Introduzione
I database NoSQL ci consentono di archiviare grandi quantità di dati e di accedervi in qualsiasi momento, da qualsiasi luogo e dispositivo. Tuttavia, è difficile decidere quale tecnica di modellazione dei dati sia più adatta alle proprie esigenze. Fortunatamente, esiste una tecnica di modellazione dei dati per ogni caso d'uso.
In questo tutorial tratteremo tutte le diverse tecniche di modellazione dei dati NoSQL che puoi utilizzare durante la creazione del tuo database NoSQL.

Che cos'è un modello di dati NoSQL?
NoSQL o "Non solo SQL" è un modello di dati che differisce nettamente dalle aspettative SQL tradizionali.
La differenza principale è che NoSQL non utilizza una tecnica di modellazione dei dati relazionali e sottolinea la progettazione flessibile. La mancanza di requisiti per uno schema rende la progettazione di un processo molto più semplice ed economico. Questo non vuol dire che non puoi utilizzare del tutto uno schema, ma piuttosto che la progettazione dello schema è molto flessibile.
Un'altra caratteristica utile dei modelli di dati NoSQL è che sono costruiti per un'elevata efficienza e velocità in termini di creazione fino a milioni di query al secondo. Ciò si ottiene avendo tutti i dati contenuti in una tabella, quindi JOINS e riferimenti incrociati non sono così pesanti per le prestazioni.
NoSQL è anche unico in quanto è scalabile orizzontalmente , rispetto a SQL che è scalabile solo verticalmente. Con NoSQL puoi semplicemente usare un altro shard, che è economico, invece di acquistare più hardware, che non lo è.
Quattro tipi di database NoSQL
In generale, esistono quattro diversi tipi di database NoSQL, con decine di modelli di dati basati su di essi:
Negozio valore chiave
Creati appositamente per requisiti di prestazioni elevate e probabilmente uno dei modelli di dati più comuni, gli archivi valori-chiave utilizzano valori chiave con puntatori per archiviare i dati.
Questo puntatore è unico e si collega direttamente a un'informazione, che può essere qualsiasi cosa tu voglia che sia. Puoi anche utilizzare una stringa vuota come chiave di valore, se lo desideri, anche se ci sono limiti superiori a quanto può essere grande un valore a seconda del database.
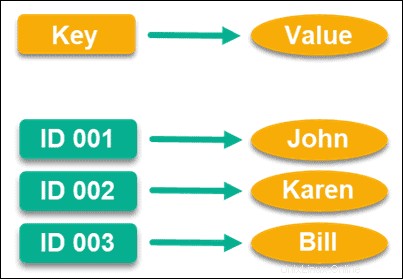
È interessante notare che è stato Amazon che originariamente ha aiutato a far decollare questo modello di dati e lo usano per DynamoDB. Dato che sono uno dei più grandi mercati online del mondo, puoi vedere quanto può essere performante questo modello di dati.
Archivio basato su documenti
Con SQL, XML e JSON tendono a essere legati insieme, il che rallenta le query e ostacola l'intero processo. Poiché NoSQL non utilizza il modello relazionale, non è necessario che lo faccia, ed è qui che entrano in gioco gli archivi basati su documenti.
Tutti i dati sono archiviati in una tabella, quindi non c'è bisogno di riferimenti incrociati e invece di archiviare le informazioni in una tabella, sono archiviate in un documento. Sebbene sia molto simile a un archivio di valori-chiave e talvolta possa essere considerato sotto il suo ombrello, la differenza è che NoSQL basato su documenti generalmente ha una qualche forma di codifica, come XML.
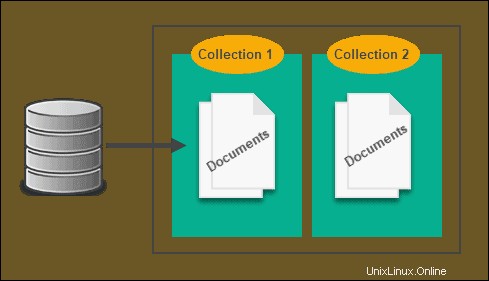
Esiste un database NoSQL specifico per XML che utilizza un archivio documenti. In effetti, Strider CD utilizza MongoDB come archivio di supporto.
Negozio basato su colonne
Questo tipo di modello di dati memorizza le informazioni in colonne, anziché in righe, cosa più comune con SQL. I dati vengono archiviati in colonne, che sono raggruppate in famiglie e queste famiglie sono ulteriormente raggruppate in più colonne. Questo essenzialmente crea un modello di dati annidato di colonne quasi illimitato.
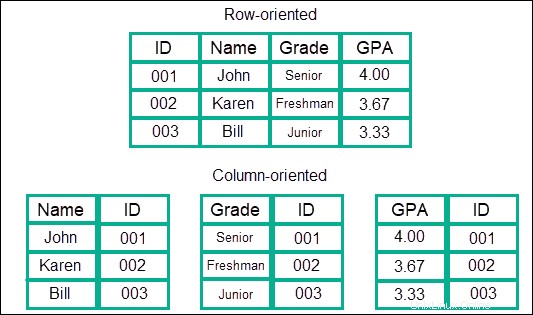
Il vantaggio è che offre velocità incredibilmente elevate rispetto ad altri modelli o NoSQL quando si tratta di ricerche. I dati vengono trattati come un'immissione continua e quindi non è necessario passare da una riga all'altra o da aree diverse in cui sono archiviate le informazioni.
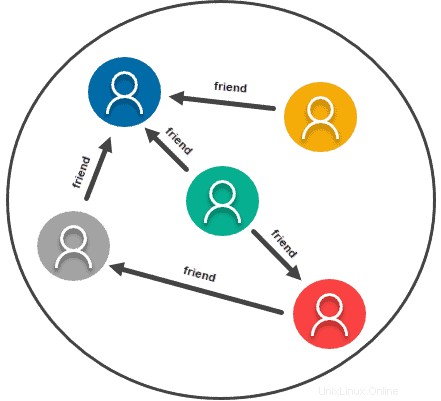
Archivio basato su grafici
I modelli di dati grafici o di rete trattano essenzialmente la relazione tra due informazioni qualsiasi come importante quanto l'informazione stessa. In quanto tale, questo tipo di modello di dati è davvero realizzato per qualsiasi informazione che di solito rappresenti su un grafico. Utilizza relazioni e nodi, con i dati che costituiscono le informazioni stesse e la relazione si forma tra i nodi.
Come vengono archiviati i dati in NoSQL?
L'archiviazione dei dati NoSQL dipende dal tipo di database utilizzato. Poiché NoSQL non richiede uno schema, non esiste un progetto su come archiviare i dati e quindi varia tra i database.
In generale, ci sono due modi in cui funziona l'archiviazione dei dati NoSQL:
- Su disco utilizzando B-Trees , con la parte superiore permanentemente nella RAM.
- In memoria dove è tutto su RAM utilizzando RB-Trees e tutto ciò che è memorizzato sul disco è solo un'appendice.
Progettazione di schemi per NoSQL
Poiché i database NoSQL non hanno realmente una struttura prestabilita, lo sviluppo e la progettazione dello schema tendono a concentrarsi sul modello fisico dei dati. Ciò significa sviluppare per ambienti ampi e ampi orizzontalmente, qualcosa in cui NoSQL eccelle. Pertanto, le particolarità e i problemi specifici che derivano dalla scalabilità sono in primo piano.
Pertanto, il primo passo è definire i requisiti aziendali, poiché l'ottimizzazione dell'accesso ai dati è un must e può essere raggiunta solo sapendo cosa l'azienda vuole a che fare con i dati. La progettazione del tuo schema dovrebbe integrare i flussi di lavoro legati al tuo caso d'uso.
Esistono diversi modi per selezionare la chiave primaria e, in definitiva, ciò dipende dagli utenti stessi. Detto questo, alcuni dati potrebbero suggerire uno schema più efficiente, soprattutto in termini di frequenza con cui vengono interrogati quei dati.
Tecniche di modellazione dei dati NoSQL
Tutte le tecniche di modellazione dei dati NoSQL sono raggruppate in tre gruppi principali:
- Tecniche concettuali
- Tecniche generali di modellazione
- Tecniche di modellazione gerarchica
Di seguito, discuteremo brevemente tutte le tecniche di modellazione dei dati NoSQL.
Tecniche concettuali
Esistono tre tecniche concettuali per la modellazione dei dati NoSQL:
- Denormalizzazione . La denormalizzazione è una tecnica piuttosto comune e comporta la copia dei dati in più tabelle o moduli per semplificarli. Con la denormalizzazione, raggruppa facilmente tutti i dati che devono essere interrogati in un unico posto. Ovviamente, questo significa che il volume dei dati aumenta per parametri diversi, il che aumenta considerevolmente il volume dei dati.
- Aggregati . Ciò consente agli utenti di formare entità nidificate con strutture interne complesse, nonché di variare la loro struttura particolare. In definitiva, l'aggregazione riduce i join riducendo al minimo le relazioni uno-a-uno.
La maggior parte dei modelli di dati NoSQL ha una qualche forma di questa tecnica di schema morbido. Ad esempio, i database dell'archivio di grafici e valori-chiave hanno valori che possono essere di qualsiasi formato, poiché tali modelli di dati non impongono vincoli al valore. Allo stesso modo, un altro esempio come BigTable ha l'aggregazione tramite colonne e famiglie di colonne. - Partecipazioni lato applicazione. NoSQL di solito non supporta i join, poiché i database NoSQL sono orientati alle domande in cui vengono eseguiti i join durante la fase di progettazione. Questo viene confrontato con i database relazionali in cui vengono eseguiti al momento dell'esecuzione della query. Naturalmente, questo tende a comportare una penalizzazione delle prestazioni e talvolta è inevitabile.
Tecniche generali di modellazione
Esistono cinque tecniche generali per la modellazione dei dati NoSQL:
- Chiavi enumerabili . Per la maggior parte, i valori di chiave non ordinati sono molto utili, poiché le voci possono essere partizionate su più server dedicati semplicemente eseguendo l'hashing della chiave. Ciononostante, è utile aggiungere una qualche forma di funzionalità di ordinamento tramite chiavi ordinate, anche se potrebbe aggiungere un po' più di complessità e aumentare le prestazioni.
- Riduzione dimensionale . I sistemi di informazione geografica tendono a utilizzare R-Tree indici e devono essere aggiornati sul posto, il che può essere costoso se si tratta di grandi volumi di dati. Un altro approccio tradizionale consiste nell'appiattire la struttura 2D in un elenco semplice, come quello che viene fatto con Geohash.
Con la riduzione della dimensionalità, puoi mappare i dati multidimensionali a un semplice valore-chiave o anche a modelli non multidimensionali.
Utilizza la riduzione della dimensionalità per mappare i dati multidimensionali su un modello valore-chiave o su un altro modello non multidimensionale. - Tabella degli indici. Con una tabella degli indici, sfrutta gli indici negli archivi che non li supportano necessariamente internamente. Mira a creare e quindi mantenere una tabella univoca con chiavi che seguano un modello di accesso specifico. Ad esempio, una tabella principale per memorizzare gli account utente per l'accesso tramite ID utente.
- Indice chiave composita . Sebbene siano in qualche modo una tecnica generica, le chiavi composite sono incredibilmente utili quando vengono utilizzate le chiavi ordinate. Se lo prendi e lo combini con le chiavi secondarie, puoi creare un indice multidimensionale abbastanza simile alla tecnica di Riduzione dimensionale sopra menzionata.
- Ricerca invertita – Aggregazione diretta. Il concetto alla base di questa tecnica è utilizzare un indice che soddisfi un insieme specifico di criteri, ma poi aggregare quei dati con scansioni complete o qualche forma di rappresentazione originale.
Questo è più un modello di elaborazione dei dati che una modellazione dei dati, tuttavia i modelli di dati sono sicuramente influenzati dall'utilizzo di questo tipo di modello di elaborazione. Tieni presente che il recupero casuale dei record richiesti per questa tecnica è inefficiente. Utilizza l'elaborazione delle query in batch per mitigare questo problema.
Tecniche di modellazione della gerarchia
Esistono sette tecniche di modellazione gerarchica per i dati NoSQL:
- Aggregazione ad albero. L'aggregazione ad albero sta essenzialmente modellando i dati come un unico documento. Questo può essere davvero efficiente quando si tratta di qualsiasi record a cui si accede sempre contemporaneamente, come un thread di Twitter o un post di Reddit. Naturalmente, il problema diventa allora che l'accesso casuale a ogni singola voce è inefficiente.
- Elenchi di adiacenza. Questa è una tecnica semplice in cui i nodi sono modellati come record indipendenti di array con antenati diretti. Questo è un modo complicato per dire che ti consente di cercare i nodi dai loro genitori o figli. Proprio come l'aggregazione ad albero, tuttavia, è anche abbastanza inefficiente per recuperare un intero sottoalbero per un dato nodo.
- Percorsi materializzati. Questa tecnica è una sorta di denormalizzazione e viene utilizzata per evitare attraversamenti ricorsivi nelle strutture ad albero. Principalmente, vogliamo attribuire i genitori oi figli a ciascun nodo, il che ci aiuta a determinare eventuali predecessori o discendenti del nodo senza preoccuparci dell'attraversamento. Per inciso, possiamo memorizzare percorsi materializzati come ID, sia come set che come singola stringa.
- Set nidificati . Una tecnica standard per strutture ad albero nei database relazionali, è altrettanto applicabile a NoSQL e database di valori-chiave o documenti. L'obiettivo è archiviare le foglie dell'albero come un array e quindi mappare ogni nodo non foglia su un intervallo di foglie utilizzando gli indici di inizio/fine.
Modellarlo in questo modo è un modo efficiente per gestire dati immutabili poiché richiede solo una piccola quantità di memoria e non deve necessariamente utilizzare traversal. Detto questo, gli aggiornamenti sono costosi perché richiedono aggiornamenti degli indici. - Appiattimento dei documenti nidificati:nomi dei campi numerati. La maggior parte dei motori di ricerca tende a lavorare con documenti che sono un elenco piatto di campi e valori, piuttosto che qualcosa con una struttura interna complessa. In quanto tale, questa tecnica di modellazione dei dati cerca di mappare queste strutture complesse su un documento semplice, ad esempio mappando documenti con una struttura gerarchica, una difficoltà comune che potresti incontrare.
Naturalmente, questo tipo di lavoro è faticoso e non facilmente scalabile, soprattutto all'aumentare delle strutture nidificate. - Appiattimento dei documenti nidificati:query di prossimità. Un modo per risolvere i potenziali problemi con la tecnica di modellazione dei dati dei nomi dei campi numerati consiste nell'utilizzare una tecnica simile chiamata Query di prossimità. Questi limitano la distanza tra le parole in un documento, il che aiuta ad aumentare le prestazioni e a ridurre l'impatto sulla velocità delle query.
- Elaborazione di grafici batch. L'elaborazione del grafico batch è un'ottima tecnica per esplorare le relazioni su o giù per un nodo, in pochi passaggi. È un processo costoso e non necessariamente si adatta molto bene. Utilizzando Message Passing e MapReduce possiamo eseguire questo tipo di elaborazione del grafico.