Introduzione
I database distribuiti vengono utilizzati per il ridimensionamento orizzontale e sono progettati per soddisfare i requisiti del carico di lavoro senza dover apportare modifiche all'applicazione del database o ridimensionare verticalmente una singola macchina.
I database distribuiti risolvono vari problemi , come disponibilità, tolleranza agli errori, velocità effettiva, latenza, scalabilità e molti altri problemi che possono derivare dall'utilizzo di una singola macchina e di un unico database.
In questo articolo imparerai cosa sono i database distribuiti e i loro vantaggi e svantaggi.

Definizione database distribuito
Un database distribuito rappresenta più database interconnessi distribuiti su più siti collegati da una rete. Poiché i database sono tutti collegati, agli utenti vengono visualizzati come un unico database.
I database distribuiti utilizzano più nodi. Si ridimensionano orizzontalmente e sviluppano un sistema distribuito. Un numero maggiore di nodi nel sistema fornisce maggiore potenza di elaborazione, maggiore disponibilità e risolvono il problema del singolo punto di errore.
Diverse parti del database distribuito sono archiviate in diverse posizioni fisiche e i requisiti di elaborazione sono distribuiti tra i processori su più nodi di database.
Un sistema di gestione di database distribuito centralizzato (DDBMS ) gestisce i dati distribuiti come se fossero archiviati in un'unica posizione fisica. DDBMS sincronizza tutte le operazioni sui dati tra i database e garantisce che gli aggiornamenti in un database si riflettano automaticamente sui database in altri siti.
Funzionalità del database distribuito
Alcune caratteristiche generali dei database distribuiti sono:
- Indipendenza dalla posizione - I dati vengono archiviati fisicamente in più siti e gestiti da un DDBMS indipendente.
- Elaborazione distribuita delle query - I database distribuiti rispondono alle query in un ambiente distribuito che gestisce i dati in più siti. Le query di alto livello vengono trasformate in un piano di esecuzione delle query per una gestione più semplice.
- Gestione distribuita delle transazioni - Fornisce un database distribuito coerente attraverso protocolli di commit, tecniche di controllo della concorrenza distribuita e metodi di ripristino distribuito in caso di molte transazioni e errori.
- Integrazione perfetta - I database in una raccolta di solito rappresentano un unico database logico e sono interconnessi.
- Collegamento di rete - Tutti i database in una raccolta sono collegati da una rete e comunicano tra loro.
- Elaborazione della transazione - I database distribuiti incorporano l'elaborazione delle transazioni, che è un programma che include una raccolta di una o più operazioni del database. L'elaborazione delle transazioni è un processo atomico che viene eseguito completamente o non viene eseguito affatto.
Tipi di database distribuiti
Esistono due tipi di database distribuiti:
- Omogeneo
- Eterogeneo
Omogeneo
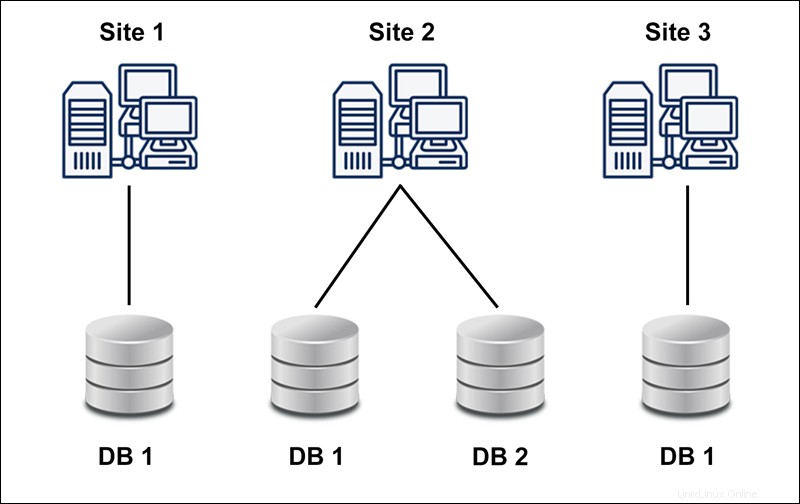
Un database distribuito omogeneo è una rete di database identici memorizzati su più siti. I siti hanno lo stesso sistema operativo, DDBMS e struttura dati, il che li rende facilmente gestibili.
I database omogenei consentono agli utenti di accedere ai dati da ciascuno dei database senza problemi.
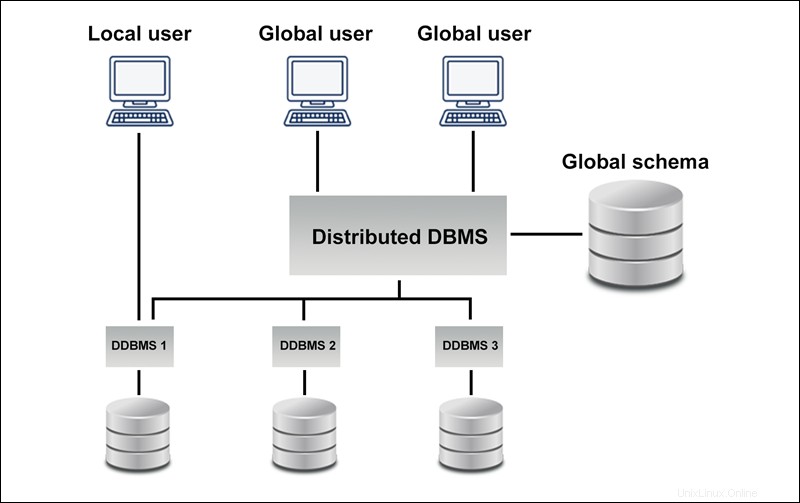
Il diagramma seguente mostra un esempio di database omogeneo:
Eterogeneo
Un database distribuito eterogeneo utilizza diversi schemi, sistemi operativi, DDBMS e diversi modelli di dati.
Nel caso di un database distribuito eterogeneo, un determinato sito può essere completamente all'oscuro di altri siti causando una cooperazione limitata nell'elaborazione delle richieste degli utenti. Il limite è il motivo per cui le traduzioni sono necessarie per stabilire la comunicazione tra i siti.
Il diagramma seguente mostra un esempio di database eterogeneo:
Archiviazione database distribuito
L'archiviazione del database distribuito è gestita in due modi:
- Replica
- Frammentazione
Replica
Nella replica del database, i sistemi archiviano copie di dati su siti diversi . Se un intero database è disponibile su più siti, è un database completamente ridondante.
Il vantaggio della replica del database è che aumenta la disponibilità dei dati o n siti diversi e consente l'elaborazione di richieste di query parallele.
Tuttavia, la replica del database significa che i dati richiedono aggiornamenti e sincronizzazione costanti con altri siti per mantenere una copia esatta del database. Eventuali modifiche apportate su un sito devono essere registrate su altri siti, altrimenti si verificano incongruenze.
Gli aggiornamenti costanti causano molto sovraccarico del server e complicano il controllo della concorrenza, poiché molte query simultanee devono essere controllate in tutti i siti disponibili.
Frammentazione
Quando si tratta di frammentazione dell'archiviazione distribuita del database, le relazioni sono frammentate, il che significa che sono divise in parti più piccole . Ciascuno dei frammenti è archiviato in un sito diverso, dove è richiesto.
Il prerequisito per la frammentazione è assicurarsi che i frammenti possano essere successivamente ricostruiti nella relazione originale senza perdere dati.
Il vantaggio della frammentazione è che non ci sono nessuna copia dei dati , che impedisce l'incoerenza dei dati.
Esistono due tipi di frammentazione:
- Frammentazione orizzontale - Lo schema di relazione è frammentato in gruppi di righe e ogni gruppo (tupla) è assegnato a un frammento.
- Frammentazione verticale - Lo schema di relazione è frammentato in schemi più piccoli e ogni frammento contiene una chiave candidata comune per garantire un join senza perdite.
Vantaggi e svantaggi del database distribuito
Di seguito sono riportati alcuni vantaggi e svantaggi chiave dei database distribuiti:
| Vantaggi | Svantaggi |
|---|---|
| Sviluppo modulare | Software costoso |
| Affidabilità | Grandi spese generali |
| Costi di comunicazione inferiori | Integrità dei dati |
| Migliore risposta | Distribuzione dei dati non corretta |
I vantaggi e gli svantaggi sono spiegati in dettaglio nelle sezioni seguenti.
Vantaggi
- Sviluppo modulare . Lo sviluppo modulare di un database distribuito implica che un sistema può essere esteso a nuove posizioni o unità aggiungendo nuovi server e dati alla configurazione esistente e collegandoli al sistema distribuito senza interruzioni. Questo tipo di espansione non provoca interruzioni nel funzionamento dei database distribuiti.
- Affidabilità . I database distribuiti offrono una maggiore affidabilità rispetto ai database centralizzati. In caso di errore del database in un database centralizzato, il sistema si arresta completamente. In un database distribuito, il sistema funziona anche quando si verificano errori, offrendo prestazioni ridotte solo fino alla risoluzione del problema.
- Costi di comunicazione inferiori . L'archiviazione locale dei dati riduce i costi di comunicazione per la manipolazione dei dati nei database distribuiti. L'archiviazione locale dei dati non è possibile nei database centralizzati.
- Risposta migliore . La distribuzione efficiente dei dati in un sistema di database distribuito fornisce una risposta più rapida quando le richieste degli utenti vengono soddisfatte localmente. Nei database centralizzati, le richieste degli utenti passano attraverso la macchina centrale, che elabora tutte le richieste. Il risultato è un aumento dei tempi di risposta, soprattutto con molte domande.
Svantaggi
- Software costoso . Garantire la trasparenza e il coordinamento dei dati tra più siti spesso richiede l'utilizzo di software costosi in un sistema di database distribuito.
- Grandi spese generali . Molte operazioni su più siti richiedono numerosi calcoli e una sincronizzazione costante quando viene utilizzata la replica del database, causando un notevole sovraccarico di elaborazione.
- Integrità dei dati . Un possibile problema quando si utilizza la replica del database è l'integrità dei dati, che viene compromessa dall'aggiornamento dei dati in più siti.
- Distribuzione impropria dei dati . La reattività alle richieste degli utenti dipende in gran parte dalla corretta distribuzione dei dati. Ciò significa che la reattività può essere ridotta se i dati non vengono distribuiti correttamente su più siti.