Introduzione
Kubernetes offre uno straordinario livello di flessibilità per l'orchestrazione di un ampio cluster di container distribuiti.
Il gran numero di funzioni e opzioni disponibili può rappresentare una sfida. L'applicazione delle migliori pratiche ti aiuta a evitare potenziali ostacoli e a creare un ambiente sicuro ed efficiente fin dall'inizio.
Utilizza le best practice di Kubernetes descritte per creare container ottimizzati, semplificare le implementazioni, amministrare servizi affidabili e gestire un cluster completo.

Proteggi e ottimizza i contenitori
I contenitori forniscono un isolamento molto inferiore rispetto alle macchine virtuali. Dovresti sempre verificare le immagini del contenitore e mantenere uno stretto controllo sulle autorizzazioni degli utenti.
L'utilizzo di immagini di contenitori di piccole dimensioni aumenta l'efficienza, conserva le risorse e riduce la superficie di attacco per potenziali aggressori.
Utilizza solo immagini container attendibili
Le immagini dei container già pronte sono altamente accessibili ed eccezionalmente utili. Tuttavia, le immagini pubbliche possono rapidamente diventare obsolete, contenere exploit, bug o persino software dannoso che si diffonde rapidamente in un cluster Kubernetes.
Utilizza solo immagini da repository attendibili e scansiona sempre le immagini per potenziali vulnerabilità. Numerosi strumenti online, come Anchore o Clair, forniscono una rapida analisi statica delle immagini dei container e ti informano su potenziali minacce e problemi. Dedica qualche minuto alla scansione delle immagini del contenitore prima di distribuirle ed evita conseguenze potenzialmente disastrose.
Utenti non root e filesystem di sola lettura
Modifica il contesto di sicurezza integrato per forzare l'esecuzione di tutti i contenitori solo con utenti non root e con un filesystem di sola lettura.
Evita di eseguire i container come utente root. Una violazione della sicurezza può degenerare rapidamente se un utente può concedersi autorizzazioni aggiuntive.

Se un file system è impostato in sola lettura, ci sono poche possibilità di manomettere il contenuto del contenitore. Invece di modificare i file di sistema, è necessario rimuovere l'intero contenitore e metterne uno nuovo al suo posto.
Crea immagini piccole e stratificate
Le immagini di piccole dimensioni velocizzano le tue build e richiedono meno spazio di archiviazione. La stratificazione efficiente di un'immagine può ridurre notevolmente le dimensioni dell'immagine. Prova a creare le tue immagini da zero per ottenere risultati ottimali.
Usa più istruzioni FROM in un singolo Dockerfile se hai bisogno di molti componenti diversi. Questa funzione crea sezioni, ciascuna delle quali fa riferimento a un'immagine di base diversa. L'immagine finale non memorizza più i livelli precedenti, ma solo i componenti necessari per ciascuno, rendendo il contenitore Docker molto più sottile.
Ogni livello viene estratto in base a FROM comando situato nel contenitore distribuito.
Limita l'accesso degli utenti con RBAC
Il controllo degli accessi in base al ruolo (RBAC) garantisce che nessun utente disponga di più autorizzazioni di quelle necessarie per completare le proprie attività. Puoi abilitare RBAC aggiungendo il seguente flag all'avvio del server API:
--authorization-mode=RBACRBAC utilizza rbac.authorization.k8s.io Gruppo API per guidare le decisioni di autorizzazione tramite l'API Kubernetes.
Registri Stdout e Stderr
È prassi comune inviare i log dell'applicazione allo stdout (output standard) e i log degli errori in stderr flusso (errore standard). Quando un'app scrive su stdout e stderr, un motore contenitore, come Docker, reindirizza e archivia i record in un file JSON.
I contenitori, i pod e i nodi Kubernetes sono entità dinamiche. I log devono essere coerenti e perennemente disponibili. Si consiglia pertanto di conservare i log a livello di cluster in un sistema di archiviazione back-end separato.
Kubernetes può essere integrato con un'ampia gamma di soluzioni di registrazione esistenti, come ELK Stack.
Semplifica le implementazioni
Una distribuzione Kubernetes stabilisce un modello che garantisce che i pod siano attivi e funzionanti, aggiornati regolarmente o ripristinati come definito dall'utente.
L'utilizzo di etichette trasparenti, flag, contenitori collegati e DaemonSet può darti un controllo dettagliato sul processo di distribuzione.
Utilizzo del flag record
Quando aggiungi il --record flag, il kubectl eseguito il comando viene memorizzato come annotazione. Esaminando la cronologia di implementazione della distribuzione, puoi facilmente tenere traccia degli aggiornamenti in CHANGE-CAUSE colonna.
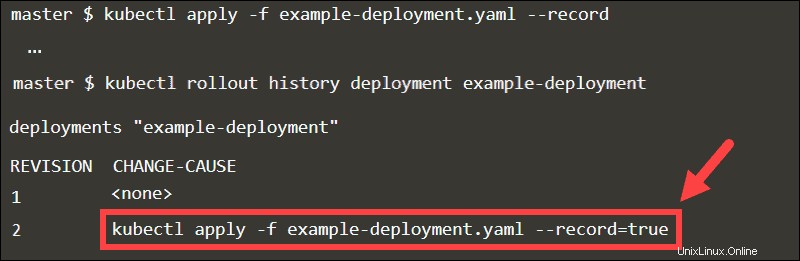
Torna a qualsiasi revisione dichiarando il numero di revisione nel comando annulla.
kubectl rollout undo deployment example-deployment --to-revision=1
Senza il --record flag, sarebbe difficile identificare la revisione specifica.
Etichette descrittive
Prova a utilizzare quante più etichette descrittive possibile. Le etichette sono coppie chiave:valore che consentono agli utenti di raggruppare e organizzare i pod in sottoinsiemi significativi. La maggior parte delle funzionalità, dei plug-in e delle soluzioni di terze parti necessitano di etichette per poter identificare i pod e controllare i processi automatizzati.
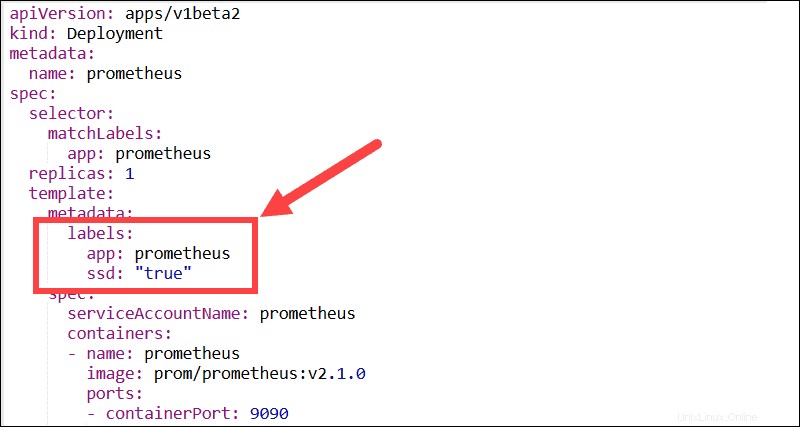
Ad esempio, i DaemonSet di Kubernetes dipendono da etichette e selettori di nodi per gestire la distribuzione dei pod all'interno di un cluster.
Crea più processi all'interno di un pod
Usa le capacità di collegamento dei container di Kubernetes invece di cercare di risolvere tutti i problemi all'interno di un container. Distribuisce in modo efficace più container su un singolo pod Kubernetes. Un buon esempio è l'esternalizzazione delle funzionalità di sicurezza a un proxy sidecar contenitore.
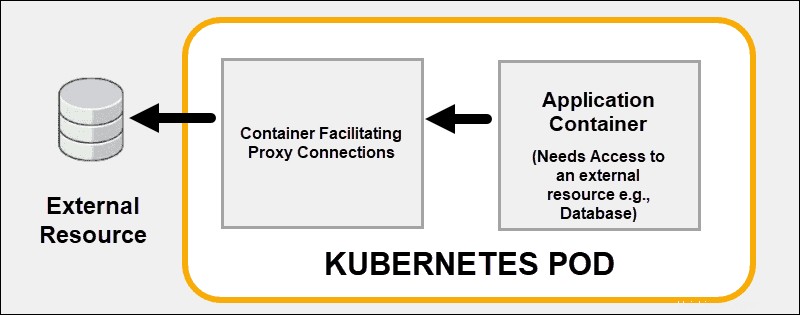
Un container accoppiato può supportare o migliorare le funzionalità principali del container principale o aiutare il container principale ad adattarsi al suo ambiente di distribuzione.
Usa i contenitori Init
Uno o più contenitori init in genere eseguono attività di utilità o controlli di sicurezza che non si desidera includere nel contenitore dell'applicazione principale. Puoi utilizzare i container init per assicurarti che un servizio sia pronto prima di avviare il container principale del pod.
Ciascun contenitore init deve essere eseguito correttamente fino al completamento prima dell'avvio del contenitore init successivo. I contenitori Init possono ritardare l'inizio del contenitore principale del pod fino a quando non viene soddisfatta una precondizione. Senza questa precondizione, Kubernetes riavvia il pod. Una volta soddisfatto il prerequisito, il contenitore init termina automaticamente e consente l'avvio del contenitore principale.
Evita di usare il tag più recente
Astenersi dall'utilizzare nessun tag o il :latest tag durante la distribuzione di contenitori in un ambiente di produzione. Il tag più recente rende difficile determinare quale versione dell'immagine è in esecuzione.
Un modo efficace per assicurarsi che il contenitore utilizzi sempre la stessa versione dell'immagine consiste nell'utilizzare il digest univoco dell'immagine come tag. In questo esempio, una versione dell'immagine Redis viene distribuita utilizzando il relativo digest univoco:
[email protected]:675hgjfn48324cf93ffg43269ee113168c194352dde3eds876677c5cbKubernetes non aggiorna automaticamente la versione dell'immagine a meno che tu non modifichi il valore digest.
Impostazione di sonde di disponibilità e vivacità
Vivacità e sonda di prontezza aiuta Kubernetes a monitorare e interpretare lo stato delle tue applicazioni. Se definisci un controllo di attività e un processo soddisfa i requisiti, Kubernetes interrompe il container e avvia una nuova istanza che ne sostituisca.
Le sonde di prontezza conducono audit a livello di pod e valutano se un pod può accettare traffico. Se un pod non risponde, un probe di disponibilità attiva un processo per riavviare il pod.
La documentazione per la configurazione delle sonde di disponibilità e vitalità è disponibile sul sito Web ufficiale di Kubernetes.
Prova diversi tipi di servizi
Imparando a utilizzare diversi tipi di servizio, puoi amministrare in modo efficace il traffico pod interno ed esterno. Il tuo obiettivo è creare un ambiente di rete stabile gestendo endpoint affidabili come IP, porte e DNS.
Porte statiche con NodePort
Esponi i pod agli utenti esterni impostando il tipo di servizio su NodePort. Se specifichi un valore in nodePort campo, Kubernetes riserva quel numero di porta su tutti i nodi e inoltra tutto il traffico in entrata destinato ai pod che fanno parte del servizio. Il servizio è accessibile utilizzando sia l'IP del cluster interno che l'IP del nodo con la porta riservata.

Gli utenti possono contattare il servizio NodePort dall'esterno del cluster richiedendo:
NodeIP:NodePortUtilizzare sempre un numero di porta compreso nell'intervallo configurato per NodePort (30000-32767). Se una transazione API non riesce, dovresti risolvere possibili conflitti di porte.
Ingress vs LoadBalancer
Il tipo LoadBalancer espone i servizi esternamente utilizzando il servizio di bilanciamento del carico del tuo provider. Ogni servizio che esponi usando il tipo LoadBalancer riceve il suo IP. Se disponi di molti servizi, potresti riscontrare costi aggiuntivi non pianificati in base al numero di servizi esposti.
Un requisito di configurazione standard consiste nel fornire a un controller di ingresso un indirizzo IP pubblico statico esistente. L'indirizzo IP pubblico statico rimane se il controller di ingresso viene eliminato. Questo approccio ti consente di utilizzare i record DNS correnti e le configurazioni di rete in modo coerente durante tutto il ciclo di vita delle tue applicazioni.
Mappa i servizi esterni a un DNS
Il tipo ExternalName non esegue il mapping dei servizi a un selettore, ma utilizza invece un nome DNS. Utilizza il nome esterno parametro per mappare i servizi utilizzando un record CNAME. Un record CNAME è un nome di dominio completo e non un IP numerico.
I client che si connettono al servizio ignoreranno il proxy del servizio e si connetteranno direttamente alla risorsa esterna. In questo esempio, il servizio pnap è mappato su admin.phoenixnap.com risorsa esterna.

Accesso al servizio pnap funziona allo stesso modo di altri servizi. La differenza cruciale è che il reindirizzamento ora avviene a livello di DNS.
Progettazione dell'applicazione
La distribuzione automatizzata dei container con Kubernetes garantisce che la maggior parte delle operazioni ora venga eseguita senza l'input umano diretto. Progetta le tue applicazioni e le immagini del contenitore in modo che siano intercambiabili e non richiedano una microgestione costante.
Concentrati sui servizi individuali
Prova a dividere la tua applicazione in più servizi ed evita di raggruppare troppe funzionalità in un unico contenitore. È molto più facile ridimensionare le app orizzontalmente e riutilizzare i contenitori se si concentrano sull'esecuzione di una funzione.
Quando crei le tue applicazioni, supponi che i tuoi container siano entità a breve termine che verranno arrestate e riavviate regolarmente.
Utilizza le mappe timone
Helm, il gestore dei pacchetti dell'applicazione Kubernetes, può semplificare il processo di installazione e distribuire le risorse in tutto il cluster molto rapidamente. I pacchetti dell'applicazione Helm sono chiamati Grafici.
Applicazioni come MySQL, PostgreSQL, MongoDB, Redis, WordPress sono soluzioni molto richieste. Invece di creare e modificare diversi file di configurazione complessi, puoi distribuire i grafici Helm prontamente disponibili.
Utilizza il comando seguente per creare le distribuzioni, i servizi, le richieste di volumi persistenti e i segreti necessari per eseguire Kafka Manager sul tuo cluster.
helm install --name my-messenger stable/kafka-managerNon è più necessario analizzare componenti specifici e imparare a configurarli per eseguire correttamente Kafka.
Utilizza Node e Pod Affinity
La funzione di affinità viene utilizzata per definire sia l'affinità del nodo che l'affinità tra i pod. L'affinità del nodo consente di specificare i nodi su cui un pod può essere pianificato utilizzando le etichette dei nodi esistenti.
- requiredDuringSchedulingIgnoredDuringExecution – Stabilisce vincoli obbligatori che devono essere soddisfatti per la pianificazione di un pod su un nodo.
- preferredDuringSchedulingIgnoredDuringExecution – Definisce le preferenze a cui uno scheduler dà la priorità ma non garantisce.
Se le etichette del nodo cambiano in fase di esecuzione e le regole di affinità del pod non vengono più soddisfatte, il pod non viene rimosso dal nodo. Il nodeSelector parametro limita i pod a nodi specifici utilizzando le etichette. In questo esempio, il pod Grafana verrà programmato solo su nodi che hanno il ssd etichetta.
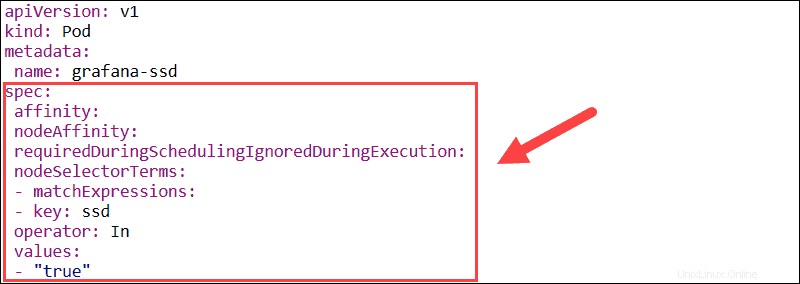
La funzione di affinità/anti-affinità pod espande i tipi di vincoli che puoi esprimere. Invece di usare le etichette dei nodi, puoi usare le etichette dei pod esistenti per delineare i nodi su cui un pod può essere pianificato. Questa funzione ti consente di impostare regole in modo che i singoli pod vengano programmati in base alle etichette di altri pod.
Contaminazioni e tolleranze dei nodi
Kubernetes prova automaticamente a distribuire i pod nelle posizioni con il carico di lavoro minimo. L'affinità di nodi e pod consente di controllare a quale nodo viene distribuito un pod. I contaminanti possono impedire la distribuzione di pod su nodi specifici senza alterare i pod esistenti. I pod che desideri distribuire su un nodo contaminato devono attivare l'utilizzo del nodo.
- Macchie – Impedisci la pianificazione di nuovi pod sui nodi, definisci le preferenze dei nodi e rimuovi i pod esistenti da un nodo.
- Tolleranze – Abilita la pianificazione dei pod solo su nodi con contaminazioni esistenti e corrispondenti.
I contaminanti e le tolleranze producono risultati ottimali se usati insieme per garantire che i pod vengano programmati sui nodi appropriati.
Raggruppare le risorse con gli spazi dei nomi
Usa gli spazi dei nomi Kubernetes per partizionare cluster di grandi dimensioni in gruppi più piccoli e facilmente identificabili. Gli spazi dei nomi consentono di creare ambienti di test, QA, produzione o sviluppo separati e allocare risorse adeguate all'interno di uno spazio dei nomi univoco. I nomi delle risorse Kubernetes devono essere univoci solo all'interno di un singolo spazio dei nomi. Spazi dei nomi diversi possono avere risorse con lo stesso nome.
Se più utenti hanno accesso allo stesso cluster, puoi limitare gli utenti e consentire loro di agire entro i confini di uno specifico spazio dei nomi. Separare gli utenti è un ottimo modo per delimitare le risorse ed evitare potenziali conflitti di denominazione o versione.
Gli spazi dei nomi sono risorse Kubernetes e sono eccezionalmente facili da creare. Crea un file YAML che definisce il nome dello spazio dei nomi e usa kubectl per inviarlo al server API Kubernetes. Successivamente puoi utilizzare lo spazio dei nomi per amministrare la distribuzione di risorse aggiuntive.