In questa serie di articoli tratteremo l'intero edificio del cluster Cloudera Hadoop edificio con Fornitore e industriale best practice consigliate.
Parte 1 :Best practice per la distribuzione di Hadoop Server su CentOS/RHEL 7Parte 2 :Impostazione dei prerequisiti Hadoop e rafforzamento della sicurezzaParte 3 :Come installare e configurare Cloudera Manager su CentOS/RHEL 7Parte 4 :Come installare CDH e configurare i posizionamenti dei servizi su CentOS/RHEL 7Parte 5 :Come impostare la disponibilità elevata per NamenodeParte 6 :Come impostare la disponibilità elevata per Resource ManagerParte 7 :Come installare e configurare Hive con disponibilità elevataParte 8 :Come installare e configurare Sentry (strumento di autorizzazione)Parte 9 :Come installare Kerberos (kerberizzazione del cluster) per l'autenticazione HadoopParte 10 :Come ottimizzare il cluster (ottimizzazione del filato) su CentOS/RHEL 7sistema operativo installazione e fare OS livello I prerequisiti sono i primi passi per costruire un cluster Hadoop . Hadoop può essere eseguito su vari tipi di piattaforma Linux:CentOS , RedHat , Ubuntu , Debian , SUSE ecc., Nella produzione in tempo reale, la maggior parte dei cluster Hadoop sono basati su RHEL/CentOS , utilizzeremo CentOS 7 per la dimostrazione in questa serie di tutorial.
In un'organizzazione, l'installazione del sistema operativo può essere eseguita utilizzando kickstart . Se si tratta di un cluster da 3 a 4 nodi, l'installazione manuale è possibile, ma se costruiamo un grande cluster con più di 10 nodi, è noioso installare il sistema operativo uno per uno. In questo scenario, entra in gioco il metodo Kickstart, possiamo procedere con l'installazione di massa utilizzando kickstart.
Ottenere buone prestazioni da un ambiente Hadoop dipende dal provisioning dell'hardware e del software corretti. Quindi, costruire un cluster Hadoop di produzione implica molta considerazione per quanto riguarda Hardware e Software.
In questo articolo, esamineremo vari benchmark sull'installazione del sistema operativo e alcune best practice per la distribuzione di Cloudera Hadoop Cluster Server su CentOS/RHEL 7 .
Considerazioni importanti e best practice per la distribuzione di Hadoop Server
Di seguito sono riportate le best practice per la configurazione della distribuzione di Cloudera Hadoop Cluster Server su CentOS/RHEL 7 .
- I server Hadoop non richiedono server standard aziendali per creare un cluster, richiede hardware di base.
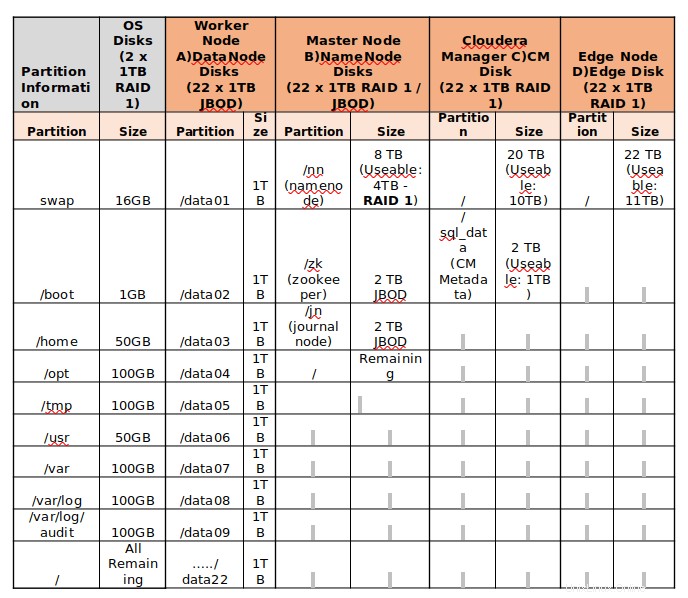
- Nel cluster di produzione, si consiglia di avere da 8 a 12 dischi dati. In base alla natura del carico di lavoro, dobbiamo decidere in merito. Se il cluster è destinato ad applicazioni ad alta intensità di calcolo, è consigliabile disporre da 4 a 6 unità per evitare problemi di I/O.
- Le unità dati devono essere partizionate individualmente, ad esempio, a partire da /data01 a /data10 .
- La configurazione RAID non è consigliata per i nodi di lavoro, perché Hadoop stesso fornisce la tolleranza agli errori sui dati replicando i blocchi in 3 per impostazione predefinita. Quindi JBOD è il migliore per i nodi di lavoro.
- Per i server principali, RAID 1 è la migliore pratica.
- Il filesystem predefinito su CentOS/RHEL 7.x è XFS . Hadoop supporta XFS, ext3 ed ext4. Il file system consigliato è ext3 poiché è stato testato per buone prestazioni.
- Tutti i server dovrebbero avere la stessa versione del sistema operativo, almeno la stessa versione secondaria.
- È consigliabile disporre di hardware omogeneo (tutti i nodi di lavoro devono avere le stesse caratteristiche hardware (RAM, spazio su disco e core, ecc.).
- A seconda del carico di lavoro del cluster (Balanced Workload, Compute Intensive, I/O Intensive) e delle dimensioni, la pianificazione delle risorse (RAM, CPU) per server sarà diversa.
Trova l'esempio di seguito per il partizionamento del disco dei server di 24 TB di archiviazione.
Installazione di CentOS 7 per la distribuzione di server Hadoop
Cose che devi sapere prima di installare CentOS 7 server per server Hadoop .
- L'installazione minima è sufficiente per i server Hadoop (nodi di lavoro ), in alcuni casi, la GUI può essere installata solo per i server Master o Management dove possiamo utilizzare i browser per le UI Web degli strumenti di gestione.
- La configurazione di reti, nome host e altre impostazioni relative al sistema operativo può essere eseguita dopo l'installazione del sistema operativo.
- In tempo reale, i fornitori di server disporranno della propria console per interagire e gestire i server, ad esempio:i server Dell dispongono di iDRAC, un dispositivo integrato con i server. Usando quell'interfaccia iDRAC possiamo installare il sistema operativo con un'immagine del sistema operativo nel nostro sistema locale.
In questo articolo abbiamo installato il sistema operativo (CentOS 7 ) nella macchina virtuale VMware. Qui, non avremo più dischi per eseguire le partizioni. CentOS è simile a RHEL (stessa funzionalità), quindi vedremo i passaggi per installare CentOS .
1. Inizia scaricando l'immagine ISO di CentOS 7.x nel tuo sistema Windows locale e selezionala durante l'avvio della macchina virtuale. Seleziona "Installa CentOS 7 ' come mostrato.
2. Seleziona la Lingua , l'impostazione predefinita sarà inglese e fai clic su continua .
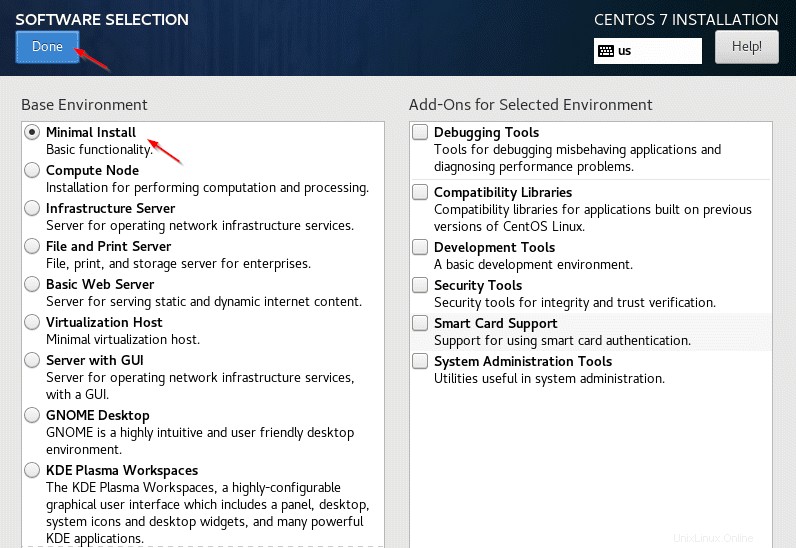
3. Selezione del software – Seleziona "Installazione minima ' e fai clic su 'Fine '.
4. Imposta la password di root come ci chiederà di impostare.
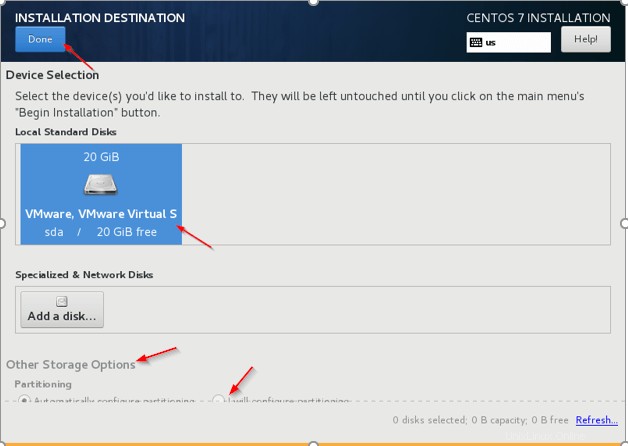
5. Destinazione dell'installazione – Questo è il passo importante per essere prudenti. Dobbiamo selezionare il disco in cui deve essere installato il sistema operativo, il disco dedicato dovrebbe essere selezionato per il sistema operativo. Fai clic su "Destinazione installazione ' e seleziona il Disco, in tempo reale ci saranno più dischi, dobbiamo selezionare, preferibilmente 'sda '.

6. Altre opzioni di archiviazione – Scegli la seconda opzione ( configurerò il partizionamento) per configurare il partizionamento relativo al sistema operativo come /var , /var/log , /casa , /tmp , /opt , /scambia .

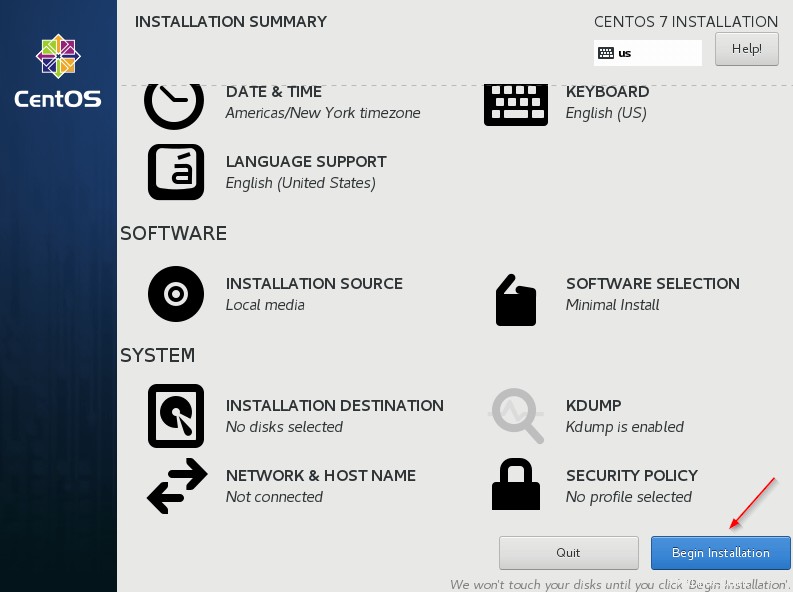
7. Al termine, inizia l'installazione.
8. Una volta completata l'installazione, riavviare il server.
9. Accedi al server e imposta il nome host.
# hostnamectl status # hostnamectl set-hostname tecmint # hostnamectl status
Riepilogo
In questo articolo, abbiamo esaminato i passaggi di installazione del sistema operativo e le migliori pratiche per il partizionamento del filesystem. Queste sono tutte linee guida generali, in base alla natura del carico di lavoro, potrebbe essere necessario concentrarci su più sfumature per ottenere le migliori prestazioni del cluster. La pianificazione del cluster è un'arte per Hadoop amministratore. Approfondiremo i prerequisiti a livello di sistema operativo e il rafforzamento della sicurezza nel prossimo articolo.