Introduzione
MapReduce è un modulo di elaborazione nel progetto Apache Hadoop. Hadoop è una piattaforma creata per affrontare i big data utilizzando una rete di computer per archiviare ed elaborare i dati.
La cosa così interessante di Hadoop è che i server dedicati a prezzi accessibili sono sufficienti per eseguire un cluster. Puoi utilizzare hardware di consumo a basso costo per gestire i tuoi dati.
Hadoop è altamente scalabile. Puoi iniziare con un minimo di una macchina, quindi espandere il tuo cluster a un numero infinito di server. I due principali componenti predefiniti di questa libreria software sono:
- Riduci mappa
- HDFS – File system distribuito Hadoop
In questo articolo parleremo del primo dei due moduli. imparerai che cos'è MapReduce, come funziona e la terminologia di base di Hadoop MapReduce .

Cos'è Hadoop MapReduce?
Il modello di programmazione di Hadoop MapReduce facilita l'elaborazione di big data archiviati su HDFS.
Utilizzando le risorse di più macchine interconnesse, MapReduce gestisce efficacemente una grande quantità di dati strutturati e non strutturati .
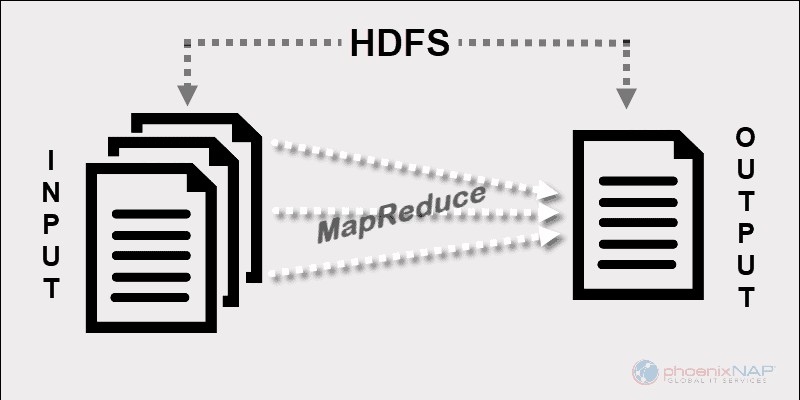
Prima di Spark e di altri framework moderni, questa piattaforma era l'unico attore nel campo dell'elaborazione di big data distribuita.
MapReduce assegna frammenti di dati tra i nodi in un cluster Hadoop. L'obiettivo è dividere un set di dati in blocchi e utilizzare un algoritmo per elaborare quei blocchi contemporaneamente. L'elaborazione parallela su più macchine aumenta notevolmente la velocità di gestione anche di petabyte di dati.
App di elaborazione dati distribuite
Questo framework consente la scrittura di applicazioni per l'elaborazione di dati distribuiti. Di solito, Java è ciò che la maggior parte dei programmatori usa poiché Hadoop è basato su Java .
Tuttavia, puoi scrivere app MapReduce in altre lingue, come Ruby o Python. Indipendentemente dalla lingua utilizzata da uno sviluppatore, non è necessario preoccuparsi dell'hardware su cui viene eseguito il cluster Hadoop.
Scalabilità
L'infrastruttura Hadoop può impiegare server di livello aziendale, nonché hardware di base. I creatori di MapReduce avevano in mente la scalabilità. Non è necessario riscrivere un'applicazione se si aggiungono più macchine. Basta modificare la configurazione del cluster e MapReduce continua a funzionare senza interruzioni.
Ciò che rende MapReduce così efficiente è che viene eseguito sugli stessi nodi di HDFS. Il programmatore assegna attività ai nodi in cui risiedono già i dati. Operare in questo modo aumenta il throughput disponibile in un cluster.
Come funziona MapReduce
Ad alto livello, MapReduce suddivide i dati di input in frammenti e li distribuisce su diverse macchine.
I frammenti di input sono costituiti da coppie chiave-valore. Le attività della mappa parallela elaborano i dati in blocchi sulle macchine in un cluster. L'output della mappatura funge quindi da input per la fase di riduzione. L'attività di riduzione combina il risultato in un output di coppia chiave-valore particolare e scrive i dati in HDFS.
Il file system distribuito Hadoop di solito viene eseguito sullo stesso set di macchine del software MapReduce. Quando il framework esegue un lavoro sui nodi che memorizzano anche i dati, il tempo per completare le attività si riduce notevolmente.
Terminologia di base di Hadoop MapReduce
Come accennato in precedenza, MapReduce è un livello di elaborazione in un ambiente Hadoop. MapReduce lavora su attività relative a un lavoro. L'idea è quella di affrontare una grande richiesta suddividendola in unità più piccole.
JobTracker e TaskTracker
Agli albori di Hadoop (versione 1), JobTracker e TaskTracker i demoni eseguivano operazioni in MapReduce. All'epoca, un cluster Hadoop poteva supportare solo le applicazioni MapReduce.
Un JobTracker controllava la distribuzione delle richieste dell'applicazione alle risorse di calcolo in un cluster. Poiché monitorava l'esecuzione e lo stato di MapReduce, risiedeva su un nodo master.
Un TaskTracker ha elaborato le richieste provenienti da JobTracker. Tutti i task tracker sono stati distribuiti tra i nodi slave in un cluster Hadoop.
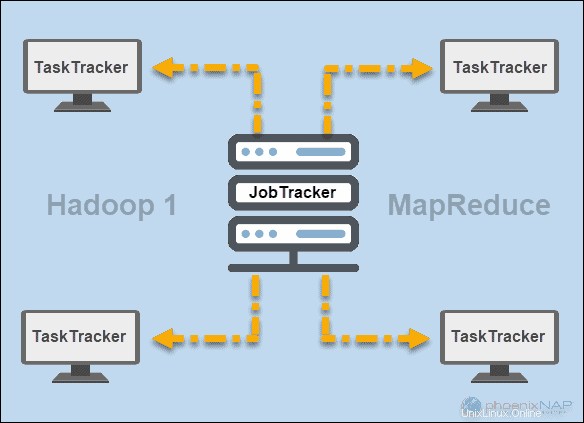
FILO
Successivamente, in Hadoop versione 2 e successive, YARN è diventato il principale gestore delle risorse e della pianificazione. Da qui il nome Ancora un altro responsabile delle risorse . Yarn ha anche lavorato con altri framework per l'elaborazione distribuita in un cluster Hadoop.
Lavoro MapReduce
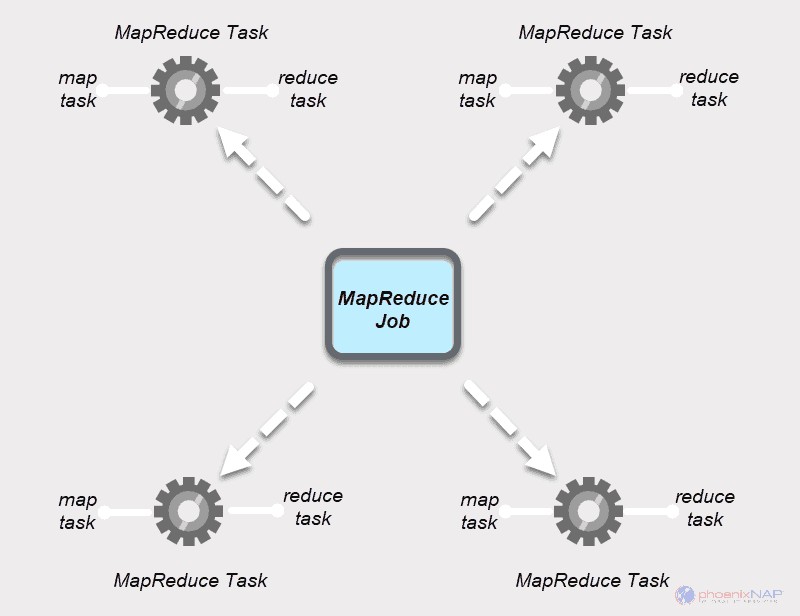
Un lavoro MapReduce è l'unità di lavoro principale nel processo MapReduce. È un compito che i processi Mappa e Riduci devono completare. Un lavoro è suddiviso in attività più piccole su un cluster di macchine per un'esecuzione più rapida.
Le attività dovrebbero essere abbastanza grandi da giustificare il tempo di gestione delle attività. Se dividi un lavoro in segmenti insolitamente piccoli, il tempo totale per preparare le divisioni e creare attività potrebbe superare il tempo necessario per produrre l'output effettivo del lavoro.
Attività MapReduce
I lavori MapReduce hanno due tipi di attività.
Un attività sulla mappa è una singola istanza di un'app MapReduce. Queste attività determinano quali record elaborare da un blocco di dati. I dati di input vengono suddivisi e analizzati, in parallelo, sulle risorse di calcolo assegnate in un cluster Hadoop. Questo passaggio di un processo MapReduce prepara l'output della coppia
Un Riduci attività elabora un output di un'attività della mappa. Simile alla fase della mappa, tutte le attività di riduzione si verificano contemporaneamente e funzionano in modo indipendente. I dati vengono aggregati e combinati per fornire l'output desiderato. Il risultato finale è un insieme ridotto di coppie
Le fasi Mappa e Riduci hanno due parti ciascuna.
La Mappa la prima parte riguarda la scissione dei dati di input che vengono assegnati alle singole attività della mappa. Quindi, la mappatura La funzione crea l'output sotto forma di coppie chiave-valore intermedie.
Il Riduci lo stadio ha un shuffle e uno step di riduzione. Mischiare prende l'output della mappa e crea un elenco di coppie chiave-valore-elenco correlate. Quindi, riducendo aggrega i risultati della mescolanza per produrre l'output finale richiesto dall'applicazione MapReduce.
Come mappare Hadoop e ridurre il lavoro insieme
Come suggerisce il nome, MapReduce funziona elaborando i dati di input in due fasi:Mappa e Riduci . Per dimostrarlo, useremo un semplice esempio contando il numero di occorrenze di parole in ogni documento.
L'output finale che stiamo cercando è:Quante volte le parole Apache, Hadoop, Class e Track compaiono in totale in tutti i documenti .
A scopo illustrativo, l'ambiente di esempio è costituito da tre nodi. L'input contiene sei documenti distribuiti nel cluster. Lo terremo semplice qui, ma in circostanze reali non c'è limite. Puoi avere migliaia di server e miliardi di documenti.
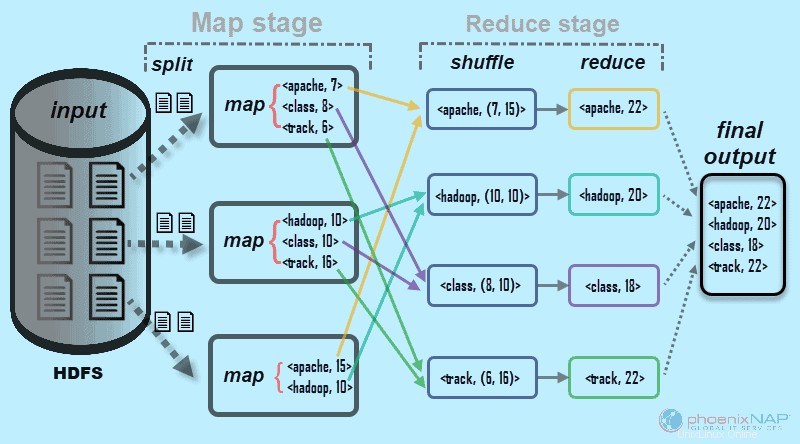
1. Innanzitutto, nella fase della mappa , i dati di input (i sei documenti) sono divisi e distribuito nel cluster (i tre server). In questo caso, ogni attività della mappa funziona su una divisione contenente due documenti. Durante la mappatura, non c'è comunicazione tra i nodi. Si esibiscono in modo indipendente.
Questo processo viene eseguito in attività parallele su tutti i nodi per tutti i documenti e fornisce un output unico.
Il passaggio casuale assicura le chiavi Apache, Hadoop, Class, e Traccia sono ordinati per la fase di riduzione. Questo processo raggruppa i valori per chiavi sotto forma di
Nel nostro esempio dal diagramma, le attività di riduzione ottengono i seguenti risultati individuali:
L'esempio che abbiamo usato qui è di base. MapReduce esegue compiti molto più complicati.
Alcuni dei casi d'uso includono:
- Trasformare i log di Apache in valori separati da tabulazioni (TSV).
- Determinazione del numero di indirizzi IP univoci nei dati del weblog.
- Esecuzione di modelli e analisi statistiche complesse.
- Esecuzione di algoritmi di apprendimento automatico utilizzando framework diversi, come Mahout.
Come le partizioni Hadoop mappano i dati di input
Il partizionatore è responsabile dell'elaborazione dell'output della mappa. Una volta che MapReduce divide i dati in blocchi e li assegna alle attività di mappatura, il framework partiziona i dati chiave-valore. Questo processo ha luogo prima che venga prodotto l'output dell'attività di mappatura finale.
MapReduce partiziona e ordina l'output in base alla chiave. Qui vengono raggruppati tutti i valori per le singole chiavi e il partizionatore crea un elenco contenente i valori associati a ciascuna chiave. Inviando tutti i valori di una singola chiave allo stesso riduttore, il partizionatore garantisce un'equa distribuzione dell'output della mappa al riduttore.
Il partizionatore predefinito è ben configurato per molti casi d'uso, ma puoi riconfigurare il modo in cui MapReduce partiziona i dati.
Se ti capita di utilizzare un partizionatore personalizzato, assicurati che la dimensione dei dati preparati per ogni riduttore sia più o meno la stessa. Quando si partizionano i dati in modo non uniforme, un'attività di riduzione può richiedere molto più tempo per essere completata. Ciò rallenterebbe l'intero processo MapReduce.