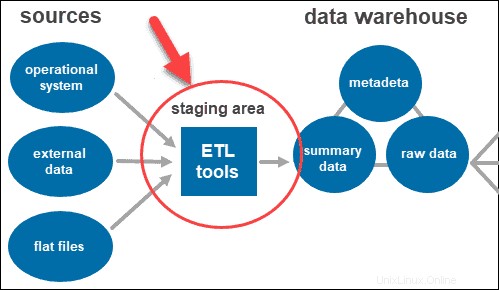
Un'architettura a due livelli include un'area di gestione temporanea per tutte le origini dati, prima del livello di data warehouse. Aggiungendo un'area di staging tra le origini e il repository di archiviazione, ti assicuri che tutti i dati caricati nel warehouse siano puliti e nel formato appropriato.
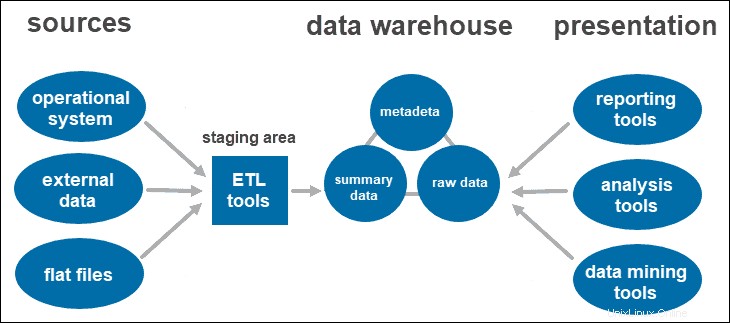
Questo approccio ha alcune limitazioni di rete. Inoltre, non puoi espanderlo per supportare un numero maggiore di utenti.
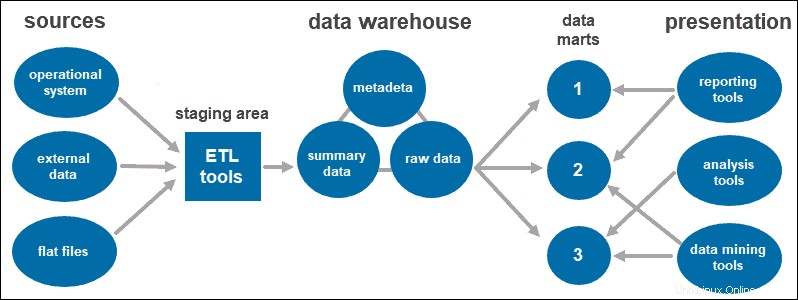
Architettura di data warehouse a tre livelli
L'approccio a tre livelli è l'architettura più utilizzata per i sistemi di data warehouse.
Essenzialmente, si compone di tre livelli:
- Il livello inferiore è il database del magazzino, dove vengono caricati i dati ripuliti e trasformati.
- Il livello intermedio è il livello dell'applicazione che fornisce una vista astratta del database. Dispone i dati per renderli più adatti all'analisi. Questo viene fatto con un server OLAP, implementato utilizzando il modello ROLAP o MOLAP.
- Il livello più alto è il luogo in cui l'utente accede e interagisce con i dati. Rappresenta il livello client front-end. Puoi utilizzare strumenti di reportistica, query, analisi o data mining.
Componenti di Data Warehouse
Dalle architetture descritte sopra, noti che alcuni componenti si sovrappongono, mentre altri sono unici per il numero di livelli.
Di seguito troverai alcuni dei più importanti componenti del data warehouse e i loro ruoli nel sistema.
Strumenti ETL
ETL sta per Estratto , Trasforma e Carica . Il livello di staging utilizza strumenti ETL per estrarre i dati necessari dai vari formati e ne controlla la qualità prima di caricarli nel data warehouse.
I dati provenienti dal livello di origine dati possono venire in una varietà di formati. Prima di unire tutti i dati raccolti da più fonti in un unico database, il sistema deve pulire e organizzare le informazioni.
Il database
Il componente più cruciale e il cuore di ogni architettura è il database. Il magazzino è il luogo in cui i dati vengono archiviati e vi si accede.
Quando crei il sistema di data warehouse, devi prima decidere quale tipo di database desideri utilizzare.
Sono disponibili quattro tipi di database tra cui scegliere:
- Banche dati relazionali (database centrati sulle righe).
- Banche dati analitiche (sviluppato per sostenere e gestire l'analisi).
- Applicazioni di data warehouse (software per la gestione dei dati e hardware per la memorizzazione dei dati offerti da rivenditori di terze parti).
- Database basati su cloud (ospitati sul cloud).
Dati
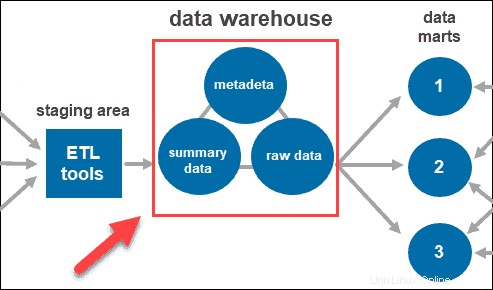
Una volta che il sistema pulisce e organizza i dati, li archivia nel data warehouse. Il data warehouse rappresenta il repository centrale che archivia metadati, dati di riepilogo e dati grezzi provenienti da ciascuna origine.
- Metadati è l'informazione che definisce i dati. Il suo ruolo principale è semplificare il lavoro con le istanze di dati. Consente agli analisti di dati di classificare, individuare e indirizzare le query ai dati richiesti.
- Dati di riepilogo è generato dal responsabile del magazzino. Si aggiorna quando nuovi dati vengono caricati nel magazzino. Questo componente può includere dati leggermente o altamente riepilogati. Il suo ruolo principale è accelerare le prestazioni delle query.
- Dati grezzi è il caricamento effettivo dei dati nel repository, che non è stato elaborato. Avere i dati nella loro forma grezza li rende accessibili per ulteriori elaborazioni e analisi.
Accesso agli strumenti
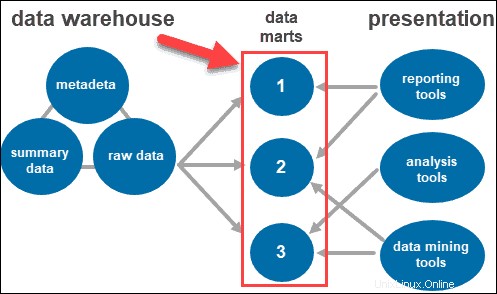
Gli utenti interagiscono con le informazioni raccolte attraverso diversi strumenti e tecnologie. Possono analizzare i dati, raccogliere informazioni dettagliate e creare report.
Alcuni degli strumenti utilizzati includono:
- Strumenti di reporting. Svolgono un ruolo cruciale nel capire come sta andando la tua attività e cosa dovrebbe essere fatto dopo. Gli strumenti di reporting includono visualizzazioni come grafici e diagrammi che mostrano come i dati cambiano nel tempo.
- Strumenti OLAP. Strumenti di elaborazione analitica online che consentono agli utenti di analizzare dati multidimensionali da più prospettive. Questi strumenti forniscono un'elaborazione rapida e analisi preziose. Estraggono i dati da numerosi insiemi di dati relazionali e li riorganizzano in un formato multidimensionale.
- Strumenti di data mining. Esaminare i set di dati per trovare i modelli all'interno del magazzino e la correlazione tra di essi. Il data mining aiuta anche a stabilire relazioni durante l'analisi di dati multidimensionali.
Data mart
I data mart consentono di avere più gruppi all'interno del sistema segmentando i dati nel magazzino in categorie. Suddivide i dati, producendoli per un particolare gruppo di utenti.
Ad esempio, puoi utilizzare i data mart per classificare le informazioni in base ai dipartimenti all'interno dell'azienda.
Best practice per il data warehouse
La progettazione di un data warehouse si basa sulla comprensione della logica aziendale del singolo caso d'uso.
I requisiti variano, ma ci sono best practice per il data warehouse che dovresti seguire:
- Crea un modello di dati. Inizia identificando la logica aziendale dell'organizzazione. Comprendi quali dati sono vitali per l'organizzazione e come fluiranno attraverso il data warehouse.
- Optare per un noto standard di architettura del data warehouse. Un modello di dati fornisce un framework e una serie di best practice da seguire durante la progettazione dell'architettura o la risoluzione dei problemi. Gli standard di architettura più diffusi includono 3NF, modellazione di Data Vault e schema a stella.
- Crea un diagramma di flusso di dati. Documentare come i dati fluiscono attraverso il sistema. Scopri come si collega ai tuoi requisiti e alla logica aziendale.
- Avere un'unica fonte di verità. Quando si ha a che fare con così tanti dati, un'organizzazione deve avere un'unica fonte di verità. Consolida i dati in un unico repository.
- Utilizza l'automazione. Gli strumenti di automazione aiutano quando si tratta di grandi quantità di dati.
- Consenti la condivisione dei metadati. Progetta un'architettura che faciliti la condivisione dei metadati tra i componenti del data warehouse.
- Applica gli standard di codifica. Gli standard di codifica garantiscono l'efficienza del sistema.