Ho una strana domanda per te.
Il tuo sistema Linux si è mai lamentato del fatto che non avevi spazio rimasto mentre chiaramente ne hai ancora più che sufficiente?
Mi è successo che avevo molti GB rimasti, ma il mio sistema Linux si è lamentato che non c'era più spazio. È stato allora che ho appreso degli inode .
inodes in breve
Inodes memorizza i metadati per ogni file sul tuo sistema in una struttura simile a una tabella solitamente situata vicino all'inizio di una partizione. Memorizzano tutte le informazioni tranne il nome del file ei dati.
Ogni file in una determinata directory è una voce con il nome del file e il numero di inode. Tutte le altre informazioni sul file vengono recuperate dalla tabella degli inode facendo riferimento al numero dell'inode.
I numeri di inode sono univoci a livello di partizione. Ogni partizione ha la propria tabella di inode.
Se finisci gli inode, non puoi creare nuovi file anche se hai spazio rimasto sulla partizione data.
Cos'è inode in Linux?
Inode sta per Index Node. Sebbene la storia non ne sia del tutto sicura, è l'ipotesi più logica e migliore che hanno escogitato. Era scritto I-node , ma il trattino si è perso nel tempo.
Come descritto su linfo.org:
Un inode è una struttura di dati … … che memorizza tutte le informazioni su un file tranne il suo nome e i suoi dati effettivi.
Inodes memorizza i metadati sul file a cui fa riferimento. Questi metadati contengono tutte le informazioni su detto file.
- Taglia
- Autorizzazione
- Proprietario/Gruppo
- Posizione del disco rigido
- Data/ora
- Altre informazioni
Ogni inode utilizzato si riferisce a 1 file. Ogni file ha 1 inode. Directory, file di caratteri e dispositivi a blocchi sono tutti file. Ognuno di essi ha 1 inode.
Per ogni file in una directory, c'è una voce contenente il nome del file e il numero di inode ad esso associato.
Gli inode sono univoci a livello di partizione. Puoi avere due file con lo stesso numero di inode dato che si trovano su partizioni diverse. Le informazioni di Inodes sono archiviate in una struttura simile a una tabella nelle parti strategiche di ogni partizione, spesso trovata vicino all'inizio.
Come controllare l'inode in Linux?
Puoi facilmente elencare il numero di inode con il seguente comando:
ls -iLe immagini seguenti mostrano la mia directory principale con i numeri di inode corrispondenti.
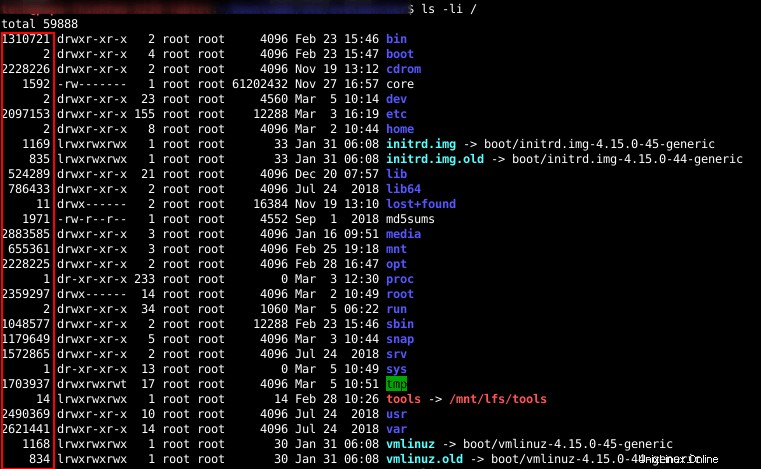
La quantità di inode di ciascun file system viene decisa al momento della creazione del file system. Per la maggior parte degli utenti, il numero predefinito di inode è più che sufficiente.
L'impostazione predefinita durante la creazione di un filesystem creerà 1 inode per 2K byte di spazio. Questo fornisce molti inode per la maggior parte dei sistemi. Molto probabilmente esaurirai lo spazio prima di esaurire gli inode. Se necessario, puoi specificare quanti inode creare durante la creazione di un file system.
Se finisci gli inode, non sarai in grado di creare nuovi file. Anche il tuo sistema non sarà in grado di farlo. Questa non è una situazione che la maggior parte degli utenti incontrerà, ma è possibile.
Ad esempio, un server di posta memorizzerà un'enorme quantità di file molto piccoli. Molti di questi file saranno inferiori a 2K byte. Si prevede inoltre che cresca costantemente. Pertanto un server di posta rischia di esaurire gli inode prima di esaurire lo spazio.
Alcuni file system come Btrfs, JFS, XFS hanno implementato inode dinamici. Possono aumentare il numero di inode disponibili, se necessario.
Come funziona l'inode?
Quando viene creato un nuovo file, gli viene assegnato un numero di inode e un nome file. Un numero inode è un numero univoco all'interno di quel file system. Sia il nome che il numero di inode sono memorizzati come voci in una directory.
Quando ho eseguito il comando ls “ls -li / ” il nome del file e il numero di inode sono ciò che è stato memorizzato nella directory / . Le informazioni rimanenti su utente, gruppo, autorizzazioni file, dimensioni e così via sono state recuperate dalla tabella inode utilizzando il numero di inode.
Puoi elencare le informazioni sugli inode per ciascun file system con il comando df in Linux:
df -hi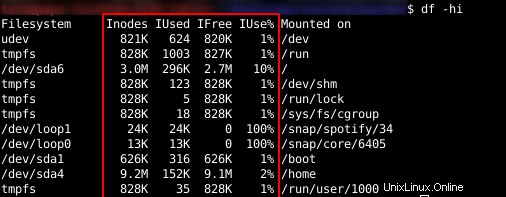
Inode e collegamento Soft/Hard
Un collegamento software o un collegamento simbolico è una caratteristica ben nota di Linux. Ma cosa succede con Inodes quando crei un collegamento simbolico in Linux? Nella prossima immagine ho una directory chiamata “dir1 “, un file denominato “file1 ” e dentro “dir1 ” Ho un collegamento software chiamato “slink1 ” che punta a “../file1 “
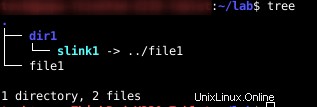
Ora posso elencare ricorsivamente e mostrare le informazioni sull'inode.
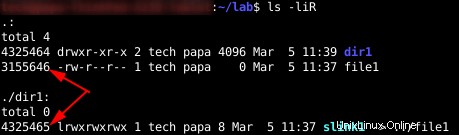
Come previsto, dir1 e file1 hanno numeri di inode diversi. Ma anche il collegamento morbido. Quando crei un collegamento software, crei un nuovo file. Nei suoi metadati, punta al target. Per ogni collegamento software che crei, utilizzi un inode.
Dopo aver creato un hard link in dir1 con il comando ln:
ln ../file1 hlink1L'elenco del numero di inode mi fornisce le seguenti informazioni:
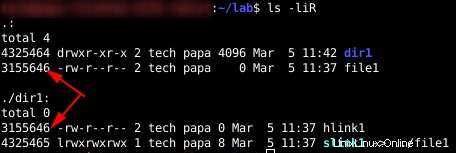
Puoi vedere quel “file1″ e “hlink1 ” hanno lo stesso numero di inode. Sinceramente, gli hard link sono possibili a causa degli inode. Un collegamento reale non crea un nuovo file. Fornisce solo un nuovo nome per gli stessi dati.
Nelle versioni precedenti di Linux, era possibile collegare fisicamente una directory. Era anche possibile avere una determinata directory come genitore di se stessa. Ciò è stato possibile grazie all'implementazione dell'inode. Questo è ora limitato per impedire agli utenti di creare una struttura di directory molto confusa.
Altre implicazioni degli inode
Il modo in cui funzionano gli inode è anche il motivo per cui è impossibile creare un collegamento fisico tra i diversi file system. Consentire un tale compito aprirebbe la possibilità di avere numeri di inode in conflitto. D'altra parte, è possibile creare un collegamento software tra i diversi file system.
Poiché un collegamento fisico ha lo stesso numero di inode del file originale, è possibile eliminare il file originale e i dati sono ancora disponibili tramite il collegamento reale. Tutto ciò che hai fatto, in questo caso, è stato rimuovere uno dei nomi che puntano a questo numero di inode. I dati collegati a questo numero di inode rimarranno disponibili fino a quando tutti i nomi ad esso associati non saranno eliminati.
Gli inode sono anche un grande motivo per cui un sistema Linux può essere aggiornato senza la necessità di riavviare. Questo perché un processo può utilizzare un file di libreria mentre un altro processo sostituisce quel file con una nuova versione. Pertanto, creando un nuovo inode per il nuovo file. Il processo già in esecuzione continuerà a utilizzare il vecchio file mentre ogni nuova chiamata comporterà l'utilizzo della nuova versione.
Un'altra caratteristica interessante che viene fornita con gli inode è la capacità di memorizzare i dati nell'inode stesso. Questo si chiama Inline . Questo metodo di archiviazione ha il vantaggio di risparmiare spazio perché non sarà necessario alcun blocco di dati. Aumenta anche il tempo di ricerca evitando un maggiore accesso al disco per ottenere i dati.
Alcuni file system come ext4 hanno un'opzione chiamata inline_data. Quando abilitato, consente al sistema operativo di archiviare i dati in questo modo. A causa dei limiti di dimensione, l'inline funziona solo per file molto piccoli. Ext2 e versioni successive spesso memorizzano le informazioni sui collegamenti software in questo modo. Cioè se la dimensione non supera i 60 byte.
Conclusione
Gli inode non sono qualcosa con cui interagisci direttamente, ma svolgono un ruolo importante. Se una partizione deve contenere molti file molto piccoli, come un server di posta, sapere cosa sono e come funzionano può farti risparmiare molti problemi lungo la strada.
Spero che questo articolo ti sia piaciuto e che tu abbia imparato qualcosa di nuovo e importante su inode in Linux. Iscriviti al nostro sito Web per ulteriori informazioni relative a Linux.