Introduzione
Il gawk command è la versione GNU di awk. Gawk è un potente strumento di elaborazione del testo e manipolazione dei dati con molte funzionalità e usi pratici.
Questa guida ti insegnerà come usare Linux gawk comando con esempi.

Prerequisiti
- Un sistema che esegue Linux.
- Accesso al terminale.
- Un file di testo. Questo tutorial utilizza il file persone come esempio.
Sintassi dei comandi gawk Linux
Il gawk di base la sintassi è simile a questa:
gawk [options] [actions/filters] input_file
Il comando non può essere eseguito senza argomenti. Le opzioni non sono obbligatorie, ma per gawk per produrre output, deve essere assegnata almeno un'azione. Azioni e filtri sono diversi sottocomandi e criteri di selezione che abilitano gawk per manipolare i dati dal file di input.
Nota :racchiude opzioni e azioni tra virgolette singole.
Opzioni gawk
Il gawk command è uno strumento versatile grazie ai suoi numerosi argomenti. Con gawk essendo l'implementazione GNU di awk , lungo, sono disponibili opzioni in stile GNU. Ogni opzione lunga ne ha una corrispondente corta.
Le opzioni comuni sono presentate di seguito:
| Opzione | Descrizione |
|---|---|
-f program-file , --file program-file | Legge i comandi da un file, che funge da script, invece del primo argomento nel terminale. |
-F fs , --field-separator fs | Utilizza la variabile predefinita fs come separatore del campo di input. |
-v var=val , --assign var=val | Assegna un valore alla variabile prima di eseguire uno script. |
-b , --characters-as-bytes | Tratta tutti i dati come caratteri a byte singolo. |
-c , --traditional | Esegue gawk in modalità compatibilità. |
-C , --copyright | Visualizza il messaggio GNU Copyright. |
-d[file] , --dump-variables[=file] | Mostra un elenco di variabili, i loro tipi e valori. |
-e program-text , --source program-text | Consente la combinazione di funzioni di libreria e codice sorgente. |
-E file , --exec file | Disattiva le assegnazioni delle variabili del terminale. |
-L [value] , --lint[=value] | Stampa messaggi di avviso sul codice non portabile ad altre implementazioni AWK. |
-S , --sandbox | Esegue gawk in modalità sandbox. |
Variabili incorporate di gawk
Il gawk comando offre diverse variabili integrate utilizzate per memorizzare e aggiungere valore al comando. Le variabili vengono manipolate dal terminale e influiscono sul programma solo quando un utente assegna loro un valore. Alcuni importanti gawk le variabili integrate sono:
| Variabile | Descrizione |
|---|---|
ARGC | Mostra il numero di argomenti del terminale. |
ARGIND | Visualizza l'indice del file ARGV. |
ARGV | Presenta un array di argomenti del terminale. |
ERRNO | Contiene stringhe che descrivono un errore di sistema. |
FIELDWIDTHS | Visualizza un elenco di larghezze di campo separate da spazi bianchi. |
FILENAME | Stampa il nome del file di input. |
FNR | Mostra il numero del record di input. |
FS | Rappresenta il separatore del campo di input. |
IGNORECASE | Attiva o disattiva la ricerca con distinzione tra maiuscole e minuscole. |
NF | Stampa il conteggio dei campi del file di input. |
NR | Stampa il conteggio delle righe del file corrente. |
OFS | Visualizza il separatore del campo di output. |
ORS | Mostra il separatore del record di output. |
RS | Stampa il separatore del record di input. |
RSTART | Rappresenta l'indice del primo carattere abbinato. |
RLENGTH | Rappresenta la lunghezza della stringa corrispondente. |
Esempi stupefacenti
L'uso di gawk le funzioni di pattern-matching e di elaborazione del linguaggio sono estese. Questo articolo mira a fornire esempi pratici attraverso i quali gli utenti imparano a utilizzare l'utilità gawk.
Importante: Il gawk il comando fa distinzione tra maiuscole e minuscole. Usa il IGNORECASE variabile per ignorare maiuscole e minuscole.
Stampa file
Per impostazione predefinita, gawk con un print argomento visualizza ogni riga del file specificato. Ad esempio, eseguendo il comando cat su people il file di testo stampa quanto segue:

Il gawk il comando mostra lo stesso risultato:
gawk '{print}' people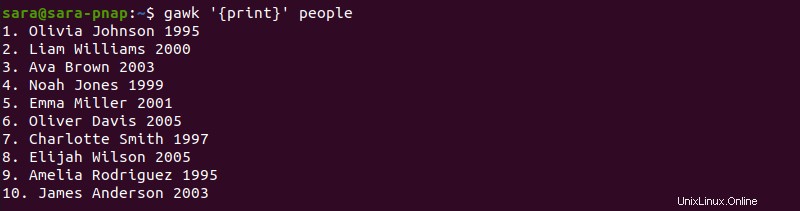
Stampa una colonna
Nei file di testo, gli spazi vengono generalmente utilizzati come delimitatori per le colonne. Le persone il file è composto da quattro colonne:
- Numeri ordinali.
- Nomi.
- Cognomi.
- Anno di nascita.
Usa gawk per mostrare solo una colonna specifica nel terminale. Ad esempio:
gawk '{print $2}' people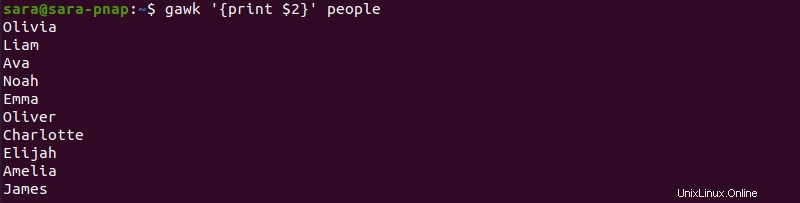
Il comando stampa solo la seconda colonna. Per stampare più colonne, come la prima colonna (numeri ordinali) e la seconda colonna (nomi), esegui:
gawk '{print $1, $2}' people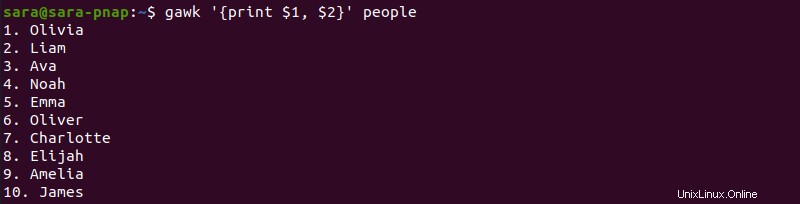
Il gawk il comando funziona anche senza la virgola tra $1 e $2 . Tuttavia, nell'output non sono presenti spazi tra le colonne:
gawk '{print $1 $2}' people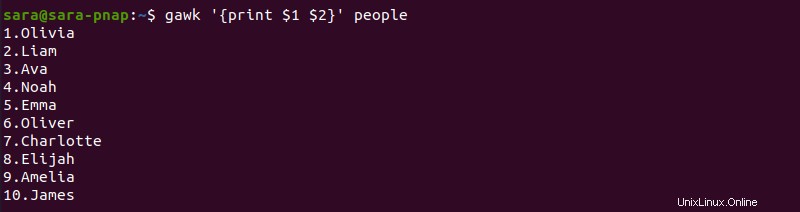
Colonne filtro
Il gawk comando offre ulteriori opzioni di filtraggio. Ad esempio, stampa righe contenenti la lettera maiuscola O con:
gawk '/O/ {print}' people
Per mostrare solo le righe contenenti lettere O o A , usa le tubazioni:
gawk '/O|A/ {print}' people
Il comando stampa qualsiasi riga che includa una parola con la O maiuscola oppure A . D'altra parte, usa la logica AND (&& ) per mostrare le righe che includono entrambi O e l'anno 1995 :
gawk '/O/ && /1995/' people
I filtri funzionano anche con i numeri. Ad esempio, mostra solo le persone nate negli anni '90 con:
gawk '/199*/ {print}' people
L'output mostra solo le righe in cui la quarta colonna include il valore 199 .
Personalizza ulteriormente l'output combinando le opzioni menzionate in precedenza. Ad esempio, stampa solo il nome e il cognome delle persone nate nel 1995 o 2003 con:
gawk '/1995|2003/ {print $2, $3}' people
Il comando stampa le colonne due e tre come indicato nel {print $2, $3} parte. L'output mostra solo le righe contenenti i numeri 1995 e 2003 , anche se le colonne contenenti quei numeri sono nascoste.
Il gawk Il comando consente inoltre agli utenti di stampare tutto tranne le righe contenenti la stringa specificata con la logica NOT (! ). Ad esempio, ometti le righe contenenti la stringa 19 nell'output:
gawk '!/19/' people
Aggiungi numeri di riga
Le persone il file include i numeri di riga nella prima colonna. Nel caso in cui gli utenti stiano lavorando su un file senza numeri di riga, gawk presenta le opzioni per aggiungerli.
Ad esempio, gli umani il file non include numeri ordinali:
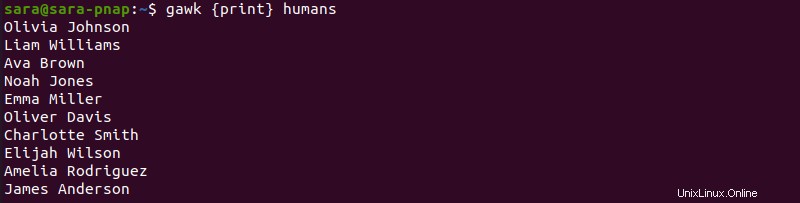
Per aggiungere i numeri di riga, esegui gawk con FNR e next :
gawk '{ print FNR, $0; next}' humans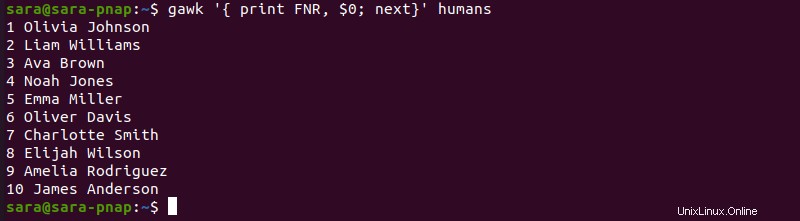
Il comando aggiunge un numero di riga prima di ogni riga. Lo stesso risultato si ottiene con il NR variabile:
gawk '{print NR, $0}' mobile.txt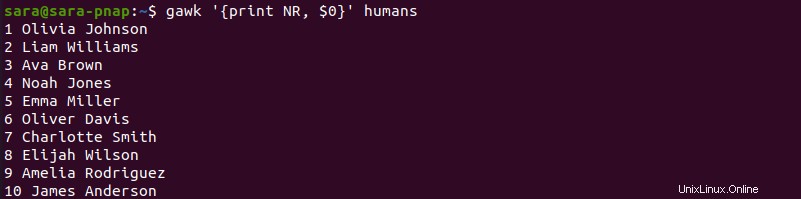
Trova conteggio righe
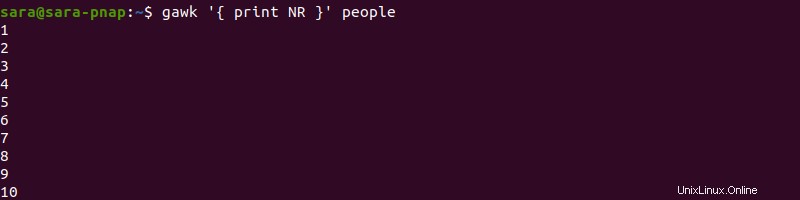
Per contare il numero totale di righe nel file, utilizza il END dichiarazione e il NR variabile con gawk :
gawk 'END { print NR }' people
Il comando legge ogni riga. Una volta gawk raggiunge END , stampa il valore di NR - che contiene il numero totale di righe. Eseguire lo stesso comando senza il END l'istruzione stampa solo il valore di NR - il numero di righe:
Filtra le righe in base alla lunghezza
Utilizzare la seguente opzione di comando per stampare solo righe più lunghe di 20 caratteri:
gawk 'length>20' people
Funziona anche con più argomenti. Ad esempio, mostra righe più lunghe di 17 ma inferiore a 20 caratteri:
gawk 'length<20 && length>17' people
Per visualizzare righe lunghe esattamente 20 caratteri, esegui:
gawk 'length==20' people
Stampa informazioni in base alle condizioni
Il gawk Il comando consente l'uso delle istruzioni if-else. Ad esempio, un altro modo per filtrare solo le persone nate dopo il 1999 è con una semplice istruzione if:
gawk '{ if ($4>1999) print }' people
L'istruzione if imposta la condizione che le voci nella colonna quattro debbano essere maggiori di 1999 . L'output mostra solo le voci che soddisfano la condizione. Espandi il comando in un'istruzione if-else per stampare righe che non soddisfano la condizione originale.
gawk '{if ($4>1999) print $0," ==>00s"; else print $0, "==>90s"}' people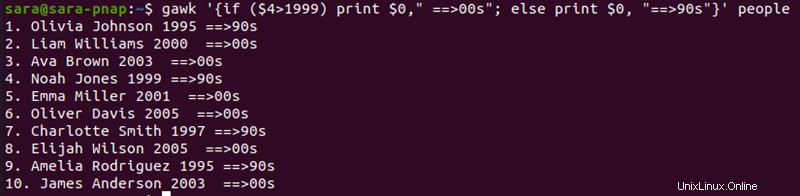
Il comando include:
- Dichiarazione If. Se la condizione è soddisfatta,
gawkaggiunge una stringa "==>90s " alla riga di output. - Altra affermazione. Nel caso in cui la riga non soddisfi la condizione,
gawkstampa ancora quella riga nell'output, aggiungendo "==>00s " stringa all'output.
Aggiungi un'intestazione
Allo stesso modo in cui il END consente agli utenti di modificare l'output alla fine del file, il BEGIN formatta i dati all'inizio.
Se utilizzato con awk , il BEGIN le sezioni vengono sempre eseguite per prime. Successivamente, awk esegue le righe rimanenti. Un modo per utilizzare il BEGIN istruzione consiste nell'aggiungere un'intestazione all'output.
Esegui il comando seguente per aggiungere una sezione sopra il awk uscita:
gawk 'BEGIN {print "No/First&Last Name/Year of Birth"} {print $0}' people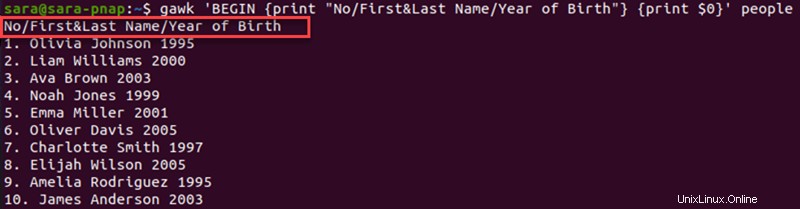
Trova la lunghezza della linea più lunga
Combina gli argomenti precedenti con il se e END dichiarazioni per trovare la riga più lunga nelle persone file:
gawk '{ if (length($0) > max) max = length($0) } END { print max }' people
Trova il numero di campi
Il gawk Il comando consente inoltre agli utenti di visualizzare il numero di campi con il NF variabile. Il modo più semplice per visualizzare il numero di campi stampa un output di difficile lettura:
gawk '{print NF}' people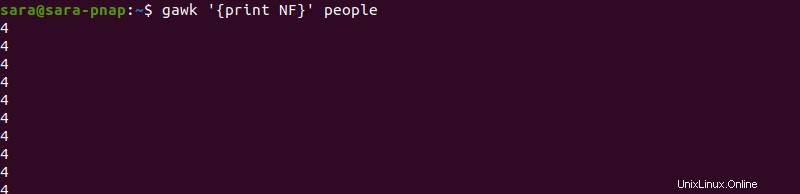
Il comando restituisce il numero di campi per riga senza alcuna informazione aggiuntiva. Per personalizzare l'output e renderlo più leggibile, regola il comando iniziale:
gawk '{print NR, "-->", NF}' people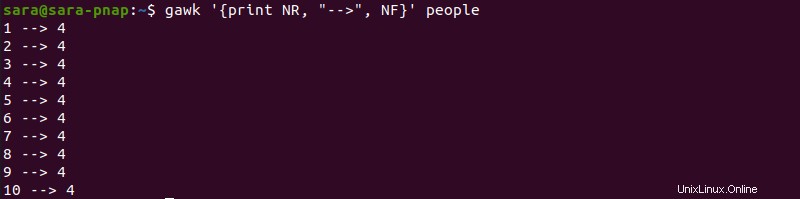
Il comando ora include:
- Il
NRvariabile che aggiunge numeri di riga a ciascuna riga di output. - Il
-->stringa che separa i numeri di riga dai numeri di campo.
Un altro modo per mostrare i numeri di riga e campo nelle persone il file è quello di stampare colonne con NF . Tieni presente che le persone il file include i numeri ordinali nella colonna uno. Pertanto il NR la variabile è omessa:
gawk '{print $0, "-->", NF}' people
Infine, per stampare il numero totale di campi, eseguire:
gawk '{num_fields = num_fields + NF} END {print num_fields}' people
Il file ha dieci righe e quattro colonne. Quindi, l'output è corretto.
Conclusione
Dopo aver seguito questo tutorial, sai come utilizzare il gawk per l'elaborazione avanzata del testo e la manipolazione dei dati.
Considera anche l'utilizzo di grep, un potente strumento Linux per la ricerca di stringhe, parole e schemi.